


Phương pháp AI phân tích CBCT hiện nay
Sự ra đời của chụp cắt lớp vi tính chùm tia hình nón (Cone Beam Computed Tomography – CBCT) đã tạo ra thay đổi lớn trong lĩnh vực chẩn đoán hình ảnh nha khoa và hàm mặt.
Nó đã cung cấp khả năng quan sát ba chiều (3D) với độ phân giải không gian cao và liều lượng bức xạ thấp hơn đáng kể so với CT y tế truyền thống.
Tuy nhiên, sự gia tăng nhanh chóng về số lượng dữ liệu hình ảnh 3D đã đặt ra những thách thức lớn đối với khả năng phân tích thủ công của các bác sĩ lâm sàng.
Đọc và phân tích hàng trăm lát cắt hình ảnh không chỉ tốn thời gian mà còn dễ dẫn đến sai sót và sự không thống nhất giữa các bác sỹ nên trí tuệ nhân tạo (AI) đã trở thành một công cụ thiết yếu để tự động hóa quy trình làm việc, nâng cao độ chính xác chẩn đoán và hỗ trợ lập kế hoạch điều trị tối ưu.
So sánh kỹ thuật phương pháp AI phân tích CBCT hiện nay tập trung vào hai nhánh chính: học máy truyền thống (Traditional Machine Learning – TML) dựa trên các đặc trưng thủ công và học sâu (Deep Learning – DL) dựa trên mạng nơ-ron tích chập và transformer.
Quá trình so sánh kỹ thuật phương pháp AI phân tích CBCT đòi hỏi sự hiểu biết sâu sắc về toán học, vật lý hình ảnh và các yêu cầu lâm sàng đặc thù của ngành nha khoa.
Học máy truyền thống phân tích CBCT
Kỹ thuật trích xuất đặc trưng kết cấu và hình dạng
Nền tảng của mọi quy trình học máy truyền thống (TML) là quá trình trích xuất đặc trưng, chuyển đổi dữ liệu ảnh thô thành các mô tả có cấu trúc, có thể định lượng để thuật toán xử lý.
Trong phân tích CBCT, bước này đặc biệt quan trọng vì giá trị chẩn đoán của một hình ảnh không nằm ở bề ngoài trực quan mà ẩn trong các mẫu thống kê phân bổ trên từng điểm ảnh (pixel) hoặc điểm thể tích (voxel).
Hai kỹ thuật nổi bật nhất trong lĩnh vực này là Ma trận Đồng xuất hiện Mức xám (GLCM) và Mẫu Nhị phân Cục bộ (LBP).
GLCM phân tích mối quan hệ thống kê bậc hai giữa các cặp điểm ảnh cách nhau một khoảng và hướng xác định.
Thay vì xem xét từng giá trị điểm ảnh riêng lẻ, GLCM mô tả sự sắp xếp không gian của các mức độ xám trên một vùng ảnh.
Đặc tính này đặc biệt có ý nghĩa trong CBCT, nơi gradient mật độ xương và vi cấu trúc bè xương chứa đựng nhiều thông tin chẩn đoán quan trọng.
Từ GLCM, bốn tham số chính được rút ra:
- Energy (Năng lượng): đo lường độ đồng đều kết cấu, phản ánh mức độ phân bổ đều đặn của các giá trị điểm ảnh.
- Contrast (Độ tương phản): ghi lại sự biến đổi mức xám cục bộ, làm nổi bật ranh giới cấu trúc hoặc các bất thường bệnh lý.
- Homogeneity (Độ thuần nhất): phản ánh mức độ phân bổ các phần tử gần với đường chéo chính của ma trận, biểu thị kết cấu mịn, đều đặn.
- Entropy (Entropy): đo độ ngẫu nhiên hoặc phức tạp của mẫu kết cấu giá trị entropy cao thường tương quan với mô không đồng nhất hoặc mô bệnh lý.
Kết hợp lại, bốn chỉ số này tạo nên dữ liệu đa chiều về kết cấu mô, giúp phân biệt xương lành mạnh với tổn thương giai đoạn sớm hoặc các thay đổi loãng xương.
Ví dụ: trong phân tích ảnh CBCT hàm mặt tại các bệnh viện lớn GLCM có thể hỗ trợ phát hiện tình trạng tiêu xương ổ răng trước khi biểu hiện lâm sàng rõ ràng.
LBP bổ sung cho GLCM ở cấp độ cục bộ hơn.
Với mỗi điểm ảnh, LBP so sánh cường độ của nó với tám điểm ảnh lân cận xung quanh, tạo ra một mã nhị phân mã hóa vi cấu trúc tại chỗ.
Kỹ thuật này đặc biệt hữu ích trong phân tích CBCT nha khoa vì nó nắm bắt được những biến đổi tinh tế trên bề mặt vỏ xương hoặc men răng mà không bị ảnh hưởng bởi sự thay đổi độ sáng tổng thể, một dạng nhiễu phổ biến trong ảnh X-quang.
