


Confluent Kafka là gì
Confluent Kafka là nền tảng streaming dữ liệu toàn diện, thiết kế cho yêu cầu cấp doanh nghiệp và được xây dựng dựa trên mã nguồn mở Apache Kafka.
Confluent Kafka là một bản phân phối của Apache Kafka, được đóng gói cùng với một loạt các công cụ, tính năng và dịch vụ bổ sung, bao gồm cả các công cụ mã nguồn mở được phát triển bởi Confluent và các tính năng thương mại độc quyền, nhằm mục đích nâng cao trải nghiệm Kafka cho người dùng doanh nghiệp.
Mục tiêu của nền tảng này là đơn giản hóa kết nối các nguồn dữ liệu đa dạng vào Kafka, xây dựng các ứng dụng streaming phức tạp để xử lý dữ liệu theo thời gian thực, cũng như đảm bảo an ninh, giám sát hiệu suất và quản lý hiệu quả toàn bộ cơ sở hạ tầng Kafka.
Lợi ích của Confluent Kafka
Tích hợp toàn diện
Confluent Kafka không chỉ đơn thuần cung cấp các Kafka broker.
Nó mang đến một nền tảng streaming dữ liệu tích hợp toàn diện bao gồm bộ công cụ và dịch vụ được thiết kế để đơn giản hóa và nâng cao toàn bộ vòng đời streaming dữ liệu.
Nền tảng này tạo ra kết nối liền mạch với nhiều nguồn dữ liệu khác nhau, giúp doanh nghiệp thu thập dữ liệu một cách dễ dàng.
Không chỉ dừng lại ở thu thập, nó còn hỗ trợ xử lý luồng dữ liệu thời gian thực.
Vì thế tạo điều kiện để sinh ra thông tin chi tiết tức thì và đưa ra quyết định nhanh chóng.
Điều thực sự ấn tượng của lợi ích này là khả năng quản lý và điều hành dữ liệu hiệu quả được tích hợp sẵn trong nền tảng.
Từ quản lý schema đến các chính sách bảo mật, Confluent đảm bảo dữ liệu chạy một cách mượt mà, đáng tin cậy và đồng thời đáp ứng các yêu cầu tuân thủ quy định.
Tính chất toàn diện nên doanh nghiệp không cần phải kết hợp nhiều công cụ từ các nhà cung cấp khác nhau.
Thay vào đó, họ nhận được một giải pháp thống nhất được thiết kế để hoạt động hài hòa, giảm thiểu độ phức tạp và đẩy nhanh chu kỳ phát triển.
Ví dụ: Một ngân hàng có thể sử dụng nền tảng này để tích hợp dữ liệu từ hệ thống core banking, ứng dụng mobile banking, và các kênh thanh toán khác nhau. Tất cả trong một hệ thống duy nhất, thay vì phải duy trì 3-4 hệ thống riêng biệt.
Tiêu chuẩn cấp doanh nghiệp
Một trong những ưu điểm quan trọng nhất của Confluent Kafka là khả năng đáp ứng yêu cầu của doanh nghiệp.
Doanh nghiệp lớn thường đối mặt với các yêu cầu nghiêm ngặt về bảo mật dữ liệu, khả năng phục hồi và hỗ trợ vận hành.
Confluent giải quyết trực tiếp những thách thức này.
Nền tảng tích hợp các biện pháp bảo mật tiên tiến như mã hóa dữ liệu khi lưu trữ và truyền tải, kiểm soát truy cập dựa trên vai trò và ghi nhận audit log.
Đây là những tính năng bảo vệ dữ liệu nhạy cảm và hỗ trợ doanh nghiệp đáp ứng các tiêu chuẩn quy định như GDPR và HIPAA.
Ngoài bảo mật, Confluent Kafka được xây dựng với khả năng chịu lỗi mạnh mẽ và khả năng khôi phục sau thảm họa.
Kiến trúc của nó đảm bảo dữ liệu được sao chép trên nhiều node để ngăn chặn mất mát trong trường hợp phần cứng gặp sự cố hoặc gián đoạn mạng.
Các thỏa thuận mức độ dịch vụ (SLA) được định nghĩa rõ ràng cung cấp cho doanh nghiệp cam kết về độ tin cậy.
Đây là yếu tố then chốt để duy trì hoạt động kinh doanh liên tục.
Hơn nữa, Confluent cung cấp hỗ trợ kỹ thuật chuyên nghiệp từ các chuyên gia Kafka, những người hiểu rõ các khía cạnh phức tạp của nền tảng.
SHỗ trợ chuyên nghiệp mang lại sự tin tưởng cho các công ty khi cơ sở hạ tầng streaming của họ sẽ được duy trì hiệu quả, giảm thiểu thời gian ngừng hoạt động và rủi ro vận hành.
Ví dụ: Một bệnh viện lớn cần đảm bảo dữ liệu bệnh nhân được bảo mật tuyệt đối và hệ thống không bao giờ ngừng hoạt động. Với Confluent Kafka, họ có thể yên tâm về việc tuân thủ HIPAA và có SLA đảm bảo 99.99% uptime.

Kiến trúc Cloud-Native
Confluent Cloud đại diện cho phiên bản cloud-native của Kafka được thiết kế để tối đa hóa các lợi ích của môi trường public cloud.
Kiến trúc này mang lại khả năng mở rộng linh hoạt.
Vì vậy nền tảng có thể điều chỉnh tài nguyên tăng hoặc giảm ngay lập tức dựa trên nhu cầu mà không cần can thiệp thủ công.
Khả năng mở rộng như vậy rất quan trọng đối với các ứng dụng có khối lượng công việc biến động như website bán lẻ trong mùa khuyến mãi lễ hội hoặc dịch vụ tài chính phản ứng với các biến động thị trường.
Thiết kế cloud-native cũng tăng cường khả năng phục hồi vì nó có thể tự động chuyển hướng lưu lượng và khôi phục nhanh chóng sau sự cố, đảm bảo hiệu suất ổn định.
Yếu tố chính đứng sau khả năng này là Kora Engine, công cụ mà Confluent phát triển thông qua tái thiết kế Kafka đặc biệt cho các nền tảng cloud.
Engine này tối ưu hóa sử dụng tài nguyên và throughput trong khi duy trì độ trễ thấp.
Do đó mang lại hiệu suất có thể dự đoán và ổn định ngay cả dưới tải nặng.
Thông qua áp dụng các nguyên tắc cloud-native, Confluent Cloud cung cấp cho doanh nghiệp cách thức khai thác sức mạnh của Kafka mà không cần lo lắng về quản lý cơ sở hạ tầng hay lập kế hoạch dung lượng.
Ví dụ: Một ứng dụng thương mại điện tử có thể tự động tăng gấp đôi tài nguyên xử lý trong Black Friday mà không cần kỹ sư phải thức đêm để điều chỉnh server.
Triển khai linh hoạt
Một lợi ích quan trọng khác là sự linh hoạt mà Confluent cung cấp về mặt môi trường triển khai.
Doanh nghiệp có thể lựa chọn phương án phù hợp nhất với nhu cầu kinh doanh nhờ hỗ trợ cho các thiết lập on-premises, public cloud như AWS hoặc Azure, private cloud.
Ngoài ra mô hình hybrid cloud kết hợp tài nguyên on-prem và cloud hoặc thậm chí các chiến lược multi-cloud liên quan đến nhiều nhà cung cấp.
Do đó giúp công ty điều chỉnh cơ sở hạ tầng streaming phù hợp với chiến lược IT hiện có và các ràng buộc quy định.
Ví dụ: các ngành có quy định nghiêm ngặt về nơi lưu trữ dữ liệu có thể lựa chọn triển khai private hoặc on-prem, trong khi các startup có thể ưa chuộng tính hiệu quả về chi phí của public cloud.
Triển khai hybrid và multi-cloud cũng tạo ra khả năng duy trì hoạt động kinh doanh tốt hơn thông qua tránh bị khóa vào một nhà cung cấp và giảm rủi ro thông qua dự phòng địa lý.
Các nhóm có thể triển khai Kafka cluster gần với nguồn dữ liệu hoặc người dùng cuối để giảm thiểu độ trễ và tối ưu hóa hiệu suất.
Về bản chất, tính linh hoạt triển khai của Confluent trao quyền cho doanh nghiệp điều chỉnh sử dụng Kafka dựa trên các cân nhắc về chi phí, yêu cầu tuân thủ và sở thích kỹ thuật thay vì bị ép buộc vào một giải pháp áp đặt chung.
Ví dụ: Một tập đoàn đa quốc gia có thể đặt dữ liệu khách hàng châu Âu tại Frankfurt để tuân thủ GDPR, dữ liệu Mỹ tại Virginia và vẫn kết nối tất cả thông qua một hệ thống Kafka thống nhất.

Vận hành đơn giản
Quản lý Kafka cluster theo cách truyền thống thường phức tạp do có nhiều cài đặt cấu hình, nhu cầu giám sát và các tác vụ bảo trì như mở rộng quy mô hoặc nâng cấp broker.
Confluent giảm đáng kể gánh nặng vận hành này bằng cách tự động hóa nhiều quy trình.
Nền tảng cung cấp các giao diện quản lý trực quan mang lại cho quản trị viên cái nhìn rõ ràng về tình trạng cluster, luồng message và sử dụng tài nguyên.
Công cụ tự động hóa hỗ trợ các tác vụ thường xuyên như cân bằng tải trên các broker hoặc áp dụng các bản vá mà không gây gián đoạn.
Vận hành đơn giản giải phóng các nhóm kỹ thuật khỏi việc dành quá nhiều thời gian cho bảo trì cơ sở hạ tầng.
Thay vào đó, họ có thể tập trung nhiều hơn vào phát triển các tính năng mới và khai thác giá trị kinh doanh từ streaming dữ liệu.
Vận hành đơn giản cũng có nghĩa là khắc phục sự cố nhanh hơn và giảm rủi ro lỗi con người.
Điều này dẫn đến tính khả dụng cao hơn cho các ứng dụng quan trọng phụ thuộc vào luồng dữ liệu thời gian thực.
Ví dụ: Thay vì cần một nhóm 5 kỹ sư DevOps để giám sát và bảo trì Kafka 24/7, một công ty chỉ cần 1-2 người nhờ các tính năng tự động của Confluent, giúp tiết kiệm đáng kể chi phí nhân sự.
Confluent Platform và Confluent Cloud
Confluent Platform
Tổng quan Confluent Platform
Confluent Platform là một bản phân phối phần mềm toàn diện được xây dựng trên nền tảng Apache Kafka.
Nó được thiết kế chủ yếu cho doanh nghiệp ưa chuộng triển khai và quản lý cơ sở hạ tầng streaming dữ liệu trong môi trường riêng của họ, dù trên phần cứng vật lý hay máy ảo cloud.
Trung tâm của nó là Apache Kafka, hệ thống streaming phân tán mã nguồn mở đã trở thành tiêu chuẩn ngành trong xử lý các pipeline dữ liệu thời gian thực.
Điều làm cho Confluent Platform khác biệt là bổ sung các công cụ và tính năng cấp doanh nghiệp do Confluent phát triển.
Do đó nâng cao khả năng của Kafka với khả năng quản lý, bảo mật và hiệu quả vận hành được cải thiện.
Kết hợp tính mạnh mẽ của mã nguồn mở với các cải tiến doanh nghiệp mang lại cho doanh nghiệp một nền tảng vững chắc để xây dựng kiến trúc dữ liệu streaming có thể mở rộng và đáng tin cậy.
Nền tảng này hỗ trợ nhiều trường hợp sử dụng như microservices hướng sự kiện, phân tích thời gian thực và xử lý message throughput cao.
Do đó tạo ra sự linh hoạt cho doanh nghiệp trong việc tùy chỉnh cơ sở hạ tầng dữ liệu theo nhu cầu cụ thể.
Ví dụ: Một ngân hàng có thể sử dụng Confluent Platform để xây dựng hệ thống phát hiện gian lận real-time, kết hợp dữ liệu từ ATM, ứng dụng mobile banking và website. Tất cả chạy trên server riêng để đảm bảo bảo mật tuyệt đối.
Kiến trúc tự quản lý
Một trong những đặc điểm định nghĩa của Confluent Platform là mô hình triển khai tự quản lý.
Khác với các dịch vụ cloud được quản lý hoàn toàn, nền tảng này đặt toàn bộ trách nhiệm về vòng đời của hệ thống lên chính doanh nghiệp.
Điều này có nghĩa là công ty phải xử lý mọi thứ từ việc mua sắm và cấu hình phần cứng (hoặc cung cấp tài nguyên cloud) đến cài đặt và tinh chỉnh tất cả các thành phần của nền tảng.
Ngoài ra, doanh nghiệp còn phải thiết lập hệ thống giám sát để theo dõi hiệu suất và tình trạng hoạt động, thực hiện việc vá lỗi và nâng cấp phần mềm kịp thời.
