


Giải pháp Nvidia Triton là gì
Giải pháp Nvidia Triton là một nền tảng phục vụ suy luận AI được thiết kế để triển khai và quản lý các mô hình học máy trong môi trường thực tế.
Đây là một phần của Nvidia AI platform và có sẵn với Nvidia AI Enterprise.
Triton giúp đơn giản hóa việc triển khai các mô hình AI bằng cách cung cấp một giao diện thống nhất và một kiến trúc có khả năng mở rộng.
Đặc điểm nổi bật
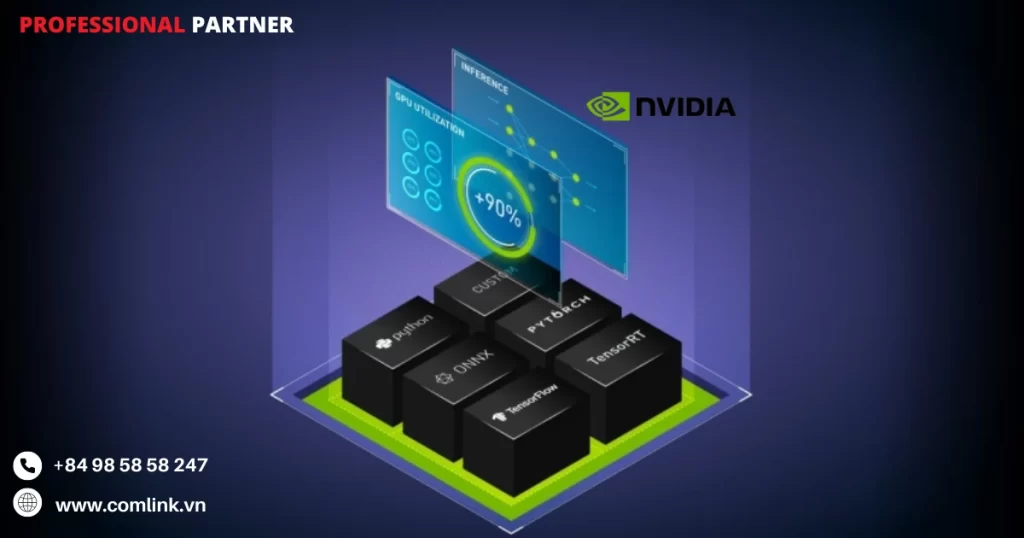
Hỗ trợ tất cả các framework huấn luyện và suy luận
Nvidia Triton™ Inference Server cho phép triển khai các mô hình AI trên bất kỳ framework huấn luyện và suy luận bao gồm TensorFlow, PyTorch, Python, ONNX, NVIDIA® TensorRT™, RAPIDS™ cuML, XGBoost, scikit-learn RandomForest, OpenVINO, custom C++, và nhiều hơn nữa.
Điều này giúp các nhà phát triển và nhà nghiên cứu có thể sử dụng các công cụ và thư viện mà họ đã quen thuộc mà không bị ràng buộc bởi việc phải chuyển đổi giữa các framework khác nhau.
Với khả năng hỗ trợ tất cả các framework phổ biến, Nvidia Triton™ Inference Server mang lại sự linh hoạt cho việc triển khai mô hình AI trong các ứng dụng y tế.
Điều này cho phép các nhà phát triển sử dụng các công cụ và thư viện phù hợp nhất để xây dựng và triển khai các mô hình AI cho hình ảnh y khoa, chẩn đoán và giám sát y tế.
Hiệu suất suy luận cao trên mọi nền tảng
Nvidia Triton™ Inference Server cung cấp khả năng tối ưu hóa hiệu suất suy luận trên mọi nền tảng.
Với tính năng dynamic batching, concurrent execution và cấu hình tối ưu, Triton Inference Server giúp tăng cường hiệu suất và tận dụng tối đa khả năng xử lý của GPU, CPU hoặc bất kỳ bộ xử lý nào khác.
Điều này rất quan trọng trong các ứng dụng y tế, nơi việc suy luận chính xác và nhanh chóng có thể là cách duy nhất để cứu sống mạng người.
Một tính năng đáng chú ý khác của Triton Inference Server là khả năng xử lý luồng âm thanh và video liên tục.
Điều này cho phép nền tảng này được áp dụng rộng rãi trong các ứng dụng y tế như phân loại bệnh từ hình ảnh y khoa hoặc giám sát dữ liệu y tế liên tục.