Kết quả thu được bộ mô tả bất biến với phép quay, hiệu quả về mặt tính toán, vượt trội trong phát hiện các thay đổi vi kết cấu dấu hiệu của bệnh lý sớm, viêm nha chu hoặc các dạng tiêu chân răng mà mắt thường khó nhận ra.
Các thuật toán phân loại phổ biến
Sau khi xây dựng được bộ đặc trưng phong phú, bước tiếp theo là huấn luyện các thuật toán phân loại có khả năng ánh xạ các mô tả toán học đó vào các nhóm chẩn đoán có ý nghĩa.
Ba thuật toán được ứng dụng phổ biến nhất trong quy trình TML dựa trên CBCT gồm:
Máy vectơ hỗ trợ (SVM) hoạt động bằng cách xác định một siêu phẳng tối ưu.
Đó là ranh giới quyết định trong không gian đặc trưng nhiều chiều nhằm phân tách tối đa hai hoặc nhiều nhóm dữ liệu.
Trong các bài toán chẩn đoán nhị phân như phân biệt tổn thương và không tổn thương, SVM thể hiện hiệu suất vượt trội ngay cả khi tập huấn luyện có kích thước nhỏ.
Điều này đặc biệt quan trọng trong bối cảnh nghiên cứu lâm sàng, nơi các bộ dữ liệu CBCT được chú thích thường rất khan hiếm.
Khả năng xử lý vectơ đặc trưng nhiều chiều mà không bị overfitting khiến SVM trở thành lựa chọn ưu tiên để phát hiện tổn thương vùng quanh chóp, cấu trúc nang hoặc các dạng mất xương từ các bộ mô tả GLCM và LBP.
Rừng ngẫu nhiên (Random Forest) theo đuổi hướng tiếp cận học tập tổ hợp.
Nó xây dựng nhiều cây quyết định trên các tập con ngẫu nhiên của dữ liệu huấn luyện.
Sau đó tổng hợp kết quả để tạo ra dự đoán tổng quát hơn và ổn định hơn.
Phương pháp này đặc biệt phù hợp với các bài toán phân loại đa lớp và thách thức phân vùng cấp pixel trong CBCT như xác định đồng thời nhiều cấu trúc giải phẫu hoặc phân cấp mức độ tiêu xương ổ răng trên một thang liên tục.
Ngoài ra, RF còn tích hợp sẵn khả năng xếp hạng tầm quan trọng đặc trưng, cung cấp cho bác sĩ lâm sàng cái nhìn về những thuộc tính kết cấu hoặc hình thái nào có giá trị chẩn đoán cao nhất.
Đây là một lớp khả năng diễn giải bổ sung, hỗ trợ thực hành dựa trên bằng chứng.
K-Láng giềng gần nhất (k-NN) phân loại các điểm dữ liệu mới bằng cách tính khoảng cách đến các mẫu huấn luyện đã có nhãn trong không gian đặc trưng và gán nhãn theo lớp chiếm đa số trong số k láng giềng gần nhất.
Tuy đơn giản về mặt tính toán, k-NN hoạt động đáng tin cậy trong các môi trường đặc trưng có cấu trúc rõ ràng và thường được dùng làm bộ phân loại cơ sở hoặc trong các khung lai ghép.
Do đó sự đơn giản của nó tạo điều kiện thử nghiệm nhanh và so sánh với các mô hình phức tạp hơn.
Ưu điểm và hạn chế của TML
Sức sống lâu bền của TML trong nghiên cứu ảnh y tế lâm sàng xuất phát phần lớn từ tính có thể diễn giải một phẩm chất ngày càng được coi trọng khi các khung pháp lý về AI trong y tế đòi hỏi tính minh bạch và khả năng giải thích.
Khác với các hệ thống học sâu vận hành như những “hộp đen” không thể nhìn thấu, mô hình TML làm việc với các đặc trưng được định nghĩa toán học có thể liên kết trực tiếp với các hiện tượng sinh học quan sát được.
Ví dụ: một bác sĩ có thể truy ngược điểm entropy cao bất thường về một vùng cụ thể có mật độ bè xương không đều và đối chiếu với kết quả mô bệnh học.
Do đó củng cố niềm tin lâm sàng và hỗ trợ ra quyết định đa chuyên khoa.
Hơn nữa, TML thích nghi tốt với điều kiện khan hiếm dữ liệu vốn là đặc trưng của nghiên cứu lâm sàng chuyên sâu.
Nhiều nghiên cứu CBCT chỉ có bộ dữ liệu dưới 100 đến 500 mẫu đã chú thích, khiến yêu cầu huấn luyện đòi hỏi dữ liệu lớn của học sâu trở nên bất khả thi.
Ngược lại, các thuật toán TML vẫn đạt hiệu suất có ý nghĩa thống kê trong môi trường hạn chế này mà không cần hạ tầng GPU đắt tiền hay quy trình tính toán phức tạp.
Đây là lợi thế đáng kể với các cơ sở y tế tại Việt Nam đang ở giai đoạn đầu triển khai AI chẩn đoán hình ảnh.