Họ cũng phải thiết lập các chiến lược khôi phục sau thảm họa để đảm bảo tính liên tục của hoạt động kinh doanh trong trường hợp xảy ra sự cố.
Mức độ tự chủ cung cấp cho doanh nghiệp quyền kiểm soát đáng kể nhưng cũng đòi hỏi một khung vận hành vững chắc và chuyên môn để duy trì độ tin cậy và bảo mật.
Ví dụ: Giống như sở hữu một chiếc xe ô tô thay vì thuê taxi, người dùng có toàn quyền kiểm soát và tùy chỉnh, nhưng cũng phải chịu trách nhiệm bảo dưỡng, sửa chữa và đảm bảo an toàn.
Ưu điểm của Confluent Platform
Kiểm soát chi tiết CSHT và dữ liệu
Một trong những lợi ích quan trọng nhất của sử dụng Confluent Platform là khả năng Kiểm soát chi tiết mà nó cung cấp đối với mọi khía cạnh của cơ sở hạ tầng và luồng dữ liệu.
Doanh nghiệp có thể tùy chỉnh cấu hình, tối ưu hóa phân bổ tài nguyên và thực thi các chính sách bảo mật nghiêm ngặt phù hợp với yêu cầu ngành của họ.
Điều này đặc biệt quan trọng đối với các lĩnh vực như tài chính, chăm sóc sức khỏe và các cơ quan chính phủ.
Đây là nơi mà tuân thủ quy định và quyền riêng tư dữ liệu là tối quan trọng.
Thông qua quản lý môi trường riêng, công ty tránh được những hạn chế thường được áp đặt bởi các nhà cung cấp cloud bên thứ ba hoặc dịch vụ được quản lý.
Vì thế giúp họ triển khai các chính sách như nơi lưu trữ dữ liệu hoặc tiêu chuẩn mã hóa cụ thể theo quản trị nội bộ.
Ví dụ: Một bệnh viện có thể đặt tất cả dữ liệu bệnh nhân trên server riêng tại Việt Nam, sử dụng thuật toán mã hóa do Bộ TT&TT quy định và không phụ thuộc vào bất kỳ dịch vụ cloud nước ngoài nào.
Phù hợp với chuyên môn hiện có
Confluent Platform có thể là lựa chọn tuyệt vời cho doanh nghiệp đã có các kỹ sư Kafka có kinh nghiệm hoặc nhóm DevOps quen thuộc với công nghệ streaming phân tán.
Những nhóm này có thể tận dụng kiến thức của mình để tinh chỉnh hệ thống, khắc phục sự cố một cách hiệu quả và xây dựng các tích hợp tùy chỉnh phù hợp với nhu cầu kinh doanh độc đáo.
Có chuyên môn nội bộ cũng có nghĩa là thời gian phản hồi nhanh hơn khi xảy ra sự cố và khả năng đổi mới với hệ sinh thái Kafka mà không cần chờ đợi cập nhật dịch vụ được quản lý bởi nhà cung cấp hoặc chu kỳ hỗ trợ.
Do đó đảm bảo khả năng vận hành linh hoạt và tiết kiệm chi phí theo thời gian.
Ví dụ: Một công ty fintech có sẵn team 10 kỹ sư Kafka có thể tự do thử nghiệm các tính năng mới, tối ưu hóa hiệu suất theo cách riêng mà không cần chờ AWS hay Google Cloud cập nhật dịch vụ.
Nhược điểm của Confluent Platform
Yêu cầu chuyên môn cao
Vận hành Confluent Platform không hề đơn giản.
Nó đòi hỏi kiến thức kỹ thuật sâu không chỉ về Kafka mà còn về các nguyên lý hệ thống phân tán, networking, các thực tiễn tốt nhất về bảo mật và quản lý cơ sở hạ tầng.
Nhân viên kỹ thuật cần thành thạo cấu hình broker, quản lý partition và replication, giám sát tình trạng cluster và xử lý các tình huống failover.
Độ phức tạp tăng lên khi triển khai ở quy mô lớn hoặc tích hợp với các hệ thống doanh nghiệp khác.
Nếu thiếu chuyên môn đầy đủ, doanh nghiệp có nguy cơ đối mặt với thời gian ngừng hoạt động kéo dài, mất dữ liệu hoặc sử dụng tài nguyên không hiệu quả.
Do đó, đầu tư vào đào tạo hoặc tuyển dụng nhân sự có kinh nghiệm là điều cần thiết trước khi áp dụng nền tảng này.
Ví dụ: Giống như lái máy bay, người dùng cần bằng lái phi công chuyên nghiệp chứ không thể chỉ xem YouTube mà thực hiện được. Một sai lầm nhỏ trong cấu hình Kafka có thể khiến toàn bộ hệ thống sập trong vài giờ.
Chi chí đầu tư và vận hành
Một yếu tố khác cần xem xét là tổng chi phí sở hữu liên quan đến Confluent Platform.
Vì nó được tự lưu trữ, doanh nghiệp phải đầu tư trước vào phần cứng hoặc cơ sở hạ tầng cloud có khả năng hỗ trợ các luồng dữ liệu throughput cao.
Bên cạnh chi phí cơ sở hạ tầng, còn có phí license cho các tính năng Enterprise của Confluent Platform.
Đây là những tính năng này bổ sung chức năng nâng cao vượt ra ngoài Kafka mã nguồn mở.
Hơn nữa, chi phí vận hành liên tục phát sinh từ yêu cầu duy trì các nhóm chuyên trách để quản lý, bảo trì và bảo mật nền tảng.
Những chi phí này đôi khi có thể cao hơn so với sử dụng các dịch vụ cloud được quản lý hoàn toàn.
Đây là nơi mà phần lớn gánh nặng vận hành được chuyển giao cho nhà cung cấp.
Ví dụ: Một startup có thể tốn 50.000 USD/tháng để tự vận hành Confluent Platform (bao gồm server, license, lương kỹ sư), trong khi dùng Confluent Cloud chỉ tốn 15.000 USD/tháng cho cùng khối lượng công việc.
Confluent Cloud
Tổng quan về Confluent Cloud
Confluent Cloud là dịch vụ streaming dữ liệu Apache Kafka được quản lý và cung cấp hoàn toàn dưới dạng Software-as-a-Service (SaaS).
Nó được thiết kế để người dùng có thể tập trung vào xây dựng ứng dụng và khai thác giá trị từ dữ liệu mà không phải quản lý cơ sở hạ tầng Kafka bên dưới.
Thông qua chuyển giao trách nhiệm vận hành cho Confluent, doanh nghiệp có thể đẩy nhanh hành trình hướng tới streaming dữ liệu thời gian thực với sự phiền toái tối thiểu.
Giải pháp cloud-native xử lý tất cả việc cung cấp cơ sở hạ tầng, mở rộng quy mô, vá lỗi, nâng cấp và các vấn đề về độ tin cậy.
Do đó giải phóng các nhóm phát triển và vận hành để ưu tiên đổi mới và kết quả kinh doanh thay vì bảo trì thường xuyên.
Ví dụ: Giống như sử dụng Netflix thay vì tự xây dựng hệ thống streaming video riêng, người dùng chỉ cần tập trung vào việc chọn phim để xem, còn tất cả hạ tầng phức tạp đằng sau được Netflix lo.
Dịch vụ được quản lý hoàn toàn
Một trong những đặc điểm cơ bản của Confluent Cloud là Confluent đảm nhận toàn bộ trách nhiệm quản lý cơ sở hạ tầng của nền tảng.
Điều này bao gồm cung cấp các tài nguyên tính toán và lưu trữ cần thiết, tự động mở rộng những tài nguyên đó dựa trên nhu cầu khối lượng công việc.
Hơn nữa còn áp dụng các bản vá bảo mật và nâng cấp phần mềm thường xuyên cũng như duy trì tính khả dụng cao và khả năng chịu lỗi trên toàn dịch vụ.
Cách tiếp cận được quản lý đơn giản hóa áp dụng Kafka một cách đáng kể, đặc biệt đối với doanh nghiệp thiếu chuyên môn sâu về Kafka hoặc muốn tránh gánh nặng vận hành vốn có trong các triển khai tự quản lý.
Người dùng có được sự yên tâm khi biết các tác vụ backend quan trọng được xử lý bởi các chuyên gia tối ưu hóa môi trường để đạt hiệu suất và độ tin cậy.
Ví dụ: Thay vì phải thuê 5-6 kỹ sư DevOps để vận hành Kafka 24/7, công ty chỉ cần 1 người để giám sát và sử dụng dịch vụ, tiết kiệm hàng trăm triệu đồng chi phí nhân sự mỗi năm.
Kora Engine
Một đổi mới nổi bật đằng sau Confluent Cloud là Kora Engine, một triển khai Kafka mà Confluent đã tái thiết kế và tối ưu hóa đặc biệt cho môi trường cloud.
Khác với các triển khai Kafka truyền thống nơi tài nguyên tính toán và lưu trữ được liên kết chặt chẽ, Kora tách biệt chúng.
Vì thế tạo ra khả năng mở rộng linh hoạt hơn và hiệu quả chi phí cao hơn.
Kora Engine mang lại một số ưu điểm chính.
Nó cung cấp hiệu suất được cải thiện đáng kể, Confluent tuyên bố nó có thể nhanh hơn tới 10 lần so với các thiết lập Apache Kafka tự quản lý.
Nó cũng cung cấp khả năng mở rộng động phản hồi theo thời gian thực với các khối lượng công việc thay đổi.
Do đó đảm bảo tài nguyên được sử dụng hiệu quả mà không cần can thiệp thủ công.
Ngoài ra, kiến trúc này hỗ trợ cân bằng lại dữ liệu tự động và tối ưu hóa các stack tính toán, lưu trữ và mạng cho các nền tảng cloud.
Những đổi mới này chuyển đổi thành các lợi ích hữu hình như độ trễ thấp hơn, sử dụng tài nguyên tốt hơn và giảm tới 60% tổng chi phí sở hữu (TCO) so với các triển khai Kafka truyền thống trên máy ảo.
Điều này định vị Confluent Cloud không chỉ như một dịch vụ Kafka được hosted mà như một nền tảng cloud-native được thiết kế để tối đa hóa hiệu suất và giảm thiểu chi phí vận hành.
Ví dụ: Một ứng dụng giao dịch chứng khoán cần xử lý 1 triệu giao dịch/giây có thể giảm độ trễ từ 50ms xuống 5ms nhờ Kora Engine, giúp trader phản ứng nhanh hơn và tăng lợi nhuận.
Triển khai trên nhiều nền tảng
Confluent Cloud có sẵn trên các nền tảng public cloud chính bao gồm Amazon Web Services (AWS), Microsoft Azure và Google Cloud Platform (GCP).
Do đó tạo ra sự linh hoạt cho doanh nghiệp trong triển khai khối lượng công việc streaming gần với dữ liệu và ứng dụng hiện có của họ nên giảm độ trễ và đơn giản hóa tích hợp.
Thông qua hoạt động trên những nhà cung cấp cloud đáng tin cậy, Confluent Cloud tận dụng cơ sở hạ tầng toàn cầu và các chứng chỉ tuân thủ của họ.
Vì vậy bổ sung thêm một lớp độ tin cậy và bảo mật cho khách hàng trên toàn thế giới.
Ví dụ: Một công ty đa quốc gia có thể đặt Confluent Cloud tại Singapore để phục vụ thị trường Đông Nam Á, tại Tokyo cho Nhật Bản, và tại Sydney cho Australia. Tất cả tất cả kết nối với nhau trong một hệ thống thống nhất.
Ưu điểm của Confluent Cloud
Giảm gánh nặng vận hành
Thông qua loại bỏ nhu cầu quản lý cơ sở hạ tầng Kafka, Confluent Cloud giúp các nhóm kỹ thuật tập trung vào việc phát triển ứng dụng mang lại giá trị kinh doanh thay vì khắc phục sự cố cluster hoặc quản lý phần cứng.
Sự chuyển đổi từ quản lý cơ sở hạ tầng sang đổi mới ứng dụng có thể đẩy nhanh lịch trình dự án và cải thiện năng suất nhóm.
Ví dụ: Thay vì dành 70% thời gian để “chữa cháy” hệ thống, team developer có thể dành 90% thời gian để xây dựng tính năng mới cho sản phẩm.
Khả năng mở rộng linh hoạt
Confluent Cloud cung cấp khả năng mở rộng đàn hồi.
Do đó giúp người dùng dễ dàng tăng hoặc giảm phân bổ tài nguyên theo nhu cầu khối lượng công việc thực tế.
Linh hoạt giúp tối ưu hóa chi phí bằng khả năng tránh over-provisioning trong khi duy trì hiệu suất trong các đợt tăng lưu lượng.
Các hoạt động mở rộng thường được xử lý tự động hoặc thông qua các điều khiển đơn giản của người dùng.
Ví dụ: Một app thương mại điện tử có thể tự động scale từ 1000 TPS lúc bình thường lên 50.000 TPS trong ngày Black Friday mà không cần can thiệp thủ công.