Mã nguồn mở và thiết kế cho DevOps và MLOps
Nvidia Triton™ Inference Server là một phần của Nvidia AI Enterprise, một nền tảng phần mềm AI an toàn và sẵn sàng cho việc triển khai sản phẩm.
Triton Inference Server được thiết kế để tích hợp vào các giải pháp DevOps và MLOps như Kubernetes để có khả năng mở rộng và Prometheus để theo dõi hiệu suất.
Ngoài ra, Triton cũng có thể được sử dụng trong các nền tảng AI và MLOps trên đám mây hoặc on-premises hàng đầu.
Việc tích hợp Triton Inference Server vào quy trình DevOps và MLOps giúp tạo ra một quá trình triển khai mô hình AI linh hoạt và tự động.
Điều này làm giảm công sức và thời gian cần thiết để triển khai các mô hình AI trong các ứng dụng y tế, từ việc huấn luyện cho đến triển khai sản xuất.
An ninh, quản lý và API ổn định cho các doanh nghiệp
Nvidia AI Enterprise, bao gồm Nvidia Triton™ Inference Server, là một nền tảng phần mềm AI an toàn và sẵn sàng cho sản xuất.
Nền tảng này được thiết kế để giúp gia tăng hiệu quả với sự hỗ trợ, an ninh và API ổn định.
Với sự hỗ trợ từ Nvidia Triton™ Inference Server, doanh nghiệp trong lĩnh vực y tế có thể an tâm về vấn đề bảo mật khi triển khai các mô hình AI trong môi trường sản xuất.
Nền tảng này đã được kiểm tra kỹ lưỡng để đảm bảo tính bảo mật cao và tuân thủ các tiêu chuẩn an ninh.
Ngoài ra, Triton Inference Server cũng cung cấp tính năng quản lý tiện ích, giúp người dùng quản lý và theo dõi quá trình triển khai mô hình AI.
Điều này rất quan trọng trong lĩnh vực y tế, nơi việc theo dõi hiệu suất của các máy móc tự động có thể giúp cải thiện chăm sóc sức khỏe của bệnh nhân.
Hỗ trợ tiêu chuẩn cho các ứng dụng y tế
Nvidia Triton™ Inference Server mang lại sự linh hoạt cho việc triển khai các mô hình AI trong các ứng dụng y tế.
Với khả năng hỗ trợ nhiều framework huấn luyện và suy luận, Triton Inference Server cho phép người dùng sử dụng công cụ và thư viện phù hợp nhất với yêu cầu của từng ứng dụng y tế cụ thể.
Ngoài ra, Triton Inference Server cũng hỗ trợ cấu hình linh hoạt cho việc triển khai trên các nền tảng khác nhau.
Bằng cách tận dụng GPU, CPU hoặc bộ xử lý khác, Triton Inference Server đảm bảo rằng hiệu suất của các ứng dụng y tế sẽ được tối ưu.
Triển khai mô hình AI trong lĩnh vực y tế
Sự phát triển của công nghệ AI đã mang lại nhiều tiềm năng trong lĩnh vực y tế.
Từ công nghệ hình ảnh y khoa cho đến chẩn đoán tự động hay giám sát y khoa liên tục, AI đang ngày càng được áp dụng rộng rãi để cải thiện chăm sóc sức khỏe và chuẩn đoán bệnh.
Với Nvidia Triton™ Inference Server, việc triển khai các mô hình AI trong lĩnh vực y tế trở nên dễ dàng hơn bao giờ hết.
Nhờ vào tính linh hoạt của Triton Inference Server, người dùng có thể triển khai các mô hình AI từ các framework huấn luyện phổ biến như TensorFlow, PyTorch hay ONNX.
Đồng thời, Triton Inference Server cũng cho phép người dùng tận dụng toàn bộ tiềm năng của GPU, CPU hoặc bộ xử lý khác để đạt được hiệu suất cao nhất khi suy luận các mô hình AI trong lĩnh vực y tế.

Lợi ích trong Y tế
Tăng tốc xử lý hình ảnh y khoa
Trong y tế, việc chẩn đoán và phân tích hình ảnh y khoa có thể đòi hỏi nhiều ngày hoặc tuần để hoàn thành.
Tuy nhiên, sử dụng giải pháp các mô hình học máy có thể được triển khai và chạy trên GPU hoặc CPU để tăng tốc quá trình này.
Điều này giúp giảm thời gian chờ đợi cho kết quả chẩn đoán và đồng thời giúp cải thiện hiệu quả công việc của các chuyên gia y tế.
Cải thiện chẩn đoán và giám sát bệnh
Triển khai các mô hình học máy bằng cách sử dụng giải pháp cho phép phân tích chi tiết và chẩn đoán bệnh nhanh chóng và chính xác hơn.
Với việc sử dụng các công cụ phân tích hình ảnh tiên tiến, các bác sĩ có thể dễ dàng nhận ra các biểu hiện bất thường trong hình ảnh y khoa và đưa ra chẩn đoán sớm hơn.
Đồng thời, giải pháp cũng cung cấp khả năng giám sát bệnh thông qua việc theo dõi các chỉ số quan trọng và dự đoán phản ứng của bệnh nhân với liệu pháp.
Nâng cao hiệu suất trong công việc y khoa
Việc triển khai các mô hình học máy trong y tế bằng cách sử dụng giải pháp giúp cải thiện hiệu suất trong công việc y khoa.
Nhờ tính năng dynamic batching, concurrent execution và optimal configuration của Triton Inference Server, các công việc xử lý dữ liệu trong y tế có thể được thực hiện nhanh chóng và hiệu quả hơn.
Điều này giúp giảm thiểu thời gian chờ đợi của bệnh nhân và nâng cao chất lượng dịch vụ y tế.
Tiết kiệm chi phí
Sử dụng giải pháp trong triển khai các mô hình học máy trong y tế có thể giúp tiết kiệm chi phí cho các tổ chức y tế.
Việc sử dụng GPU hoặc CPU hiệu suất cao để triển khai các mô hình có thể giúp tận dụng tối đa nguồn lực hiện có, từ đó giảm thiểu chi phí đầu tư vào phần cứng mới.
Đồng thời, việc triển khai các mô hình AI thông qua giải pháp cũng giúp cải thiện hiệu suất làm việc của nhân viên y tế, từ đó tiết kiệm được chi phí lao động.