Tuy nhiên, hạn chế lớn nhất của TML là bị phụ thuộc vào kỹ thuật thiết kế đặc trưng do chuyên gia định nghĩa.
Chất lượng mô hình bị ràng buộc căn bản bởi những đặc trưng mà chuyên gia lĩnh vực lựa chọn định nghĩa và trích xuất.
Nếu một đặc điểm có liên quan lâm sàng như một phản ứng màng xương tinh tế hoặc một dạng vi gãy xương không được đưa vào bộ đặc trưng ban đầu, thuật toán không có cơ chế nào để tự phát hiện ra nó.
Quá trình thiết kế thủ công vừa tạo ra những điểm mù tiềm ẩn vừa đòi hỏi đầu tư thời gian đáng kể trong giai đoạn phát triển.
Phần mềm AI nha khoa AICITI – Phân tích CBCT tự động
Xem chi tiết tính năng, lợi ích và hiệu quả thực tế mà bộ phần mềm AICITI mang lại cho bác sĩ nha khoa: phân tích xương hàm, răng và mô mềm tự động từ dữ liệu CBCT – rút ngắn thời gian chẩn đoán từ 30 phút xuống còn vài phút.
Xem chi tiết AICITI →
Học sâu phân tích CBCT
Kiến trúc mạng Nơ-ron tích chập (CNN)
Trong hầu hết các lĩnh vực chẩn đoán hình ảnh y tế hiện đại, CNN đóng vai trò là “bộ não” phân tích mặc định và X-quang nha khoa cũng không ngoại lệ.
Thách thức cốt lõi trong phân tích CBCT là trích xuất các đặc trưng không gian có giá trị lâm sàng từ dữ liệu thể tích cực kỳ phức tạp và CNN được tối ưu hóa về mặt kiến trúc để xử lý chính xác nhiệm vụ này.
Về nguyên lý hoạt động, CNN sử dụng các bộ lọc có thể học được gọi là kernel.
Nó trượt tuần tự trên ảnh theo kiểu cửa sổ trượt nhằm nhận diện các mẫu không gian cục bộ như cạnh viền, kết cấu bề mặt và ranh giới giải phẫu.
Các lớp tích chập này được xếp chồng lên nhau xen kẽ với hàm kích hoạt ReLU (Rectified Linear Unit) giúp đưa tính phi tuyến vào mô hình để mô phỏng những cấu trúc sinh học phức tạp cùng với các lớp gộp (pooling).
Vì vậy giúp giảm dần độ phân giải không gian trong khi mở rộng trường nhìn hiệu dụng của mạng.
Kết quả là một pipeline trích xuất đặc trưng phân cấp, học cách nhận diện các biểu diễn ngày càng trừu tượng hơn.
Từ gradient cấp độ pixel ở các lớp đầu đến hình thái răng và mật độ xương ở các lớp sâu hơn.
Riêng với phân tích CBCT ba chiều, các kiến trúc như 3D U-Net và V-Net đã trở thành tiêu chuẩn vàng cho các bài toán phân đoạn ảnh.
Cấu trúc đặc trưng của U-Net gồm hai nhánh đối xứng:
- Bộ mã hóa (encoder – nhánh thu hẹp) thực hiện giảm mẫu dần dần để nắm bắt các đặc trưng ngữ cảnh cấp cao.
- Bộ giải mã (decoder – nhánh mở rộng) phục hồi độ phân giải không gian bằng cách kết hợp thông tin ngữ cảnh với chi tiết tinh tế từ các lớp mã hóa tương ứng thông qua skip connections.
Thiết kế khéo léo này đảm bảo thông tin ranh giới chính xác không bao giờ bị mất vĩnh viễn trong quá trình giảm mẫu.
Đây là yêu cầu then chốt khi cần xác định các cấu trúc mảnh như khoang dây chằng nha chu hay ống thần kinh xương ổ dưới.
Trong thực tế lâm sàng, các biến thể U-Net được huấn luyện trên dữ liệu CBCT đã chứng minh khả năng phân đoạn tự động đáng tin cậy đối với răng, ống thần kinh hàm dưới và xoang hàm trên.
Do đó giúp giảm đáng kể gánh nặng chú thích thủ công cho các bác sĩ.
Ví dụ: Tại bệnh viện, phân đoạn thủ công một ca CBCT toàn hàm có thể mất 1–2 giờ. Với U-Net, quy trình này được rút ngắn xuống còn vài phút, giúp bác sĩ tập trung vào đánh giá lâm sàng thay vì công việc đánh dấu tốn thời gian.
Kiến trúc mạng Transformer trong hình ảnh y tế
Dù CNN xuất sắc trong việc trích xuất đặc trưng cục bộ, hạn chế căn bản của kiến trúc này nằm ở khái niệm trường tiếp nhận cục bộ (local receptive field) vì mỗi bộ lọc tích chập chỉ xử lý thông tin trong một vùng lân cận không gian hạn chế.