Mô hình thanh toán Pay-As-You-Go
Mô hình định giá điều chỉnh chi phí trực tiếp với sử dụng nên doanh nghiệp chỉ trả tiền cho các tài nguyên họ tiêu thụ.
Như vậy đặc biệt có lợi cho các khối lượng công việc có nhu cầu biến đổi hoặc cho các startup khởi chạy dự án mới nơi các mẫu lưu lượng không thể dự đoán được.
Cách tiếp cận pay-as-you-go cải thiện khả năng dự đoán chi phí và hiệu quả tài chính.
Thời gian đưa ra thị trường nhanh hơn
Vì không cần thiết lập phức tạp hoặc mua sắm cơ sở hạ tầng, doanh nghiệp có thể làm cho các ứng dụng dựa trên Kafka chạy nhanh hơn nhiều.
Khả năng triển khai nhanh chóng hỗ trợ các thực tiễn phát triển agile và giúp doanh nghiệp phản hồi nhanh chóng với các cơ hội thị trường.
Ví dụ: Một startup fintech có thể triển khai hệ thống thanh toán real-time trong 2 tuần thay vì 6 tháng, giúp họ nhanh chóng cạnh tranh với các ngân hàng lớn.
Nhược điểm của Confluent Cloud
Hạn chế kiểm soát sâu cơ sở hạ tầng
Vì Confluent Cloud trừu tượng hóa quản lý cơ sở hạ tầng nên người dùng có ít quyền kiểm soát chi tiết đối với các cấu hình Kafka cấp thấp so với các môi trường tự quản lý như Confluent Platform.
Đây có thể là nhược điểm đối với doanh nghiệp có yêu cầu tuning rất cụ thể hoặc yêu cầu tuân thủ đòi hỏi kiểm soát sâu đối với mọi khía cạnh của hệ thống.
Ví dụ: Giống như thuê căn hộ dịch vụ, người dùng không thể tự ý sửa đổi hệ thống điện, nước hay thay đổi cấu trúc theo ý muốn.
Chi phí có thể tăng cao
Mặc dù mô hình pay-as-you-go cung cấp sự linh hoạt nhưng nó cũng đòi hỏi giám sát cẩn thận để tránh tăng chi phí bất ngờ.
Phí data egress liên quan đến chuyển dữ liệu ra khỏi cloud có thể tích lũy nhanh chóng nếu không được tối ưu hóa.
Doanh nghiệp phải triển khai các thực tiễn quản trị chi phí hiệu quả để kiểm soát chi tiêu.
Ví dụ: Một công ty có thể bị “sốc hóa đơn” khi chi phí tăng từ 10.000 USD/tháng lên 100.000 USD/tháng chỉ vì cấu hình sai data replication giữa các region.
Phụ thuộc nhiều vào nhà cung cấp
Dựa vào nhà cung cấp SaaS có nghĩa là giao phó cơ sở hạ tầng streaming dữ liệu quan trọng cho một bên bên ngoài.
Mặc dù Confluent đã thiết lập mình như một nhà cung cấp đáng tin cậy với SLA mạnh mẽ.
Tuy nhiên nó cũng đưa ra các rủi ro liên quan đến tính khả dụng dịch vụ, thay đổi giá cả hoặc thay đổi chiến lược của nhà cung cấp mà khách hàng phải cân nhắc.
Sự khác biệt của Kora Engine
Giới thiệu Kora Engine báo hiệu Confluent Cloud không chỉ đơn giản là hosting các Kafka broker truyền thống trên máy ảo cloud.
Thay vào đó, nó đại diện cho một thiết kế lại cơ bản được tùy chỉnh đặc biệt cho môi trường cloud.
Những tính năng như cân bằng dữ liệu tự động, các lớp tính toán và lưu trữ tách biệt và các stack mạng được tối ưu hóa tạo ra hiệu suất và hiệu quả chi phí vượt trội.
Kiến trúc Kafka truyền thống thường liên kết tính toán và lưu trữ chặt chẽ với nhau nên khó mở rộng tài nguyên độc lập hoặc đạt được tiết kiệm chi phí trong các triển khai cloud.
Thiết kế cloud-native của Kora vượt qua những hạn chế này thông qua mở rộng đàn hồi phù hợp với các mẫu nhu cầu thời gian thực.
Đổi mới kiến trúc dẫn đến độ trễ thấp hơn đáng kể và giảm tổng chi phí sở hữu so với các triển khai Kafka tự quản lý điển hình trên máy ảo.
Những ưu điểm này làm cho Confluent Cloud trở thành lựa chọn hấp dẫn cho các ứng dụng streaming quy mô lớn và định vị nó một cách mạnh mẽ so với các dịch vụ Kafka được quản lý khác trên thị trường.
Ví dụ: Nếu Kafka truyền thống giống như xe tải chở hàng, thì Kora Engine giống như hệ thống logistics thông minh có thể tự động điều phối drone, xe tải, tàu hỏa tùy theo loại hàng hóa và khoảng cách nên hiệu quả và tiết kiệm hơn nhiều.
So sánh Confluent Platform và Confluent Cloud
| Tiêu chí | Confluent Platform | Confluent Cloud | Nhận xét |
|---|---|---|---|
| Quản lý hạ tầng | Tự quản lý (máy chủ, cài đặt, cấu hình, bản vá, nâng cấp, DR) | Được quản lý hoàn toàn bởi Confluent | Platform đòi hỏi nhiều nỗ lực vận hành, Cloud giảm tải vận hành. |
| Khả năng mở rộng | Thủ công, cần kế hoạch và chuyên môn. Có Self-Balancing Clusters (bản enterprise). | Linh hoạt, tự động hoặc qua điều khiển đơn giản (CKUs, eCKUs). Được hỗ trợ bởi Kora Engine. | Cloud dễ dàng mở rộng hơn và được tối ưu cho việc này. |
| Chi phí | Chi phí hạ tầng, nhân sự vận hành, bản quyền phần mềm Confluent Platform. | Mô hình pay-as-you-go, dựa trên tiêu thụ. Có thể phát sinh chi phí data egress. | Cloud có thể hiệu quả hơn cho khởi đầu hoặc tải công việc biến đổi, nhưng cần theo dõi để tránh chi phí leo thang. |
| Kiểm soát | Toàn quyền Kiểm soát cấu hình và hạ tầng. | Ít quyền kiểm soát hạ tầng sâu. Một số cấu hình có thể bị hạn chế. | Platform phù hợp cho yêu cầu tuân thủ nghiêm ngặt hoặc tùy chỉnh sâu. |
| Chuyên môn yêu cầu | Đòi hỏi chuyên môn Kafka và vận hành hệ thống cao. | Ít yêu cầu chuyên môn vận hành hạ tầng Kafka. | Cloud phù hợp cho đội ngũ muốn tập trung vào phát triển ứng dụng. |
| Tùy chọn triển khai | On-premise, private cloud, public cloud (VMs). | Public cloud (AWS, Azure, GCP). | Platform linh hoạt hơn về vị trí triển khai vật lý. |
| Nâng cấp & Bảo trì | Do người dùng tự thực hiện. | Do Confluent thực hiện. | Cloud giảm thiểu rủi ro và thời gian chết liên quan đến nâng cấp. |
| Bảo mật | Người dùng chịu trách nhiệm cấu hình và quản lý nhiều khía cạnh bảo mật. | Confluent cung cấp các tính năng bảo mật tích hợp, tuân thủ nhiều tiêu chuẩn. | Cloud có thể đơn giản hóa việc đạt được các tuân thủ bảo mật. |
| Hỗ trợ | Hỗ trợ doanh nghiệp từ Confluent (tùy theo gói). Cộng đồng. | Hỗ trợ doanh nghiệp từ Confluent. | Cả hai đều có hỗ trợ từ Confluent, nhưng Cloud là dịch vụ được quản lý nên hỗ trợ bao gồm cả hạ tầng. |
| Giao diện quản lý | Confluent Control Center. | Confluent Cloud Console. | Cả hai đều cung cấp giao diện web để quản lý và giám sát. |
| Xử lý luồng (Flink) | Confluent Platform for Apache Flink (tự quản lý, thường trên Kubernetes). | Confluent Cloud for Apache Flink (serverless, được quản lý hoàn toàn). | Cloud Flink đơn giản hóa việc phát triển ứng dụng xử lý luồng phức tạp. |
| Connectors | Tự triển khai và quản lý Kafka Connect workers. Truy cập Confluent Hub. | Thư viện các connectors được quản lý hoàn toàn. | Cloud Connectors tiện lợi hơn nhưng danh sách có thể ít hơn so với Hub cho việc tự quản lý. |
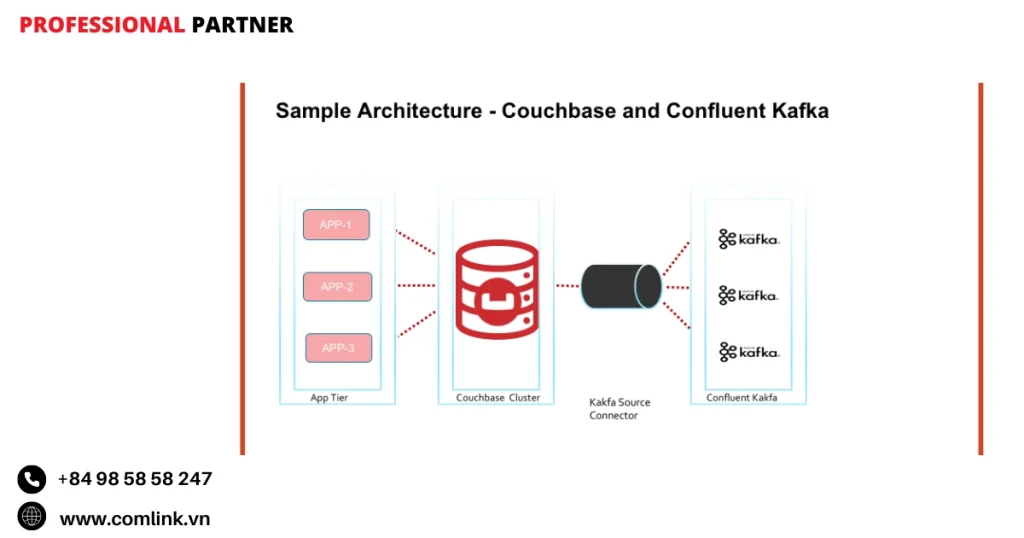
Thành phần Confluent Kafka
Confluent Server (Broker)
Giới thiệu về Confluent Server
Confluent Server đóng vai trò là trái tim của nền tảng Confluent.
Nó hoạt động như một Kafka broker trong môi trường này.
Mặc dù được xây dựng trên nền tảng của các broker mã nguồn mở Apache Kafka, Confluent Server không đơn thuần là đóng gói lại các broker Kafka tiêu chuẩn.
Thay vào đó, nó tích hợp một loạt các tính năng thương mại và tối ưu hóa hiệu suất do Confluent phát triển để đáp ứng nhu cầu của các ứng dụng streaming cấp doanh nghiệp.
Như vậy Confluent Server kế thừa tất cả các khả năng mạnh mẽ của Apache Kafka mã nguồn mở nhưng còn nâng cao chúng với các thành phần độc quyền và cải tiến được thiết kế.
Do đó nó có khả năng giải quyết những thách thức vận hành mà doanh nghiệp gặp phải khi triển khai Kafka ở quy mô lớn.
Cải tiến cấp doanh nghiệp
Các tính năng bổ sung được tích hợp vào Confluent Server tập trung chủ yếu vào khắc phục những điểm yếu thường gặp trong quá trình vận hành Kafka quy mô lớn.
Những cải tiến này hỗ trợ các yêu cầu kiến trúc phức tạp, cải thiện độ tin cậy tổng thể của hệ thống và tăng tốc quá trình phát triển các ứng dụng dữ liệu streaming.
Self-Balancing Clusters (Cụm tự cân bằng)
Một trong những tính năng nổi bật là Self-Balancing Clusters.
Khả năng này tự động hóa phân phối lại các phân vùng dữ liệu (partition) trên các broker trong một cụm.
Điều này rất quan trọng để duy trì khối lượng công việc cân bằng và tối ưu hóa sử dụng tài nguyên khi môi trường phát triển.
Self-Balancing Clusters có thể phát hiện sớm các lỗi broker và khởi động các hành động phục hồi tự động mà không cần can thiệp thủ công.
Nó cũng hỗ trợ mở rộng động, hỗ trợ thêm hoặc loại bỏ broker một cách mượt mà trong khi vẫn duy trì tính ổn định của cụm.
Tự động hóa giảm đáng kể chi phí vận hành liên quan đến quản lý cụm và giúp duy trì tính khả dụng cao cũng như hiệu suất đỉnh cao.