Ứng dụng trong hình ảnh y khoa
Phân loại tự động của các loại ung thư
Sử dụng giải pháp, các mô hình học máy có thể được triển khai để tự động phân loại các loại ung thư từ hình ảnh y khoa.
Điều này giúp giảm công sức và thời gian của các chuyên gia y tế trong việc chẩn đoán ung thư, từ đó gia tăng khả năng phát hiện sớm bệnh.
Áp dụng thực tế tăng cường vào hình ảnh y khoa
Giải pháp có thể được sử dụng để triển khai các mô hình học máy để áp dụng thực tế tăng cường vào hình ảnh y khoa.
Việc áp dụng AR (augmented reality) vào việc xem qua hình ảnh y khoa có thể giúp bác sĩ nhìn rõ ràng hơn các chi tiết quan trọng trong bức ảnh và từ đó đưa ra chẩn đoán chính xác.
Phát hiện tự động điểm biến chứng
Các mô hình học máy triển khai thông qua giải pháp có thể được sử dụng để tự động phát hiện điểm biến chứng trong hình ảnh y khoa.
Điều này giúp giám sát bệnh nhân theo thời gian thực và ngăn ngừa hoặc điều trị kịp thời các biến chứng có thể xảy ra.
Hỗ trợ quá trình phẫu thuật
Trong quá trình phẫu thuật, giải pháp có thể được sử dụng để triển khai các mô hình học máy để theo dõi tiến trình phẫu thuật và nhận diện tự động các vùng quan trọng trong khu vực phẫu thuật.
Điều này giúp giám sát tiến trình phẫu thuật và giúp giảm nguy cơ xảy ra sai sót.
Ứng dụng trong chẩn đoán giám sát
Tăng tốc quá trình chẩn đoán
Trong lĩnh vực y tế, chẩn đoán chính xác và nhanh chóng là rất quan trọng.
Nvidia Triton™ giúp tăng tốc quá trình chẩn đoán bằng cách triển khai và chạy các mô hình học máy đã được đào tạo trên các khung công việc như TensorFlow, PyTorch, ONNX, và nhiều khung công việc khác.
Với Triton, các bác sĩ và nhân viên y tế có thể sử dụng các mô hình này để xử lý và phân tích hình ảnh y tế, từ chụp X-quang đến siêu âm và cắt lớp.
Giám sát bệnh
Việc giám sát bệnh là một phần quan trọng của việc chăm sóc sức khỏe.
Với sự phát triển của các thiết bị y tế thông minh, việc triển khai các mô hình học máy để giám sát dữ liệu y tế trở nên ngày càng quan trọng.
Giải pháp cung cấp khả năng triển khai và quản lý các mô hình học máy này trên các thiết bị y tế thông minh, cho phép theo dõi liên tục các thông số sinh tồn, dấu hiệu bệnh, và dữ liệu y tế khác.
Phân tích hình ảnh y tế
Hình ảnh y tế đóng vai trò quan trọng trong việc chẩn đoán và điều trị các bệnh.
Giải pháp cho phép triển khai các mô hình học máy để phân tích hình ảnh y tế từ nhiều nguồn, bao gồm cả X-quang, siêu âm, MRI và CT scan.
Các mô hình này có thể giúp bác sĩ xác định các vấn đề sức khỏe bằng cách phân tích và nhận diện tự động các dấu hiệu bất thường trong hình ảnh y tế.
Điều chỉnh dữ liệu y tế
Nvidia Triton™ giúp quá trình xử lý và điều chỉnh dữ liệu y tế trở nên dễ dàng hơn thông qua việc triển khai các mô hình học máy đã được đào tạo để xử lý dữ liệu này.
Với Triton, dữ liệu y tế có thể được chuẩn hoá, phân loại, và tổ chức một cách tự động, giúp cải thiện hiệu suất và độ chính xác của việc xử lý dữ liệu.
Có thể bạn quan tâm










Liên hệ

Địa chỉ
Tầng 6 184 Phương Liệt
Phường Phương Liệt
Thành phố. Hà Nội


info@comlink.com.vn

Phone
+84 98 58 58 247