Với những bài toán đòi hỏi hiểu mối quan hệ giữa các cấu trúc giải phẫu cách xa nhau, hạn chế này có thể ảnh hưởng đáng kể đến độ chính xác lâm sàng.
Sự xuất hiện của các kiến trúc dựa trên Transformer vốn được phát triển ban đầu cho xử lý ngôn ngữ tự nhiên đã mang đến một cách tiếp cận hoàn toàn khác biệt trong suy luận không gian của chẩn đoán hình ảnh y tế.
Các mô hình như Swin-Unet, TransUNet và Swin UNETR tận dụng cơ chế tự chú ý (self-attention).
Vì vậy giúp mô hình đánh giá đồng thời mối quan hệ giữa mọi vùng trong toàn bộ khối ảnh, bất kể khoảng cách không gian.
Về mặt toán học, self-attention tính toán điểm liên quan có trọng số giữa tất cả các cặp vị trí trong chuỗi dữ liệu hay trong trường hợp này là tất cả các patch không gian trong khối CBCT 3D.
Từ đó nắm bắt được các phụ thuộc tầm xa mà CNN về mặt cấu trúc không thể mô hình hóa trong một lần xử lý duy nhất.
Khả năng này đặc biệt có giá trị trong các tình huống chẩn đoán nha khoa phức tạp.
Ví dụ: đánh giá răng khôn mọc lệch, lập kế hoạch phẫu thuật chính xác đòi hỏi phải hiểu đồng thời vị trí của răng khôn, hướng đi của dây thần kinh xương ổ dưới và khoảng cách đến xoang hàm trên.
Đây là những cấu trúc có thể phân tán trên một phần lớn thể tích ảnh.
CNN với trường tiếp nhận hạn chế khó nắm bắt toàn diện các phụ thuộc đa cấu trúc này nhưng Transformer có thể mô hình hóa tường minh các tương quan không gian đó.
Hơn nữa, kiến trúc Transformer thể hiện hiệu suất mạnh mẽ trong phát hiện các thay đổi bệnh lý tinh tế trải rộng trên nhiều vùng giải phẫu như tổn thương quanh chóp răng giai đoạn sớm có ảnh hưởng đến cấu trúc xương xung quanh.
Ví dụ: Bác sĩ phẫu thuật hàm mặt đang lập kế hoạch nhổ răng khôn hàm dưới cho bệnh nhân.
Thay vì phải dò từng lát cắt CBCT để xác định vị trí ống thần kinh, công việc đòi hỏi kinh nghiệm và dễ bỏ sót thì hệ thống Transformer có thể “nhìn” toàn bộ hàm trong một lần.
Nó tự động cảnh báo khi chân răng nằm cách ống thần kinh dưới 2mm, giúp giảm thiểu rủi ro tê liệt thần kinh sau phẫu thuật.
So sánh CNN và Transformer trong phân đoạn 3D
| Chỉ số kỹ thuật | U-Net (CNN) | Swin UNETR (Transformer) |
|---|---|---|
| Số lượng tham số | ~31 triệu | ~62 triệu |
| Phân bổ tham số | Cân bằng giữa Encoder/Decoder | >85% tập trung ở Decoder |
| Tốc độ suy luận | Nhanh hơn (~3 lần) | Chậm hơn |
| Yêu cầu GPU | Thấp hơn | Cao hơn nhiều |
| Độ chính xác (DSC) | ~0.991 (2D), ~0.911 (3D) | ~0.900 (có thể thấp hơn 1% so với U-Net tối ưu) |
| Sự hội tụ | Nhanh và ổn định | Chậm và nhạy cảm với dữ liệu |
Gói dịch vụ & Bảng giá phần mềm AI nha khoa AICITI
Tìm hiểu chi tiết các gói dịch vụ AICITI, AImodel và Aisoft phù hợp với quy mô phòng khám của bạn – từ phòng khám đơn lẻ đến chuỗi nha khoa. Bao gồm bảng giá, chính sách dùng thử và hỗ trợ triển khai tại Việt Nam.
