


TensorRT-LLM là gì
TensorRT-LLM là thư viện mã nguồn mở cho phép định nghĩa, tối ưu hóa và thực thi các mô hình ngôn ngữ lớn trong quá trình suy luận ở môi trường sản xuất.
Thư viện này duy trì chức năng cốt lõi của FasterTransformer, kết hợp với TensorRT’s Deep Learning Compiler, trong một API Python mã nguồn mở để nhanh chóng hỗ trợ các mô hình và tùy chỉnh mới.
Nvidia® TensorRT™, một SDK cho suy luận deep learning hiệu năng cao, bao gồm bộ tối ưu hóa suy luận deep learning và môi trường thực thi mang lại độ trễ thấp và khả năng xử lý cao cho các ứng dụng suy luận.
Những chức năng chính
Định nghĩa, tối ưu và thực thi các mô hình ngôn ngữ lớn (LLM)
TensorRT-LLM là một thư viện mã nguồn mở giúp định nghĩa, tối ưu và thực thi các mô hình ngôn ngữ lớn (LLM) trong quá trình suy luận trong môi trường sản xuất.
Thư viện này giữ các chức năng cốt lõi của FasterTransformer và kết hợp với TensorRT’s Deep Learning Compiler thông qua một API Python mã nguồn mở để nhanh chóng hỗ trợ các mô hình và tùy chỉnh mới.
Tăng tốc quá trình suy luận lên đến 36 lần
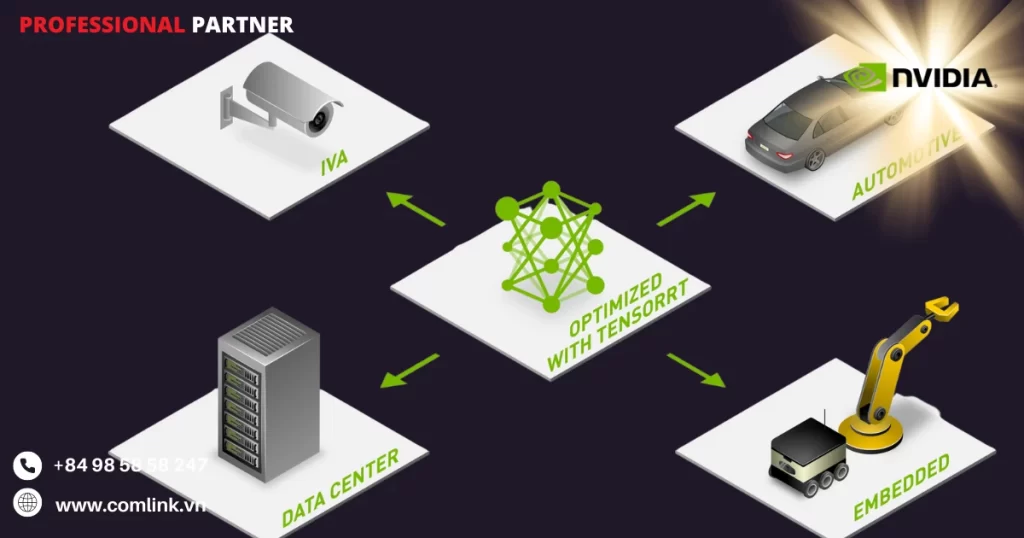
Ứng dụng dựa trên Nvidia TensorRT có thể thực hiện quá trình suy luận lên đến 36 lần nhanh hơn so với các nền tảng chỉ sử dụng CPU.
Điều này giúp tối ưu hóa các mô hình mạng nơ-ron được huấn luyện trên tất cả các khung công việc chính, hiệu chỉnh để đạt độ chính xác cao với độ chính xác cao và triển khai trên các trung tâm dữ liệu quy mô lớn, các nền tảng nhúng hoặc sản phẩm ô tô.