Ví dụ: Giả sử có một cụm Kafka với 6 broker đang xử lý dữ liệu giao dịch tài chính. Khi một broker gặp sự cố phần cứng, thay vì phải thủ công phân phối lại các partition và có thể gây gián đoạn dịch vụ trong vài giờ, Self-Balancing Clusters sẽ tự động phát hiện sự cố và tái phân phối các partition sang các broker khỏe mạnh khác trong vòng vài phút.
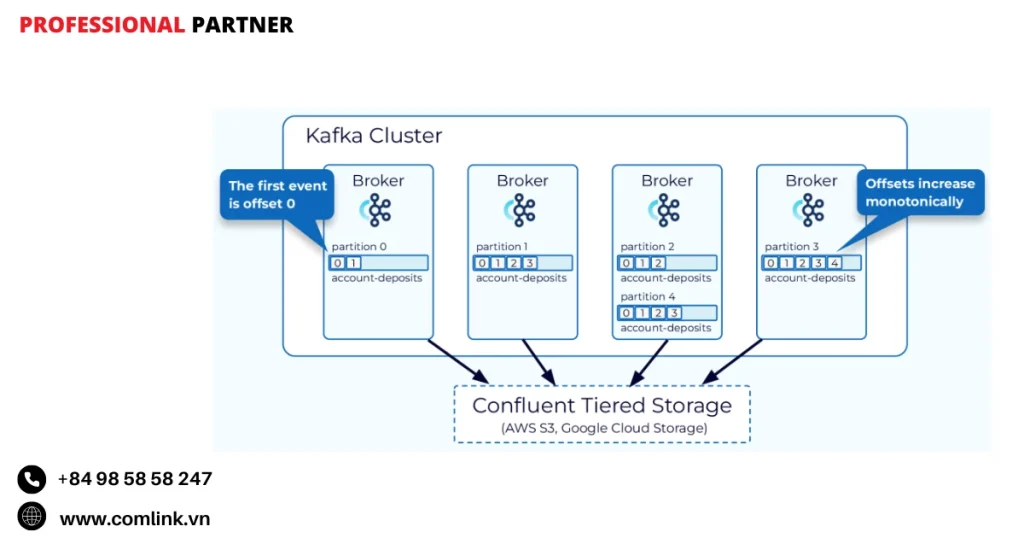
Tiered Storage (Lưu trữ phân tầng)
Tiered Storage giải quyết một trong những thách thức lớn nhất trong quản lý Kafka.
Đó là kiểm soát chi phí lưu trữ khi khối lượng dữ liệu tăng theo thời gian.
Với tính năng này, dữ liệu Kafka được lưu trữ trên nhiều tầng dựa trên tần suất truy cập và tuổi của dữ liệu.
Dữ liệu mới và được truy cập thường xuyên vẫn được giữ trên các ổ lưu trữ nhanh hơn, đắt tiền hơn.
Dữ liệu cũ hơn, ít được truy cập sẽ tự động được chuyển sang các hệ thống lưu trữ đối tượng tiết kiệm chi phí hơn như Amazon S3, Google Cloud Storage hoặc Azure Blob Storage.
Cách tiếp cận này giảm đáng kể chi phí lưu trữ dài hạn mà không ảnh hưởng đến khả năng truy cập khi cần truy xuất dữ liệu cũ.
Ví dụ: Một công ty thương mại điện tử lưu trữ log hành vi người dùng trong 2 năm. Dữ liệu từ 3 tháng gần đây (được phân tích hàng ngày) được giữ trên SSD tốc độ cao, trong khi dữ liệu cũ hơn (chỉ được truy cập để phân tích xu hướng dài hạn) được chuyển sang Amazon S3, giảm chi phí lưu trữ từ $10,000/tháng xuống $2,000/tháng.
Cluster Linking (Liên kết Cụm)
Cluster Linking cung cấp một cách liền mạch để kết nối các cụm Kafka riêng biệt nhằm mục đích sao chép topic.
Tính năng này tạo điều kiện sao chép hiệu quả và đáng tin cậy các topic giữa các cụm.
Do đó đơn giản hóa việc tạo ra các kiến trúc đa trung tâm dữ liệu và môi trường đám mây kết hợp giữa tài nguyên tại chỗ và đám mây.
Nó cũng hỗ trợ triển khai đa đám mây và hỗ trợ các trường hợp sử dụng quan trọng như di chuyển dữ liệu và lập kế hoạch khôi phục thảm họa.
Với Cluster Linking, doanh nghiệp có thể xây dựng cơ sở hạ tầng streaming phân tán có khả năng phục hồi trải rộng trên các khu vực địa lý hoặc nhà cung cấp đám mây với độ phức tạp tối thiểu.
Ví dụ: Một ngân hàng có trung tâm dữ liệu chính tại New York và trung tâm dự phòng tại London. Cluster Linking tự động đồng bộ dữ liệu giao dịch quan trọng giữa hai địa điểm trong thời gian thực.
Vì thế đảm bảo nếu trung tâm New York gặp sự cố, hệ thống London có thể tiếp quản ngay lập tức mà không mất dữ liệu.
Vai ttrò của Confluent Server
Những tính năng doanh nghiệp trực tiếp giải quyết một số thách thức cố hữu khi vận hành Apache Kafka thuần túy trong các môi trường quy mô lớn.
Không có tự động hóa, cân bằng lại các partition khi thành viên cụm thay đổi có thể là một quá trình tdễ xảy ra lỗi và có nguy cơ gây suy giảm hiệu suất tạm thời hoặc dữ liệu không khả dụng.
Self-Balancing Clusters loại bỏ vấn đề này bằng cách điều phối các hoạt động này một cách trong suốt.
Quản lý chi phí lưu trữ
Thiết kế của Kafka khuyến khích việc giữ lại lượng lớn dữ liệu sự kiện trong thời gian dài.
Quản lý tập dữ liệu lịch sử ngày càng tăng này chỉ trên các ổ đĩa hiệu suất cao trở nên quá đắt đỏ.
Tiered Storage cung cấp một giải pháp thông minh tối ưu hóa chi phí trong khi vẫn duy trì khả năng truy cập dữ liệu.
Kiến trúc đa-cụm phức tạp
Thiết lập giao tiếp và sao chép đáng tin cậy giữa các cụm Kafka riêng biệt theo truyền thống đòi hỏi công cụ tùy chỉnh hoặc cấu hình thủ công phức tạp.
Cluster Linking đơn giản hóa các thiết lập này, làm cho các cấu trúc triển khai nâng cao trở nên dễ đạt được và quản lý hơn.
Thông qua tích hợp những khả năng này trực tiếp vào lớp broker, Confluent Server trở thành một phiên bản “thông minh hơn” và tự quản lý hơn của phần mềm broker Kafka.
Do đó giảm gánh nặng vận hành cho các nhóm kỹ thuật, tăng cường tính ổn định của hệ thống và giúp tối ưu hóa chi phí.
Đây là những yếu tố quan trọng đối với doanh nghiệp xử lý khối lượng công việc streaming vào những yêu cầu quan trọng.
Confluent Schema Registry
Tổng quan về Schema Registry
Confluent Schema Registry là thành phần thiết yếu trong hệ sinh thái Confluent.
Nó hoạt động như một lớp phục vụ chuyên dụng để quản lý siêu dữ liệu (metadata), đặc biệt là các schema định nghĩa cấu trúc của dữ liệu được truyền qua Kafka.
Mục đích chính của nó là cung cấp một kho lưu trữ tập trung, đáng tin cậy và có kiểm soát phiên bản cho các schema này.
Vì vậy đảm bảo tất cả các ứng dụng sản xuất và tiêu thụ tin nhắn Kafka tuân thủ một định dạng dữ liệu nhất quán.
Thông qua việc quản lý schema tập trung, Schema Registry đóng vai trò quan trọng trong việc duy trì chất lượng dữ liệu.
Do đó tạo điều kiện cho phát triển schema an toàn và đơn giản hóa tích hợp dữ liệu trên các hệ thống phân tán.
Các chức năng chính
Lưu trữ và truy xuất Schema
Schema Registry cung cấp kho lưu trữ tập trung để lưu trữ schema, hỗ trợ các định dạng phổ biến như Apache Avro® (định dạng mặc định ban đầu), JSON Schema và Google Protobuf.
Các schema được đăng ký và truy xuất thông qua RESTful API, giúp việc tương tác với dịch vụ trở nên đơn giản cho cả producer và consumer.
Tập trung hóa giúp nhiều ứng dụng chia sẻ và tái sử dụng schema một cách hiệu quả.
Vì thế giảm thiểu sự không nhất quán và trùng lặp trong toàn bộ pipeline dữ liệu.
Ví dụ: Một công ty fintech có 15 microservice khác nhau xử lý dữ liệu giao dịch. Thay vì mỗi service tự định nghĩa schema riêng (có thể dẫn đến sự khác biệt như “amount” vs “transaction_amount”), tất cả đều sử dụng cùng một schema từ Schema Registry, đảm bảo tính nhất quán.
Quản lý phiên bản Schema
Một tính năng chính là khả năng duy trì lịch sử hoàn chỉnh của tất cả các phiên bản schema được đăng ký dưới một “subject”, thường tương ứng với một Kafka topic.
Hệ thống phiên bản này giúp schema phát triển theo thời gian trong khi vẫn bảo tồn các phiên bản trước đó để dữ liệu cũ vẫn có thể được diễn giải chính xác.
Kiểm soát phiên bản tạo điều kiện cho thay đổi schema có kiểm soát mà không làm hỏng các producer hoặc consumer hiện có.
Vì vậy hỗ trợ phát triển liên tục trong môi trường dữ liệu đang phát triển.
Ví dụ: Một ứng dụng e-commerce ban đầu chỉ lưu trữ thông tin cơ bản của khách hàng (tên, email). Sau 6 tháng, họ muốn thêm trường “phone_number”. Schema Registry sẽ lưu trữ cả phiên bản 1 (không có phone) và phiên bản 2 (có phone) nên đảm bảo dữ liệu cũ vẫn có thể được đọc và xử lý bình thường.
Kiểm tra tương thích
Schema Registry áp dụng các quy tắc tương thích khi đăng ký các phiên bản schema mới.
Các chế độ tương thích như BACKWARD, FORWARD, FULL hoặc NONE đảm bảo cho các thay đổi schema không làm gián đoạn các luồng dữ liệu hiện có.
Ví dụ: tương thích ngược đảm bảo schema mới có thể đọc dữ liệu được tuần tự hóa với các phiên bản trước đó, ngăn ngừa lỗi ở consumer mong đợi định dạng cũ hơn. Biện pháp bảo vệ này rất quan trọng để duy trì hoạt động không bị gián đoạn trong môi trường sản xuất.
Tích hợp với Kafka Client
Confluent cung cấp các serializer và deserializer chuyên biệt tích hợp liền mạch với Kafka producer và consumer.
Các thành phần này tự động đăng ký schema mới với Schema Registry khi producer gửi dữ liệu và lấy các schema tương ứng khi consumer nhận tin nhắn.
Tự động hóa đơn giản hóa mã ứng dụng bằng cách trừu tượng hóa các chi tiết xử lý schema.
Do đó đảm bảo tất cả dữ liệu tin nhắn tuân thủ các schema đã đăng ký và tính nhất quán trong toàn bộ pipeline.
Hoạt động độc lập với lưu trữ Backend Kafka
Mặc dù Schema Registry hoạt động như một dịch vụ độc lập tách biệt khỏi các Kafka broker nhưng nó sử dụng chính Kafka như một backend bền vững để lưu trữ schema và metadata cấu hình.
Tất cả định nghĩa schema, thông tin phiên bản, ID và cài đặt tương thích đều được lưu trữ trong một Kafka topic đặc biệt (mặc định có tên _schemas).
Thiết kế này tận dụng khả năng chịu lỗi và độ bền của Kafka để bảo vệ metadata quan trọng, đảm bảo tính khả dụng cao và khả năng phục hồi của thông tin schema.
Vai trò của Schema Registry
Đảm bảo tính toàn vẹn dữ liệu
Thông qua áp dụng xác thực schema trên các tin nhắn đến, Schema Registry ngăn chặn producer gửi dữ liệu có định dạng sai hoặc cấu trúc không phù hợp vào các Kafka topic.
Cơ chế này rất cần thiết để duy trì các tập dữ liệu chất lượng cao, nhất quán mà các ứng dụng downstream có thể tin tưởng.
Phát triển Schema an toàn
Trong các hệ thống liên tục phát triển, khả năng thay đổi cấu trúc dữ liệu mà không làm hỏng các thành phần hiện có là vô cùng quý giá.
Schema Registry hỗ trợ điều này thông qua quản lý phiên bản và kiểm tra tương thích.
Do đó giúp các nhà phát triển thêm trường hoặc sửa đổi schema một cách thận trọng trong khi đảm bảo tương thích ngược hoặc tiến.
Vì vậy giảm nguy cơ thời gian ngừng hoạt động và mất dữ liệu liên quan đến các thay đổi schema không tương thích trong môi trường đang hoạt động.