Xem gói dịch vụ & bảng giá →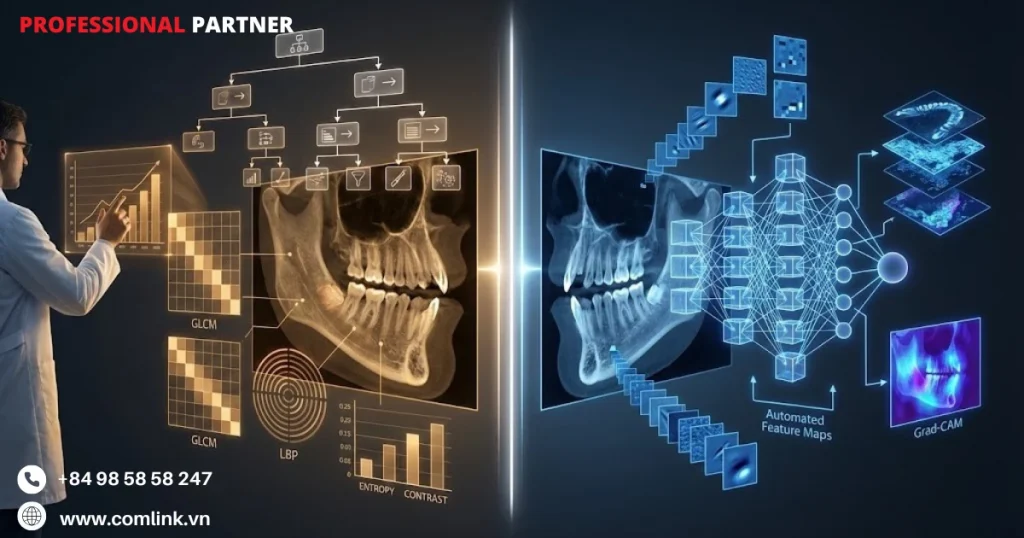
So sánh học sâu và học máy
| Đặc điểm so sánh | Học máy truyền thống (TML) | Học sâu (DL) |
|---|---|---|
| Dữ liệu đầu vào | Đặc trưng được chọn lọc (Handcrafted features) | Hình ảnh thô (Raw pixels/voxels) |
| Quy trình xử lý | Trích xuất đặc trưng → Phân loại | Tự động học đặc trưng và phân loại đồng thời |
| Lượng dữ liệu cần thiết | Thấp đến trung bình (vài chục đến vài trăm) | Rất lớn (hàng nghìn mẫu gán nhãn) |
| Tính diễn giải | Cao (dễ hiểu cơ sở quyết định) | Thấp (mô hình “hộp đen”) |
| Yêu cầu phần cứng | Thấp (chạy được trên CPU) | Cao (đòi hỏi GPU chuyên dụng) |
| Độ chính xác | Thường thấp hơn trong các tác vụ phức tạp | Vượt trội trong phân đoạn và phát hiện |

Ứng dụng trong phân đoạn cấu trúc giải phẫu
Phân đoạn răng
Trong chụp cắt lớp vi tính chùm tia hình nón (CBCT) nha khoa, một trong những trở ngại dai dẳng nhất ảnh hưởng đến độ chính xác của phân đoạn răng là sự tương đồng đáng kể về giá trị cường độ xám giữa các mô có cấu trúc hoàn toàn khác nhau.
Men răng, ngà răng và xương ổ răng xung quanh đều có dải đơn vị Hounsfield (HU) chồng chéo nhau.
Do đó các thuật toán thông thường thực sự khó xác định ranh giới giữa các cấu trúc này.
Thách thức càng trở nên phức tạp hơn tại vùng đường nối men-xê măng (CEJ) và chóp chân răng nơi ranh giới mô bị mờ đi đáng kể và gần như không thể giải quyết khi các phục hồi kim loại tạo ra hiện tượng giải cứng chùm tia (beam-hardening artifacts), làm phân tán giá trị cường độ xám trên toàn bộ hình ảnh.
Các phương pháp truyền thống như phân đoạn theo ngưỡng và phương pháp Level Set (LSM) chủ yếu dựa vào gradient cường độ pixel.
Dù hiệu quả trong môi trường có độ tương phản cao, những phương pháp này về bản chất là “mù” về mặt ngữ cảnh nên chúng không thể phân biệt mối quan hệ không gian hay các đặc điểm hình thái tinh vi mà bác sỹ dễ dàng nhận ra bằng trực giác.
Trong các tình huống lâm sàng phức tạp như răng mọc chen chúc, biến thể giải phẫu bất thường hay nhiễu từ kim loại, những phương pháp này thường tạo ra lỗi phân đoạn đủ lớn để ảnh hưởng nghiêm trọng đến độ chính xác của kế hoạch điều trị.
Các kiến trúc học sâu, đặc biệt là nnU-Net, một framework tự cấu hình, tự động điều chỉnh tiền xử lý, kiến trúc và quá trình huấn luyện theo từng bộ dữ liệu cụ thể khắc phục hạn chế này bằng cách học các đặc trưng hình thái theo tầng bậc thay vì chỉ dựa vào giá trị cường độ xám.
Sự khác biệt then chốt ở đây rất rõ ràng, thay vì đặt câu hỏi “voxel này sáng đến mức nào?”, nnU-Net đặt câu hỏi “voxel này thuộc về cấu trúc giải phẫu nào?”.
Ví dụ: khi phân đoạn răng khôn mọc lệch, nnU-Net vẫn xác định được ranh giới chân răng dù bị xương hàm che khuất một phần, trong khi LSM thường “mất dấu” cấu trúc tại đây.
Kết quả hiệu suất xác nhận rõ ưu thế của phương pháp này.
Các nghiên cứu ghi nhận chỉ số Dice Similarity Coefficient (DSC) đạt 0,93–0,94, phản ánh mức độ trùng khớp thể tích gần như hoàn hảo giữa phân đoạn do AI tạo ra và kết quả chuẩn.
Chỉ số Intersection over Union (IoU) đạt 0,87–0,88 tiếp tục khẳng định độ chính xác ranh giới mạnh mẽ trong phân đoạn toàn cung hàm.