Ví dụ: Một startup IoT cần thêm trường “battery_level” vào dữ liệu sensor hiện có. Với Schema Registry, họ có thể triển khai thay đổi này từng bước.
Trước tiên cập nhật producer để gửi trường mới (với giá trị mặc định).
Sau đó từ từ cập nhật consumer để xử lý trường mới, tất cả mà không gây gián đoạn dịch vụ.
Truyền tải dữ liệu hiệu quả
Sử dụng các định dạng tuần tự hóa nhỏ gọn như Avro giảm đáng kể kích thước tin nhắn nhờ tránh gửi schema đầy đủ cùng với mỗi tin nhắn.
Thay vào đó, mỗi schema được đăng ký một lần và được gán một ID duy nhất.
Tin nhắn chỉ mang theo ID nhỏ này cùng với dữ liệu được tuần tự hóa.
Consumer sử dụng ID để lấy schema đầy đủ từ Schema Registry khi giải mã tin nhắn.
Cách tiếp cận này tiết kiệm băng thông và không gian lưu trữ trong khi vẫn bảo tồn thông tin cấu trúc dữ liệu phong phú.
Ví dụ: Một tin nhắn giao dịch có thể có kích thước 2KB nếu bao gồm cả schema. Với Schema Registry, tin nhắn chỉ cần 4 byte cho schema ID + dữ liệu thực tế (~200 byte), giảm 90% kích thước và tiết kiệm hàng GB bandwidth mỗi ngày cho một hệ thống có lưu lượng cao.
Hỗ trợ đa định dạng
Schema Registry có thể quản lý các loại schema khác nhau đồng thời trong cùng một instance.
Doanh nghiệp có thể sử dụng Avro cho một số topic trong khi tận dụng Protobuf hoặc JSON Schema cho các topic khác.
Tất cả đều được điều phối tập trung bởi một dịch vụ Schema Registry.
Tính linh hoạt này đáp ứng nhu cầu ứng dụng đa dạng mà không làm phân mảnh nỗ lực quản lý schema.
Vai trò chiến lược với quản trị dữ liệu
Ngoài chức năng kỹ thuật, Schema Registry đóng vai trò là nền tảng của chiến lược quản trị dữ liệu của doanh nghiệp.
Nó áp dụng các data contract thỏa thuận rõ ràng về cấu trúc dữ liệu giữa producer và consumer trên các kiến trúc microservice phân tán.
Trong các hệ thống điều khiển sự kiện phức tạp nơi các dịch vụ tương tác bất đồng bộ mà không có kiến thức sâu về nội bộ của nhau.
Do đó có một hợp đồng schema rõ ràng, có phiên bản là vô cùng quý giá.
Nó cung cấp một nguồn sự thật duy nhất cho ý nghĩa và cấu trúc dữ liệu.
Vì thế giảm đáng kể lỗi tích hợp và tạo điều kiện cho các nhóm phát triển độc lập làm việc tự chủ hơn trong khi vẫn duy trì tính nhất quán toàn hệ thống.
Ví dụ: Một ngân hàng có 50+ microservice xử lý các giao dịch khác nhau. Mỗi service được phát triển bởi team khác nhau ở các múi giờ khác nhau. Schema Registry đảm bảo rằng định nghĩa “transaction” (với các trường như amount, currency, timestamp) được hiểu thống nhất bởi tất cả service, ngăn ngừa lỗi như nhầm lẫn USD với EUR.
Trong các ngành được quản lý chặt chẽ như tài chính, nơi khả năng kiểm soát và tuân thủ các định dạng dữ liệu được phê duyệt là quan trọng.
Vì vậy khả năng quản lý phiên bản tập trung và áp dụng của Schema Registry giúp đáp ứng các yêu cầu tuân thủ một cách mạnh mẽ.
Khi kết hợp với các công cụ Confluent khác như Stream Lineage (theo dõi nguồn gốc) và chuyển đổi dữ liệu qua các topic và ứng dụng xử lý, Schema Registry giúp tạo ra nền tảng vững chắc cho quản trị dữ liệu hiệu quả trong kiến trúc streaming.
ksqlDB
ksqlDB là gì?
ksqlDB là cơ sở dữ liệu được xây dựng chuyên biệt để xử lý stream trên Kafka.
Được phát triển dựa trên nền tảng Kafka Streams, một thư viện xử lý stream mạnh mẽ và linh hoạt thuộc dự án Apache Kafka, ksqlDB giúp người dùng tương tác với dữ liệu streaming thông qua các lệnh SQL.
Thiết kế này cung cấp một cách tiếp cận dễ hiểu để lọc, chuyển đổi, tổng hợp, kết hợp và phân cửa sổ các luồng sự kiện chảy qua các Kafka topic.
Khác với các API cấp thấp đòi hỏi viết mã phức tạp, ksqlDB trừu tượng hóa phần lớn sự phức tạp này khi hỗ trợ các nhà phát triển viết các truy vấn giống SQL thực thi liên tục trên các luồng dữ liệu trực tiếp.
Điều này có nghĩa là có thể xây dựng các ứng dụng thời gian thực và pipeline dữ liệu nhanh hơn nhiều và với ít dòng mã hơn.
Sức mạnh của SQL trong xử lý Stream
Một trong những tính năng nổi bật của ksqlDB là giao diện SQL được áp dụng cho dữ liệu streaming.
Sử dụng SQL giúp những người dùng quen thuộc với truy vấn cơ sở dữ liệu dễ dàng làm việc với dữ liệu liên tục chảy.
Một số thao tác phổ biến với ksqlDB:
- Lọc dữ liệu: Chọn các sự kiện cụ thể từ một stream dựa trên điều kiện, chẳng hạn như lọc giao dịch trên một số tiền nhất định hoặc hoạt động người dùng từ một khu vực cụ thể.
- Chuyển đổi: Sửa đổi cấu trúc hoặc nội dung của các sự kiện, ví dụ như trích xuất các trường cụ thể hoặc tạo ra các cột mới từ dữ liệu hiện có.
- Tổng hợp: Tính toán thống kê tóm tắt như số lượng, tổng hoặc trung bình trong các cửa sổ thời gian xác định. Điều này hữu ích cho việc giám sát xu hướng hoặc tóm tắt hành vi người dùng theo thời gian.
- Kết hợp: Kết hợp dữ liệu từ nhiều stream hoặc giữa một stream và một table, giúp làm phong phú dữ liệu sự kiện với thông tin tham chiếu.
- Phân cửa sổ: Xử lý các sự kiện trong khung thời gian cụ thể như tumbling window (khoảng thời gian cố định), hopping window (khoảng thời gian chồng lấn) hoặc session window (nhóm các sự kiện liên quan theo phiên người dùng).
- Phân phiên: Nhóm các sự kiện liên quan đến phiên người dùng cá nhân để phân tích các mẫu hành vi người dùng trong một phiên.
Ví dụ: Một sàn thương mại điện tử có thể sử dụng ksqlDB để theo dõi hành vi mua hàng theo thời gian thực.
Họ có thể viết truy vấn SQL đơn giản để tính tổng doanh số theo từng phút, lọc ra những đơn hàng có giá trị cao, hoặc phát hiện những khách hàng đang có hành vi mua sắm bất thường.
Tất cả chỉ với vài dòng SQL thay vì hàng trăm dòng Java code.
Các thao tác này cung cấp cho nhà phát triển một bộ công cụ phong phú để xử lý các sự kiện streaming trong thời gian thực mà không cần phải xây dựng mọi thứ từ đầu.
Khái niệm cốt lõi
Để làm việc hiệu quả với dữ liệu streaming, ksqlDB giới thiệu hai khái niệm trừu tượng cơ bản:
Khái niệm STREAM
Một STREAM đại diện cho một chuỗi vô hạn các sự kiện bất biến có cấu trúc nhưng không thể thay đổi sau khi được tạo ra.
Mỗi sự kiện mới được thêm vào không làm thay đổi các sự kiện trước đó.
Về mặt khái niệm, một STREAM tương ứng chặt chẽ với một Kafka topic, nơi các tin nhắn liên tục đến.
Khái niệm TABLE
Một TABLE đại diện cho trạng thái hiện tại của một tập dữ liệu được cập nhật theo thời gian khi có sự kiện mới đến.
Nó có thể được coi như một materialized view được tạo ra từ một hoặc nhiều stream.
Một TABLE có thể chứa số dư mới nhất cho mỗi tài khoản ngân hàng được cập nhật bởi các giao dịch đến.
Ví dụ: Hãy tưởng tượng một hệ thống ngân hàng. STREAM “transactions” sẽ chứa tất cả giao dịch (nạp tiền, rút tiền, chuyển khoản) theo thứ tự thời gian.
TABLE “account_balances” sẽ chứa số dư hiện tại của mỗi tài khoản mỗi khi có giao dịch mới từ STREAM, TABLE sẽ được cập nhật để phản ánh số dư mới.
Hiểu rõ sự khác biệt này rất quan trọng vì nhiều thao tác streaming phụ thuộc vào việc đang xử lý chuỗi sự kiện thô (STREAM) hay trạng thái đang phát triển (TABLE).
Thách thức và cân nhắc khi sử dụng
Mặc dù ksqlDB mang lại những lợi thế đáng kể trong đơn giản hóa xử lý stream, các nhà phát triển nên lưu ý một số thách thức:
Hiệu suất
Các truy vấn được tối ưu hóa kém hoặc phân bổ tài nguyên không đủ có thể dẫn đến độ trễ cao và sử dụng CPU hoặc bộ nhớ không hiệu quả.
Giám sát và điều chỉnh liên tục cả truy vấn và tài nguyên cụm là cần thiết để duy trì hoạt động mượt mà.
Lỗi truy vấn
Lỗi cú pháp hoặc không khớp kiểu dữ liệu giữa stream và table là những cạm bẫy phổ biến.
Tuân thủ nghiêm ngặt cú pháp SQL của ksqlDB và quản lý cẩn thận schema thông qua các công cụ như Schema Registry giúp ngăn ngừa những vấn đề này.
Thách thức tích hợp
Duy trì tính tương thích giữa các phiên bản của ksqlDB, cụm Kafka và các công cụ bên thứ ba là rất quan trọng.
Cấu hình sai có thể gây ra lỗi kết nối hoặc hành vi không mong muốn, vì vậy quản lý phiên bản phối hợp là cần thiết.
Ví dụ: Một công ty startup đã gặp phải tình huống nghiêm trọng khi họ nâng cấp ksqlDB mà không kiểm tra tương thích với phiên bản Kafka hiện tại.
Kết quả là toàn bộ pipeline real-time analytics bị gián đoạn trong 4 giờ, ảnh hưởng đến dashboard báo cáo cho leadership team.
Các nhà phát triển nên lập kế hoạch cho những trở ngại tiềm ẩn này từ sớm trong dự án để tránh gián đoạn sau này.
Xử lý Stream với ksqlDB
Một trong những khía cạnh thú vị nhất của ksqlDB là cách nó “dân chủ hóa” xử lý dữ liệu streaming.
Thông qua cung cấp giao diện SQL quen thuộc, nó mở ra khả năng thao tác dữ liệu thời gian thực không chỉ cho các kỹ sư phần mềm mà còn cho các nhà phân tích dữ liệu và những người khác có thể thiếu kinh nghiệm lập trình sâu.
Do đó mở rộng sự tham gia trong xây dựng các ứng dụng streaming trong tổ chức và tăng tốc chu kỳ phát triển.
Ví dụ: Trước đây, khi business analyst muốn tạo báo cáo real-time về hiệu suất marketing campaign, họ phải yêu cầu team engineering viết code Kafka Streams phức tạp (có thể mất 2-3 tuần).
Với ksqlDB, cùng một analyst đó có thể tự viết truy vấn SQL và có kết quả trong vài giờ.
Tuy nhiên, điều quan trọng là phải nhận ra rằng SQL có những hạn chế so với các ngôn ngữ lập trình đầy đủ tính năng như Java hoặc Scala.
Đối với logic cực kỳ phức tạp đòi hỏi thuật toán tùy chỉnh hoặc kiểm soát chi tiết về trạng thái và hiệu suất, sử dụng trực tiếp Kafka Streams hoặc các framework mạnh mẽ khác như Apache Flink có thể phù hợp hơn.
Ví dụ: Confluent Cloud cung cấp tích hợp Apache Flink cho các nhu cầu xử lý stream nâng cao.
Do đó, trong khi ksqlDB xuất sắc để tăng tốc phát triển và mở rộng khả năng tiếp cận cho nhiều trường hợp sử dụng, nó bổ sung chứ không thay thế các framework xử lý stream phức tạp hơn.
Ví dụ: Một thuật toán machine learning phức tạp để phát hiện fraud real-time với multiple model ensemble và custom feature engineering vẫn nên được implement bằng Kafka Streams hoặc Flink.
Nhưng tính toán các metrics đơn giản như “số lượng giao dịch bất thường trong 5 phút qua” thì ksqlDB xử lý một cách hoàn hảo và nhanh chóng.
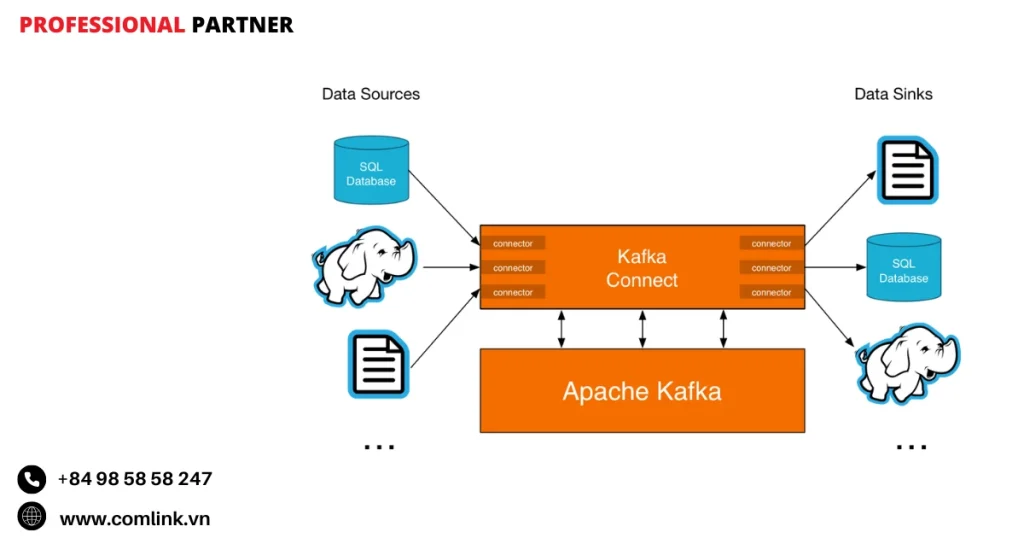
Kafka Connect và Confluent Connectors
Kafka Connect là gì
Kafka Connect là một framework mạnh mẽ được thiết kế để xây dựng và vận hành các pipeline dữ liệu có khả năng mở rộng và chịu lỗi, giúp truyền tải dữ liệu giữa Kafka và các hệ thống khác.
Nó trừu tượng hóa phần lớn sự phức tạp liên quan đến việc di chuyển dữ liệu, giúp người dùng kết nối các nguồn bên ngoài với Kafka (thông qua Source Connector) và xuất dữ liệu từ Kafka sang các hệ thống đích (sử dụng Sink Connector).
Về cốt lõi, Kafka Connect giảm thiểu nhu cầu viết mã tùy chỉnh cho mỗi điểm tích hợp.
Thay vào đó, nó tận dụng các plugin connector có thể tái sử dụng để xử lý các chi tiết cụ thể khi tương tác với nhiều hệ thống lưu trữ, cơ sở dữ liệu, dịch vụ đám mây và nhiều hơn nữa.
Nguyên tắc hoạt động
Kafka Connect hoạt động sử dụng các worker (các tiến trình Java chịu trách nhiệm chạy connector và các task cấu thành của chúng).
Những worker này có thể được triển khai theo hai chế độ:
- Chế độ Standalone: Một tiến trình worker duy nhất hữu ích cho phát triển hoặc các trường hợp sử dụng quy mô nhỏ.
- Chế độ Distributed: Nhiều tiến trình worker làm việc cùng nhau như một cụm.
Chế độ này cung cấp khả năng chịu lỗi, cân bằng tải và khả năng mở rộng theo chiều ngang, làm cho nó phù hợp với môi trường sản xuất.
Chế độ distributed đặc biệt có giá trị vì nó giúp connector mở rộng liền mạch và phục hồi từ lỗi mà không cần can thiệp thủ công.
Ví dụ: Một công ty retail có 100 cửa hàng, mỗi cửa hàng có một database PostgreSQL riêng. Thay vì viết 100 ứng dụng riêng biệt để đồng bộ dữ liệu về trung tâm, họ sử dụng Kafka Connect với JDBC Source Connector.
Chế độ distributed tự động phân phối việc đọc dữ liệu từ các database này nên đảm bảo nếu một worker bị lỗi, các worker khác sẽ tiếp quản công việc.
Thành phần của Kafka Connect
Connector Plugin
Connector là các module phần mềm được đóng gói (thường là file JAR) thực hiện logic cần thiết để kết nối với các hệ thống bên ngoài cụ thể.
Ví dụ: một JDBC connector giúp Kafka Connect nhập dữ liệu từ cơ sở dữ liệu quan hệ, trong khi một S3 connector xử lý việc đọc từ hoặc ghi vào Amazon S3 storage.
Những plugin này đóng gói các chi tiết giao thức và xử lý dữ liệu cần thiết cho mỗi hệ thống.
Vì vậy giúp người dùng tập trung vào thiết kế pipeline thay vì các tác vụ tích hợp cấp thấp.
Task
Mỗi instance connector có thể được chia nhỏ thành nhiều task, trong đó mỗi task xử lý một phần dữ liệu.
Do đó nâng cao thông lượng và khả năng mở rộng bằng cách phân phối khối lượng công việc qua nhiều thread hoặc worker node.
Ví dụ: một task có thể xử lý một partition của Kafka topic hoặc một tập con các bảng cơ sở dữ liệu.
Converter
Converter chịu trách nhiệm dịch các định dạng dữ liệu giữa biểu diễn nội bộ của Kafka Connect (thường là định dạng có cấu trúc như Struct hoặc SchemaAndValue) và các mảng byte thô mà Kafka broker lưu trữ trong topic.
Các converter phổ biến bao gồm:
- JSONConverter: Chuyển đổi dữ liệu sang/từ định dạng JSON.
- AvroConverter: Làm việc với tuần tự hóa Avro và tích hợp với Schema Registry để quản lý schema.
Converter đảm bảo dữ liệu duy trì tính tương thích và cấu trúc khi chảy qua các hệ thống khác nhau.
Single Message Transform (SMT)
SMT hỗ trợ sửa đổi đơn giản trên từng tin nhắn khi chúng đi qua pipeline Kafka Connect mà không cần ứng dụng xử lý stream đầy đủ.
Ví dụ: các thao tác SMT bao gồm thêm trường mới, đổi tên trường hiện có hoặc lọc tin nhắn dựa trên tiêu chí nhất định.
Tính năng này cung cấp tính linh hoạt nhẹ để điều chỉnh dữ liệu một cách linh hoạt trong connector.
Ví dụ: Một công ty có dữ liệu customer từ CRM system với trường “customer_name”, nhưng data warehouse yêu cầu trường “full_name”.
Thay vì thay đổi toàn bộ hệ thống, họ sử dụng SMT để rename trường này trong quá trình data transfer.
Confluent Connector và Confluent Hub
Mặc dù Kafka Connect tự bản thân là mã nguồn mở và rất có khả năng nhưng Confluent mở rộng hệ sinh thái của nó với những cải tiến có giá trị tập trung vào nhu cầu doanh nghiệp:
Confluent Connector
Confluent phát triển một bộ connector được xây dựng sẵn rộng lớn được kiểm tra kỹ lưỡng, tối ưu hóa và được Confluent hỗ trợ đầy đủ.
Những connector này bao phủ các hệ thống phổ biến như cơ sở dữ liệu quan hệ (ví dụ: Oracle, MySQL), nền tảng lưu trữ đám mây (ví dụ: AWS S3), kho lưu trữ key-value, chỉ mục tìm kiếm, ứng dụng SaaS và nhiều hệ thống khác.
Tận dụng connector, doanh nghiệp có được sự tin tưởng vào độ tin cậy, bảo mật và hiệu suất của các tích hợp mà không cần thực hiện từ đầu.
Ví dụ: Một công ty khởi nghiệp fintech cần tích hợp với Salesforce để thu thập dữ liệu khách hàng. Thay vì mất 2-3 tháng để phát triển tích hợp tùy chỉnh và giải quyết độ phức tạp của API, giới hạn tốc độ, xác thực, họ sử dụng Confluent Salesforce Connector và hoàn thành tích hợp trong 2 ngày.
Confluent Hub
Confluent Hub là một marketplace trực tuyến và kho lưu trữ trung tâm nơi người dùng có thể khám phá, tải xuống và quản lý connector cho hàng trăm nguồn và đích đa dạng.
Nó lưu trữ các connector được phát triển bởi Confluent, đối tác và cộng đồng mã nguồn mở.
Portal tập trung đơn giản hóa tìm kiếm connector phù hợp cho nhu cầu và giúp quản lý nâng cấp vòng đời connector một cách hiệu quả.
Connector trên Confluent Cloud
Đối với người dùng Confluent Cloud là dịch vụ Kafka được quản lý đầy đủ.
Confluent cung cấp hơn 120 connector được xây dựng sẵn và được Confluent tự quản lý hoàn toàn.
Điều này có nghĩa là Confluent xử lý các khía cạnh vận hành như mở rộng worker, giám sát sức khỏe, áp dụng bản vá và đảm bảo tính khả dụng cao.
Người dùng chỉ cần cấu hình connector thông qua giao diện thân thiện hoặc API và tập trung vào tích hợp dữ liệu thay vì quản lý cơ sở hạ tầng.
Ví dụ: Một công ty thương mại điện tử cần truyền dữ liệu từ MongoDB (dữ liệu đặt hàng) đến Snowflake (phân tích).
Với các trình kết nối được quản lý hoàn toàn, họ chỉ cần:
- Nhấp vào “Thêm trình kết nối” trong Confluent Cloud UI
- Chọn MongoDB Source và Snowflake Sink
- Nhập chi tiết kết nối
- Nhấp vào “Khởi chạy”
Tự động kết hợp xử lý việc mở rộng quy mô, giám sát, cập nhật nên doanh nghiệp chỉ tập trung vào logic kinh doanh.
Vai trò của Kafka Connect và Confluent Connector
Mặc dù Kafka Connect cung cấp framework mạnh mẽ để xây dựng pipeline.
Tuy nhiên tìm kiếm connector tương thích từ nhiều nguồn, đảm bảo chất lượng và căn chỉnh phiên bản của chúng, cấu hình chúng đúng cách và quản lý vòng đời của chúng có thể là những tác vụ phức tạp và tốn thời gian.
Confluent Hub giải quyết điều này khi cung cấp một nền tảng tập trung để khám phá và quản lý connector.
Quan trọng hơn, connector được hỗ trợ chuyên nghiệp của Confluent giảm rủi ro liên quan đến tích hợp, tăng tốc timeline phát triển và đơn giản hóa bảo trì.
Điều này biến đổi Kafka Connect từ chỉ là một công cụ developer thành một giải pháp “cắm và chạy” sẵn sàng cho doanh nghiệp để tích hợp các hệ thống dữ liệu đa dạng.
Kết quả là, Confluent Kafka trở thành một data hub mạnh mẽ có khả năng kết nối dễ dàng với hệ sinh thái công nghệ phong phú của tổ chức.
Confluent Control Center
Confluent Control Center là gì
Confluent Control Center là một hệ thống quản lý và giám sát dựa trên web cung cấp điểm kiểm soát thống nhất cho các cụm Kafka cùng với các thành phần thiết yếu khác trong hệ sinh thái Confluent.
Nó trao quyền cho người dùng với khả năng quan sát sâu sắc về tình trạng cụm, hiệu suất broker, metrics topic, hành vi consumer và nhiều hơn nữa.
Tất cả đều có thể truy cập thông qua giao diện người dùng đồ họa (GUI) trực quan.
Thông qua tập trung hóa kiểm soát và khả năng quan sát vào một nơi, Control Center đơn giản hóa đáng kể sự phức tạp vận hành của các triển khai Kafka.
Các tính năng chính
Control Center cung cấp một bộ trang và công cụ phong phú được thiết kế để đáp ứng nhu cầu của cả developer và operator:
Tổng quan Cụm
Dashboard này hiển thị trạng thái sức khỏe tổng thể của mọi cụm Kafka đang được quản lý.
Người dùng có thể nhanh chóng xác định liệu các cụm có khỏe mạnh hay đang gặp vấn đề.
Tìm kiếm các cụm cụ thể và đi sâu vào các metrics quan trọng và dịch vụ được kết nối cho mỗi cụm.
Tổng quan Broker
Operator có được thông tin chi tiết về việc sử dụng tài nguyên và phân phối khối lượng công việc trên mọi Kafka broker trong một cụm.
Các metrics như tải CPU, tiêu thụ bộ nhớ, thông lượng mạng và số lượng partition hỗ trợ giám sát chi tiết hiệu suất broker.
Ví dụ: Một team DevOps của công ty fintech phát hiện rằng Broker #3 trong cụm 5-node của họ đang có CPU usage 95% trong khi các broker khác chỉ 30%.
Qua Control Center, họ thấy được rằng broker này đang xử lý quá nhiều phân vùng của chủ đề “giao dịch tần suất cao” và quyết định tái cân bằng các phân vùng để tải đều hơn.