Đặc biệt có ý nghĩa lâm sàng nhất là chỉ số Surface Deviation chỉ 7,85–9,96 μm, thấp hơn nhiều so với ngưỡng sai số lâm sàng chấp nhận được.
Điều này có nghĩa là ranh giới phân đoạn của AI đủ chính xác để trực tiếp hỗ trợ thiết kế phục hình, định vị bracket chỉnh nha và chế tạo máng phẫu thuật mà không cần hiệu chỉnh thủ công.
Phân đoạn ống thần kinh răng dưới
Ống răng dưới (IAC — Inferior Alveolar Canal) đặt ra một thách thức phân đoạn hoàn toàn khác biệt.
Đó không phải do sự tương đồng mô mà do đặc điểm hình ảnh X-quang vốn rất mờ nhạt.
Cấu trúc hình ống hẹp dẫn dây thần kinh răng dưới và mạch máu đi xuyên qua xương hàm dưới, khiến xác định vị trí chính xác trở thành yêu cầu không thể thiếu để đặt implant an toàn tại vùng răng hàm lớn.
Nhận diện sai vị trí IAC chỉ vài milimet cũng có thể gây tổn thương mạch thần kinh.
Đó là chứng dị cảm (paresthesia) hoặc trong trường hợp nặng là tê liệt môi vĩnh viễn, một hậu quả nghiêm trọng cả về lâm sàng lẫn pháp lý y tế.
Khó khăn kỹ thuật xuất phát từ vỏ xương bao quanh ống thường không liên tục và độ tương phản thấp so với xương xốp xung quanh.
Ở nhiều bệnh nhân, một phần ranh giới IAC đơn giản là vô hình trên ảnh tái tạo CBCT tiêu chuẩn.
Do đó tạo ra các khoảng trống gây nhầm lẫn cho cả người đọc phim lẫn thuật toán.
Tại các bệnh viện lớn, bác sĩ thường phải dành nhiều thời gian đánh dấu thủ công IAC trước khi lên kế hoạch phẫu thuật, quy trình tốn công sức và vẫn có nguy cơ sai sót.
Các mô hình AI thông thường được huấn luyện chủ yếu trên các cấu trúc tương phản cao sẽ hoạt động kém trong điều kiện này.
Chúng tạo ra các dấu vết ống không liên tục hoặc sai lệch giải phẫu, đòi hỏi hiệu chỉnh thủ công tốn kém trước khi sử dụng trên lâm sàng.
Các kiến trúc tiên tiến như ResU-Net biến thể học phần dư (residual learning) của framework U-Net.
Vì thế bảo toàn chi tiết không gian tinh tế thông qua các kết nối skip cùng với các pipeline hai giai đoạn kết hợp phân đoạn ban đầu và tinh chỉnh hậu xử lý chuyên biệt, đã cho thấy hiệu suất cải thiện đáng kể.
Các mô hình này đạt dải DSC 0,69–0,77, tuy thấp hơn so với chuẩn phân đoạn răng nhưng đường kính mặt cắt ngang nhỏ của IAC khiến ngay cả sai lệch tuyệt đối nhỏ cũng làm giảm điểm Dice một cách không tương xứng.
Xét về độ chính xác hình thái, ranh giới mà các mô hình này đạt được là đủ về mặt lâm sàng để hỗ trợ lập kế hoạch phẫu thuật an toàn.
Đó là xác định đáng tin cậy hướng đi của ống, tính toán vùng an toàn cho độ sâu implant và gắn cờ các trường hợp tiếp cận nguy hiểm cao để chuyển bác sĩ chuyên khoa xem xét.
Giảm nhiễu và nâng cao chất lượng ảnh CBCT
So sánh tái cấu trúc lặp (IR) và học sâu (DL)
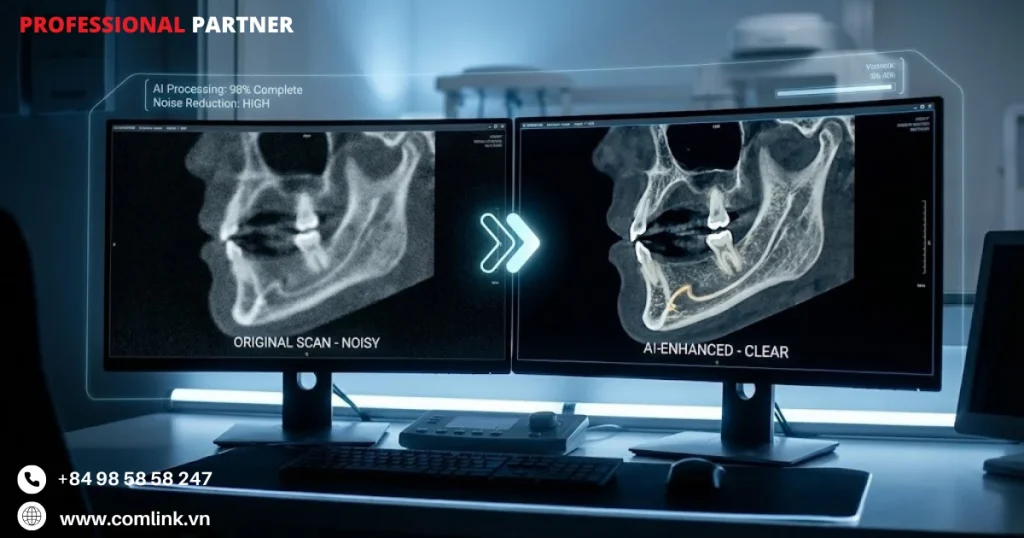
Trong nhiều thập kỷ, các thuật toán tái tạo lặp (Iterative Reconstruction – IR) được xem là tiêu chuẩn vàng để giảm nhiễu trong ảnh CBCT.