Quản lý Topic
Control Center giúp người dùng tạo, xem, sửa đổi cấu hình và xóa các Kafka topic.
Quan trọng hơn, nó hiển thị metrics sản xuất và tiêu thụ cho mỗi topic, giúp theo dõi thông lượng dữ liệu và độ trễ.
Tích hợp với Schema Registry cũng có nghĩa là các schema liên kết với topic có thể được quản lý trực tiếp từ giao diện.
Quản lý Kafka Connect
Một trong những khả năng nổi bật của Control Center là quản lý liền mạch Kafka Connect.
Người dùng có thể tạo connector mới, chỉnh sửa cấu hình, khởi động, tạm dừng, khởi động lại hoặc giám sát các task connector mà không cần tương tác trực tiếp với API Kafka Connect.
Vì vậy đơn giản hóa đáng kể việc kết nối Kafka với các hệ thống dữ liệu bên ngoài.
Ví dụ: Một data engineer cần thiết lập connector để sync dữ liệu từ MySQL database sang Kafka.
Thay vì phải SSH vào server, chạy curl commands với JSON payloads phức tạp, họ chỉ cần click vào “Add Connector” trong Control Center, chọn JDBC Source Connector từ dropdown, điền database credentials vào form và click “Launch”.
Toàn bộ quá trình giảm từ 30 phút xuống 3 phút.
Phát triển và thực thi truy vấn ksqlDB
Control Center tích hợp giao diện để viết, chạy và quản lý các truy vấn ksqlDB.
Người dùng có thể phát triển các truy vấn SQL streaming, xem kết quả tương tác, tải xuống đầu ra tin nhắn.
Ngoài ra còn có thể quản lý stream và table, kiểm tra schema của chúng.
Giám sát Consumer
Phần này cung cấp thông tin chi tiết về các nhóm consumer đang hoạt động trong một cụm, bao gồm số lượng consumer mỗi nhóm, topic được tiêu thụ bởi mỗi nhóm và quan trọng nhất, metrics consumer lag.
Consumer lag cho biết consumer đang chậm bao xa so với dữ liệu mới nhất trong topic—điều quan trọng để đảm bảo xử lý kịp thời.
Ví dụ: Một team e-commerce nhận thấy consumer lag của “order-processing” group tăng từ 100 messages lên 50,000 messages trong 1 giờ.
Control Center dashboard hiển thị red alert, giúp team nhanh chóng phát hiện rằng một trong các consumer instances đã crash và cần restart.
Nếu không có monitoring này, lag có thể tăng lên hàng triệu messages trước khi được phát hiện.
Control Center hỗ trợ theo dõi end-to-end luồng dữ liệu từ producer đến consumer.
Giám sát này đảm bảo tin nhắn được truyền đáng tin cậy mà không có độ trễ, trùng lặp hoặc mất mát bằng cách đo thời gian tin nhắn di chuyển qua toàn bộ pipeline.
Cảnh báo
Người dùng có thể cấu hình tiêu chí cảnh báo dựa trên các bất thường được quan sát như consumer lag quá mức hoặc độ trễ tin nhắn cao bất thường.
Khi ngưỡng bị vượt qua, Control Center kích hoạt thông báo qua email hoặc tích hợp với hệ thống cảnh báo tập trung trong thời gian thực.
Quản lý Replicator
Chủ yếu trong các triển khai Confluent Platform, tính năng này giám sát và cấu hình sao chép topic qua các cụm Kafka.
Vì thế nó rất hữu ích trong các thiết lập đa trung tâm dữ liệu sử dụng Confluent Replicator.
Nó đảm bảo các topic bản sao duy trì tính nhất quán cấu hình với các topic nguồn của chúng.
Cài đặt Cụm
Quản trị viên có thể xem và sửa đổi thuộc tính cấu hình ở cả cấp độ cụm và cấp độ broker riêng lẻ trực tiếp từ Control Center.
Confluent Health+
Có sẵn với Confluent Platform, công cụ dựa trên web này nâng cao quản lý sức khỏe cụm bằng cách cung cấp cảnh báo thông minh được hỗ trợ bởi phân tích metrics.
Hơn nữa còn được giám sát chủ động và khuyến nghị chuyên gia từ team hỗ trợ Confluent.
Vai trò Confluent Control Center
Theo truyền thống, quản lý Apache Kafka đòi hỏi sử dụng các công cụ dòng lệnh (CLI) và Java Management Extensions (JMX).
Điều này có thể mang lại nhiều khó khăn đối với người dùng không quen thuộc sâu với nội bộ Kafka.
Phụ thuộc vào giao diện kỹ thuật này thường tạo ra rào cản cho các team có trình độ kỹ năng hỗn hợp.
Confluent Control Center phá bỏ những rào cản này bằng cách cung cấp GUI thân thiện với người dùng làm cho các hoạt động phức tạp của Kafka trở nên minh bạch và dễ tiếp cận hơn.
Bằng cách tập trung hóa kiểm soát Kafka broker, topic, connector và ksqlDB stream trong một giao diện, nó giảm nỗ lực cần thiết để chẩn đoán vấn đề hoặc tối ưu hóa hiệu suất.
Hơn nữa, có khả năng quan sát thời gian thực về consumer lag, thông lượng topic và tình trạng cụm tăng tốc khắc phục sự cố.
Do đó giúp duy trì tính khả dụng cao, những yếu tố quan trọng cho pipeline dữ liệu sản xuất.
Đối với doanh nghiệp có team đa dạng từ developer đến nhân viên vận hành, tính năng này thúc đẩy hợp tác và giải quyết vấn đề nhanh hơn.
Control Center không chỉ giám sát, nó hỗ trợ tích cực việc vận hành pipeline dữ liệu sản xuất mà không cần viết mã bổ sung.
Với quản lý tích hợp Kafka Connect và ksqlDB cùng với các thành phần Kafka cốt lõi, người dùng có thể xây dựng, triển khai, quan sát và điều chỉnh ứng dụng streaming tất cả ở một nơi.
Vì thế giảm đáng kể chi phí vận hành bằng cách tinh giản quy trình làm việc.
Team có thể phát hiện nghẽn cổ chai sớm thông qua cơ chế cảnh báo và phản ứng trước khi vấn đề ảnh hưởng đến quy trình kinh doanh.
Thêm vào đó, tích hợp với Schema Registry đảm bảo sự phát triển schema được quản lý an toàn trong topic.
Đây là một tính năng quan trọng cho quản trị dữ liệu và tính tương thích.

Ứng dụng trong thực tế
Phân tích dữ liệu thời gian thực
Phân tích dữ liệu thời gian thực là một trong những ứng dụng phổ biến nhất của Confluent Kafka.
Thay vì xử lý theo lô truyền thống, thu thập và phân tích dữ liệu thành từng khối lớn sau một khoảng thời gian trì hoãn, phân tích dữ liệu thời gian thực giúp doanh nghiệp thu thập, xử lý và diễn giải dữ liệu ngay lập tức khi chúng được tạo ra.
Tính tức thời này giúp doanh nghiệp đưa ra quyết định nhanh hơn, chính xác hơn và có được lợi thế cạnh tranh.
Confluent Kafka hỗ trợ như thế nào
Confluent Kafka hoạt động như hệ thống thần kinh trung ương của các pipeline dữ liệu streaming, nhập dữ liệu từ nhiều nguồn khác nhau và phân phối để xử lý hoặc lưu trữ.
Khả năng thông lượng cao và độ trễ thấp đảm bảo dữ liệu chảy mượt mà với độ trễ tối thiểu.
Một thành phần quan trọng nâng cao khả năng phân tích của Confluent Kafka là ksqlDB, cung cấp giao diện dựa trên SQL để truy vấn dữ liệu streaming.
Điều này có nghĩa là các nhà phân tích và lập trình viên có thể sử dụng cú pháp SQL quen thuộc để lọc, tổng hợp và biến đổi các luồng dữ liệu trực tiếp mà không cần lập trình phức tạp.
Hơn nữa, Confluent Kafka tích hợp tốt với các framework xử lý stream mạnh mẽ như Apache Flink.
Đặc biệt thông qua Confluent Cloud for Apache Flink, cung cấp dịch vụ được quản lý cho các quy trình streaming tinh vi.
Do đó giúp xây dựng các pipeline phức tạp, có khả năng mở rộng để xử lý dữ liệu đang chuyển động một cách hiệu quả.
Các trường hợp sử dụng
Theo dõi hành vi người dùng trên Website và ứng dụng di động
Phân tích tương tác người dùng theo thời gian thực, các công ty thu được những thông tin quý giá về cách khách hàng tương tác với sản phẩm.
Điều này tạo ra những trải nghiệm cá nhân hóa như gợi ý phù hợp, khuyến mãi được nhắm mục tiêu hoặc điều chỉnh nội dung động nhằm cải thiện sự hài lòng và giữ chân người dùng.
Ví dụ: Netflix sử dụng phân tích thời gian thực để theo dõi hành vi xem của người dùng và điều chỉnh thuật toán gợi ý ngay lập tức, giúp tăng thời gian xem và sự gắn kết của người dùng.
Phân tích Log để giám sát hệ thống và debug
Streaming log từ các ứng dụng và hạ tầng vào Confluent Kafka giúp đội ngũ IT phát hiện sớm các vấn đề, theo dõi xu hướng hiệu suất và khắc phục sự cố trước khi chúng leo thang.
Cách tiếp cận chủ động này giảm thời gian ngưng hoạt động và tăng cường độ tin cậy của hệ thống.
Ví dụ: Uber sử dụng hệ thống phân tích log thời gian thực để giám sát hàng nghìn dịch vụ vi mô, phát hiện và xử lý sự cố trong vòng vài giây thay vì vài phút như trước đây.
Giám sát dữ liệu cảm biến IoT trong sản xuất và thành phố thông minh
Các ngành sử dụng thiết bị IoT như nhà máy sản xuất theo dõi tình trạng máy móc hoặc thành phố thông minh giám sát điều kiện môi trường hưởng lợi từ thu thập dữ liệu cảm biến thời gian thực qua Confluent Kafka.
Xử lý tức thời giúp phát hiện bất thường, kích hoạt cảnh báo và tự động hóa phản ứng với các sự kiện quan trọng.
Ví dụ: General Electric (GE) triển khai hệ thống giám sát turbine gió thời gian thực, có thể dự đoán sự cố trước 2-3 tuần và giảm chi phí bảo trì lên đến 25%.
Những ví dụ này cho thấy cách Confluent Kafka giúp doanh nghiệp biến đổi các luồng dữ liệu thô thành thông tin thông minh có thể hành động khi các sự kiện diễn ra.
Ứng dụng trong ngành Tài chính
Lĩnh vực tài chính là một trong lĩnh vực được ứng dụng nhiều nhất từ khả năng streaming thời gian thực của Confluent Kafka.
Do tính nhạy cảm, khối lượng và tốc độ của các giao dịch tài chính, doanh nghiệp cần những nền tảng có thể cung cấp thông tin tức thời với độ tin cậy không thể thỏa hiệp.
Phát hiện gian lận thời gian thực
Một ứng dụng quan trọng là phát hiện gian lận.
Doanh nghiệp tài chính xử lý hàng triệu giao dịch mỗi giây.
Do đó tạo ra cả cơ hội lẫn thách thức: làm thế nào để xác định các hoạt động đáng nghi ngờ ngay lập tức nhằm ngăn chặn tổn thất.
Confluent Kafka hỗ trợ nhập và phân tích dữ liệu giao dịch thời gian thực kết hợp với các mô hình học máy và thuật toán trí tuệ nhân tạo.
Thiết lập này giúp các ngân hàng và bộ xử lý thanh toán đánh dấu hành vi gian lận ngay lập tức trước khi bất kỳ thiệt hại nào xảy ra.
Ví dụ: EVO Banco, được báo cáo đã giảm tổn thất gian lận hàng tuần lên đến 99% sau khi triển khai hệ thống phát hiện gian lận dựa trên Confluent.
Sự cải thiện đáng kể này thể hiện khả năng của nền tảng trong việc bắt được các mối đe dọa sớm thông qua giám sát liên tục.
Xác minh khách hàng thời gian thực (KYC)
Quy trình Hiểu Biết Khách Hàng (KYC) truyền thống liên quan đến các kiểm tra thủ công dài dòng làm chậm quá trình tích hợp.
Khả năng streaming của Confluent Kafka, các công ty tài chính có thể tích hợp dữ liệu từ nhiều nguồn như hệ thống quản lý quan hệ khách hàng (CRM), cơ sở dữ liệu công cộng và nguồn cấp danh sách đen theo thời gian thực.
Do đó tăng tốc xác minh danh tính trong khi duy trì tuân thủ các yêu cầu pháp lý nghiêm ngặt.
Quy trình KYC nhanh hơn cải thiện trải nghiệm khách hàng mà không hy sinh bảo mật hoặc tuân thủ pháp lý.
Ví dụ: HSBC đã triển khai hệ thống KYC thời gian thực giúp giảm thời gian xác minh khách hàng từ 5-7 ngày xuống còn vài phút, đồng thời tăng độ chính xác lên 98%.
Xử lý giao dịch tài chính
Confluent Kafka xử lý nhiều loại giao dịch tài chính bao gồm thanh toán, hoạt động thẻ tín dụng và giao dịch chứng khoán với độ tin cậy cao và độ trễ cực thấp.
Điều này đảm bảo các giao dịch được xử lý nhanh chóng và chính xác.
Vì thế hỗ trợ tính chất đòi hỏi cao của thị trường tài chính nơi mà ngay cả từng mili giây cũng quan trọng.
Quản lý rủi ro và tuân thủ
Tuân thủ quy định là ưu tiên hàng đầu của doanh nghiệp tài chính.
Confluent Kafka hỗ trợ thông qua duy trì các log chi tiết, có thứ tự của mọi sự kiện giao dịch và hoạt động hệ thống thường được gọi là log kiểm toán.
Những log này rất quan trọng cho kiểm toán nội bộ, báo cáo cho các tiêu chuẩn quy định như PCI DSS (Tiêu Chuẩn Bảo Mật Dữ Liệu Ngành Thẻ Thanh Toán) hoặc AML (Chống Rửa Tiền) và phân tích rủi ro.
Tính năng Audit Logs do Confluent cung cấp đóng vai trò như công cụ quan trọng để đảm bảo tính minh bạch và khả năng truy xuất.
Ví dụ: Moniepoint, một công ty fintech ở châu Phi, đã tận dụng Confluent Cloud để nâng cấp hệ thống quản lý trạng thái giao dịch.
Nâng cấp này giúp Moniepoint xử lý hàng triệu yêu cầu hàng ngày mà không có thời gian ngưng hoạt động.
Ví dụ: JPMorgan Chase sử dụng Confluent Kafka để xử lý hơn 5 tỷ giao dịch mỗi ngày trên toàn cầu, với khả năng phục hồi sau sự cố trong vòng 30 giây và độ chính xác 99.99%.

Bán lẻ và thương mại điện tử
Trong lĩnh vực bán lẻ và thương mại điện tử, hai yếu tố quan trọng quyết định thành công là: mang lại trải nghiệm khách hàng liền mạch và đảm bảo hoạt động hiệu quả.
Confluent Kafka đóng vai trò quan trọng trong khả năng đạt được cả hai mục tiêu này thông qua việc đồng bộ hóa dữ liệu thời gian thực, tương tác cá nhân hóa và hệ thống phản ứng động.
Đồng bộ hóa kho hàng thời gian thực
Quản lý hàng tồn kho trên nhiều kênh bán hàng, cửa hàng vật lý, website, ứng dụng di động và sàn thương mại điện tử là một nhiệm vụ phức tạp.
Confluent Kafka giúp các nhà bán lẻ đồng bộ hóa dữ liệu hàng tồn kho theo thời gian thực trên tất cả các kênh này.
Vì thế giúp tránh những khó khăn thường gặp như hết hàng (bán những mặt hàng không còn sẵn có) hoặc dự trữ quá mức.
Với thông tin hàng tồn kho chính xác được cập nhật tức thì, các nhà bán lẻ có thể tối ưu hóa chuỗi cung ứng.
Do đó giảm lãng phí và cải thiện sự hài lòng của khách hàng thông qua cung cấp thông tin về tình trạng hàng hóa đáng tin cậy.
Các nhà bán lẻ lớn như Walmart tận dụng Kafka và các giải pháp của Confluent để xử lý khối lượng lớn dữ liệu giao dịch khách hàng.
Họ sử dụng thông tin này để điều chỉnh giá cả một cách linh hoạt và đưa ra các gợi ý sản phẩm cá nhân hóa dựa trên hành vi khách hàng thời gian thực.
Các nhà bán lẻ lớn khác như Sainsbury’s và Dollar General cũng đã áp dụng Confluent Kafka cho mục đích tương tự, chứng minh hiệu quả của nó ở quy mô lớn.
Cá nhân hóa trải nghiệm khách hàng
Một ứng dụng quan trọng khác là cá nhân hóa trải nghiệm khách hàng.
Confluent Kafka thu thập dữ liệu từ nhiều tương tác của người dùng như lịch sử duyệt web, sản phẩm đã xem, giỏ hàng, lịch sử mua hàng và xử lý ngay lập tức.
Điều này giúp các nhà bán lẻ đưa ra những khuyến mãi, giảm giá, nội dung và chương trình khách hàng thân thiết được tùy chỉnh cao theo sở thích cá nhân.
Thông qua cung cấp các ưu đãi và trải nghiệm phù hợp theo thời gian thực, các nhà bán lẻ có thể tăng sự tương tác, khuyến khích mua hàng lặp lại và xây dựng lòng trung thành khách hàng mạnh mẽ hơn.
Ví dụ: Amazon sử dụng hệ thống tương tự để hiển thị “Khách hàng cũng đã mua” và “Được đề xuất cho bạn” trong thời gian thực, giúp tăng doanh số lên 35% từ các gợi ý sản phẩm.
Khôi phục giỏ hàng bị bỏ rơi
Bỏ giỏ hàng vẫn là một thách thức đáng kể trong thương mại điện tử.
Confluent Kafka hỗ trợ theo dõi hành vi người dùng trên các nền tảng mua sắm theo thời gian thực.
Khi người dùng thêm sản phẩm vào giỏ hàng nhưng rời đi mà không hoàn tất việc mua, hệ thống có thể kích hoạt các thông báo nhắc nhở cá nhân hóa kịp thời như email nhắc nhở hoặc mã giảm giá.
Chiến lược khôi phục có mục tiêu này giúp chuyển đổi những doanh số có thể bị mất thành các giao dịch hoàn tất thông qua tương tác lại với khách hàng một cách hiệu quả.
Ví dụ: Shopify cho biết các thương hiệu sử dụng hệ thống khôi phục giỏ hàng thời gian thực có thể thu hồi lại 15-25% số đơn hàng bị bỏ rơi.
Công cụ gợi ý thời gian thực
Sử dụng kiến trúc hướng sự kiện của Kafka, các nền tảng thương mại điện tử có thể phân tích hành động của người dùng như nhấp chuột, tìm kiếm và xem sản phẩm một cách tức thì.
Những thông tin này được đưa vào công cụ gợi ý để đề xuất các sản phẩm phù hợp ngay khi người dùng đang duyệt.
Khả năng này thúc đẩy việc khám phá sản phẩm và tăng doanh số thông qua trình bày cho khách hàng những lựa chọn hấp dẫn chính xác vào thời điểm họ có khả năng mua nhất.
Ví dụ: L’Oréal, công ty này dựa vào nền tảng này để hỗ trợ các nhu cầu vận hành nhạy cảm về thời gian trong toàn bộ hoạt động kinh doanh mỹ phẩm toàn cầu của mình.
Kiến trúc Microservices hướng sự kiện
Confluent Kafka thường đóng vai trò như hệ thống thần kinh trung ương cho các kiến trúc microservices hướng sự kiện thông qua hỗ trợ giao tiếp bất đồng bộ giữa các dịch vụ độc lập.
Hỗ trợ điều phối dịch vụ
Thay vì có một bộ điều phối tập trung chỉ đạo tất cả các dịch vụ, microservices hướng sự kiện sử dụng mô hình điều phối nơi mỗi dịch vụ lắng nghe các sự kiện được phát ra bởi các dịch vụ khác và hành động tương ứng.
Kafka hoạt động như xương sống tin nhắn đáng tin cậy để vận chuyển những sự kiện này.
Cách tiếp cận này giảm sự ghép nối chặt chẽ giữa các dịch vụ và tăng cường khả năng mở rộng vì các dịch vụ có thể phát triển độc lập mà không cần phối hợp trực tiếp.
Tăng tính độc lập và linh hoạt
Vì các microservices tương tác thông qua các sự kiện được định nghĩa rõ ràng trên các chủ đề Kafka, mỗi dịch vụ có thể được phát triển, triển khai, nâng cấp và mở rộng theo lịch trình riêng mà không làm gián đoạn các dịch vụ khác.
Tính mô-đun này cải thiện sự nhanh nhẹn và khả năng phục hồi trong các hệ thống phức tạp.
Nhiều doanh nghiệp dựa vào khả năng xử lý sự kiện của Kafka để xây dựng microservices phản ứng nhanh với các yêu cầu thay đổi trong khi duy trì sự ổn định của hệ thống.
Ví dụ: Netflix sử dụng kiến trúc microservices với Kafka để quản lý hơn 700 dịch vụ độc lập, xử lý hàng tỷ sự kiện mỗi ngày và đảm bảo thời gian hoạt động 99.99%.

Các ngành công nghiệp khác
Ngoài bán lẻ và kiến trúc microservices, Confluent Kafka được áp dụng rộng rãi trong nhiều ngành công nghiệp khác nơi mà xử lý dữ liệu thời gian thực là yếu tố then chốt.
Viễn thông
Các công ty như Intrado đã hiện đại hóa hệ thống hội nghị của họ thông qua chuyển đổi sang kiến trúc hướng sự kiện được hỗ trợ bởi Confluent Platform và Confluent Cloud.
Sự chuyển đổi này đã nâng cao hiệu suất và khả năng mở rộng cho các dịch vụ truyền thông của họ.
Ví dụ: Verizon sử dụng Confluent Kafka để xử lý hơn 50 tỷ sự kiện mạng mỗi ngày, giúp tối ưu hóa hiệu suất mạng và phát hiện sự cố trong thời gian thực.
Chăm sóc sức khỏe
Các nhà cung cấp dịch vụ chăm sóc sức khỏe sử dụng Confluent Kafka để tích hợp dữ liệu bệnh nhân từ hồ sơ y tế điện tử (EMR), thiết bị đeo và hệ thống quản lý phòng khám.
Do đó đảm bảo dữ liệu được cập nhật theo thời gian thực trong khi duy trì sự tuân thủ với các quy định bảo mật nghiêm ngặt như HIPAA.
Chứng nhận HITRUST của Confluent càng khẳng định tính phù hợp của nó cho môi trường dữ liệu chăm sóc sức khỏe nhạy cảm.
Nhiều tổ chức y tế xây dựng các giải pháp “Góc Nhìn Đơn Lẻ Bệnh Nhân” để tổng hợp tất cả thông tin bệnh nhân thành một luồng thống nhất để cải thiện quản lý chăm sóc.
Ví dụ: Mayo Clinic triển khai hệ thống theo dõi bệnh nhân thời gian thực giúp giảm thời gian chờ đợi 40% và cải thiện chất lượng chăm sóc thông qua cảnh báo sớm về biến chứng.
Sản xuất
Các nhà sản xuất như BAADER tận dụng Kafka cho các dự án chuyển đổi số tập trung vào giám sát sản xuất, bảo trì dự đoán thiết bị và tối ưu hóa chuỗi cung ứng.
Các luồng dữ liệu thời gian thực giúp họ phát hiện vấn đề sớm và tối ưu hóa quy trình vận hành một cách hiệu quả.
Ví dụ: Siemens sử dụng Confluent Kafka để kết nối hơn 100,000 cảm biến trong các nhà máy toàn cầu, giúp giảm thời gian ngưng máy không kế hoạch xuống 30%.
Internet of Things (IoT)
Triển khai IoT thường tạo ra khối lượng dữ liệu cảm biến khổng lồ từ hàng triệu thiết bị.
Confluent Kafka là lựa chọn phổ biến để thu thập, xử lý và phân tích dữ liệu này một cách nhanh chóng nhằm hỗ trợ cảnh báo sớm, cải thiện vận hành và các dịch vụ thông minh mới.
Ví dụ: Tesla sử dụng hệ thống tương tự để thu thập dữ liệu từ hàng triệu xe điện, giúp cải thiện tính năng tự lái và dự đoán nhu cầu bảo trì.
Logistics và vận tải
Công ty logistics dựa vào Kafka để theo dõi vị trí xe, tình trạng đội xe và điều kiện hàng hóa theo thời gian thực.
Khả năng này giúp tối ưu hóa tuyến đường, cải thiện dịch vụ khách hàng thông qua ước tính giao hàng chính xác và quản lý tài sản hiệu quả hơn.
Ví dụ: FedEx triển khai hệ thống theo dõi gói hàng thời gian thực xử lý hơn 15 triệu sự kiện mỗi ngày, giúp tăng độ chính xác dự đoán thời gian giao hàng lên 95% và giảm khiếu nại khách hàng 60%.
Có thể bạn quan tâm











Liên hệ

Địa chỉ
Tầng 3 Toà nhà VNCC
243A Đê La Thành Str
Q. Đống Đa-TP. Hà Nội


info@comlink.com.vn

Phone
+84 98 58 58 247