Nguyên lý hoạt động của các thuật toán này dựa trên so sánh liên tục giữa dữ liệu chiếu dự đoán và dữ liệu thực tế đo được, từng bước thu hẹp sai lệch thông qua tối ưu hóa toán học.
Dù IR xử lý hiệu quả nhiễu ngẫu nhiên đặc biệt là nhiễu lượng tử phát sinh khi số lượng photon thấp nhưng phương pháp này vẫn tồn tại hai hạn chế lớn.
Chi phí tính toán của các vòng lặp khá nặng nề, dẫn đến thời gian tái tạo ảnh kéo dài và ảnh hưởng đến quy trình làm việc lâm sàng.
Hơn nữa khi đẩy mạnh xử lý IR, các chi tiết kết cấu mịn thường bị làm nhòa, khiến hoa văn xương bè và tổn thương quanh chóp răng mờ đi, trong khi đây chính là những đặc điểm không thể thiếu khi chẩn đoán răng hàm mặt.
Học sâu cụ thể là kiến trúc mạng nơ-ron tích chập (Convolutional Neural Network – CNN) giải quyết cả hai hạn chế trên theo một cơ chế hoàn toàn khác.
Thay vì lặp đi lặp lại quá trình tối ưu hóa một mô hình vật lý, CNN học trực tiếp đặc điểm nhiễu và kết cấu mô từ tập dữ liệu lớn gồm các cặp ảnh chất lượng thấp và chất lượng cao.
Hệ thống như ClariCT.AI là minh chứng điển hình cho hướng tiếp cận này, với kết quả đánh giá lâm sàng có kiểm soát cho thấy hiệu suất vượt trội so với phương pháp truyền thống.
Về mặt định lượng, khử nhiễu bằng CNN đạt mức cải thiện tỷ lệ tương phản trên nhiễu (CNR) từ 17% đến 30% so với tái tạo tiêu chuẩn.
Đây là một bước tiến thực chất, phản ánh trực tiếp vào độ tự tin chẩn đoán khi cần phân biệt sự khác biệt mật độ tinh tế giữa mô lành và mô bệnh.
Lợi ích thực tiễn quan trọng nhất có lẽ là khả năng giảm liều bức xạ.
Vì mô hình học sâu vẫn duy trì chất lượng ảnh chẩn đoán tương đương từ các ảnh thu nhận nhiễu hơn ở liều thấp hơn, quy trình lâm sàng có thể cắt giảm lượng tia X lên đến 70% mà không làm suy giảm giá trị chẩn đoán.
Điều này hoàn toàn phù hợp với nguyên tắc nền tảng của y học hình ảnh: ALARA (As Low As Reasonably Achievable — Liều thấp nhất có thể chấp nhận được).
Do đó khẳng định hình ảnh tăng cường bằng AI không chỉ là công cụ nâng cao chất lượng mà còn là bước tiến về an toàn bệnh nhân.
Với trẻ em hoặc bệnh nhân cần chụp định kỳ nhiều lần, lợi ích giảm liều này mang ý nghĩa lâm sàng vô cùng to lớn.
Ví dụ: Tại một số bệnh viện nhi khi cần chụp CBCT đánh giá dị tật hàm mặt bẩm sinh, việc giảm liều bức xạ tới 70% nhờ học sâu sẽ giúp hạn chế đáng kể rủi ro phơi nhiễu phóng xạ tích lũy trong suốt quá trình điều trị kéo dài nhiều năm của trẻ.
Giảm nhiễu sọc do kim loại (MAR)
Các vật thể kim loại implant nha khoa, mão răng, khí cụ chỉnh nha hay phần cứng phẫu thuật tạo ra thách thức kỹ thuật đặc thù và phức tạp trong chụp ảnh CBCT.
Khi chùm tia X xuyên qua các vật liệu kim loại có mật độ cao, chúng chịu hiện tượng bão hòa photon (photon starvation), cứng hóa chùm tia (beam hardening) và tán xạ (scatter).
Từ đó tạo ra các khoảng trống dữ liệu trong sinogram thô (không gian toán học biểu diễn dữ liệu chiếu trước khi tái tạo ảnh).
Hậu quả là các ảnh tạo thành xuất hiện những vệt sáng và tối tỏa ra từ vùng kim loại, che khuất giải phẫu lân cận và thường làm cho kết quả đọc phim trở nên không đáng tin cậy.
AI đã đưa ra ba chiến lược ngày càng tinh vi, mỗi chiến lược khai thác một miền xử lý khác nhau để giải quyết bài toán này.
Xử lý trong miền ảnh (Image Domain)
Đây là hướng tiếp cận khái niệm trực quan nhất.
Mạng nơ-ron được huấn luyện để nhận diện và triệt tiêu các vệt nhiễu trực tiếp trên ảnh 2D hoặc 3D đã được tái tạo.
Mạng học cách “vẽ lại” các vùng bị hỏng bằng cách suy luận ra cấu trúc giải phẫu bên dưới dựa trên ngữ cảnh cấu trúc xung quanh.
Ưu điểm của phương pháp này là không cần truy cập dữ liệu thô từ máy chụp, nên tương thích hoàn toàn với quy trình CBCT lâm sàng tiêu chuẩn.
Tuy nhiên, hạn chế cố hữu là nó không thể phục hồi thông tin chưa bao giờ được ghi lại.
Các vệt nhiễu do thiếu dữ liệu thực sự không thể được khôi phục xác thực; mạng chỉ có thể xấp xỉ giải phẫu bị mất, đưa vào một mức độ nội suy tổng hợp nhất định.
Ví dụ: Bệnh nhân mang cầu răng sứ-kim loại bốn đơn vị được chụp CBCT tại phòng khám nha khoa. Ảnh tái tạo ban đầu xuất hiện nhiều vệt trắng tỏa ra từ các khớp nối kim loại, che khuất xương ổ răng bên dưới.
Phương pháp Image Domain MAR có thể triệt tiêu phần lớn các vệt này trong vài giây mà không cần phần mềm chuyên biệt tích hợp sâu với máy chụp.
Xử lý trong miền Sinogram (Sinogram Domain)
Phương pháp này can thiệp ngược dòng trước bước tái tạo.
Nó tác động trực tiếp vào dữ liệu chiếu thô nơi các khoảng trống do kim loại gây ra lần đầu tiên xuất hiện.
Các thuật toán AI nội suy các giá trị sinogram bị thiếu hoặc bị hỏng trước khi tái tạo ảnh, giúp quá trình xử lý tiếp theo làm việc từ một tập dữ liệu đầy đủ hơn.
Hướng tiếp cận này bảo toàn cấu trúc giải phẫu thực tốt hơn vì các hiệu chỉnh được thực hiện ở cấp độ thu thập dữ liệu chứ không phải áp đặt hậu kỳ lên ảnh đã suy giảm chất lượng.
Tuy nhiên, xử lý trong miền sinogram đòi hỏi quyền truy cập trực tiếp vào dữ liệu thô của máy chụp.
Đây là một luồng dữ liệu không phải lúc nào cũng có thể tiếp cận qua tích hợp phần mềm bên thứ ba và đòi hỏi sự hợp tác chặt chẽ hơn với nhà sản xuất thiết bị.
Khung hai miền (Dual-Domain)
Đây là trạng thái nghệ thuật hiện tại, kết hợp xử lý cả miền sinogram lẫn miền ảnh trong một kiến trúc thống nhất được liên kết bằng các vòng phản hồi.
Mô hình đồng thời tối ưu hóa triệt tiêu nhiễu ở cả hai miền để các hiệu chỉnh trong không gian này thông báo và tinh chỉnh các hiệu chỉnh trong không gian kia.
Sự tinh chỉnh liên miền lặp này tạo ra độ trung thực ảnh cao nhất có thể đạt được, đặc biệt với các hình học kim loại phức tạp như nhiều implant nằm kề nhau.
Tuy nhiên mạng hai miền đòi hỏi tài nguyên GPU đáng kể cho cả huấn luyện lẫn suy luận, nên hiện tại phương pháp này chủ yếu nằm trong môi trường nghiên cứu và các cơ sở lâm sàng cao cấp.
Khi chi phí phần cứng giảm và tối ưu hóa mô hình được cải thiện, MAR hai miền dự kiến sẽ trở thành tiêu chuẩn lâm sàng phổ biến trong những năm tới.
Ví dụ: Tại các trung tâm cấy ghép implant cao cấp, khi bệnh nhân mang từ 4–6 implant trên cùng một hàm, ảnh CBCT thông thường gần như không thể đọc được vùng xương giữa các trụ implant.
Hệ thống MAR hai miền trong tương lai gần sẽ tái tạo lại toàn bộ cấu trúc này với độ trung thực đủ cao để đánh giá tình trạng tích hợp xương quanh implant một cách đáng tin cậy.
Có thể bạn quan tâm








Liên hệ

Địa chỉ
Tầng 3 Toà nhà VNCC
243A Đê La Thành Str
Q. Đống Đa-TP. Hà Nội


info@comlink.com.vn

Phone
+84 98 58 58 247