Tối ưu hiệu suất suy luận
TensorRT, được xây dựng trên mô hình lập trình song song Nvidia Cuda, cho phép tối ưu hiệu suất suy luận bằng cách sử dụng các kỹ thuật như lượng tử hóa, kết hợp lớp và tensor, điều chỉnh kernel và các kỹ thuật khác trên GPU Nvidia.
Điều này giúp gia tăng hiệu suất suy luận của các ứng dụng sử dụng deep learning như video streaming, giới thiệu, phát hiện gian lận và xử lý ngôn ngữ tự nhiên.
Tăng tốc cho mọi công việc
TensorRT cung cấp hỗ trợ INT8 bằng cách sử dụng huấn luyện nhận thức lượng tử và lượng tử sau quá trình huấn luyện, cùng với tối ưu hóa số thực dấu phẩy động 16 (FP16).
Chức năng này dùng để triển khai các ứng dụng suy luận deep learning như video streaming, giới thiệu, phát hiện gian lận và xử lý ngôn ngữ tự nhiên.
Suy luận với độ chính xác thấp làm giảm đáng kể thời gian trễ, điều này yêu cầu cho nhiều dịch vụ thời gian thực cũng như các ứng dụng tự động và nhúng.
Triển khai, chạy và mở rộng với Triton
Các mô hình được tối ưu hóa bằng TensorRT có thể triển khai, chạy và mở rộng thông qua Nvidia Triton, một phần mềm phục vụ suy luận mã nguồn mở bao gồm TensorRT làm backend.
Các ưu điểm của việc sử dụng Triton bao gồm khả năng xử lý thông qua batch động và thực thi đồng thời của nhiều mô hình cùng một lúc, cũng như các tính năng như kết hợp mô hình, đầu vào âm thanh/video theo luồng và nhiều tính năng khác.
TensorRT-LLM cung cấp khả năng gia tăng hiệu suất và tùy chỉnh nhanh chóng cho LLMs mới, mà không yêu cầu kiến thức sâu về C++ hoặc CUDA.

Lợi ích của việc sử dụng TensorRT-LLM
Tăng tốc hiệu suất phân giải lên đến 36 lần
Một trong những lợi ích quan trọng nhất của TensorRT-LLM là khả năng tăng tốc hiệu suất phân giải mô hình LLM lên đến 36 lần so với chỉ sử dụng CPU.
Điều này cho phép bạn tối ưu hóa các mô hình học sâu được huấn luyện trên các framework phổ biến như PyTorch và TensorFlow và triển khai chúng trên các môi trường như trung tâm dữ liệu, nhúng và ô tô.
Với sự kết hợp giữa TensorRT-LLM và Nvidia CUDA, bạn có thể tận dụng các kỹ thuật như quantization-aware training (huấn luyện có tính toán số nguyên) và post-training quantization (tối ưu hóa sau huấn luyện) để giảm độ chính xác của mô hình nhưng vẫn đảm bảo độ chính xác cao.
Điều này rất hữu ích cho các ứng dụng thời gian thực và các ứng dụng tự động hoá và nhúng.
Tối ưu hóa hiệu suất phân giải thông qua quantization, layer fusion và kernel tuning
TensorRT-LLM được xây dựng trên nền tảng Nvidia CUDA, cho phép bạn tối ưu hóa hiệu suất phân giải của mô hình bằng cách sử dụng các kỹ thuật như quantization, layer fusion và kernel tuning.
Công nghệ quantization-aware training cho phép bạn huấn luyện mô hình với tính toán số nguyên, giúp giảm bộ nhớ và tăng tốc độ tính toán.
Sau đó, bạn có thể áp dụng post-training quantization để tiếp tục giảm kích thước mô hình và tăng tốc độ phân giải.
Layer fusion cho phép bạn kết hợp các layer của mô hình thành một layer duy nhất để giảm số lượng phép tính cần thiết.
Điều này cũng giúp giảm bộ nhớ yêu cầu và tăng tốc độ phân giải.
Cuối cùng, kernel tuning cho phép bạn điều chỉnh các tham số của kernel để đạt được hiệu suất phân giải tối ưu trên GPU Nvidia.
Triển khai, chạy và mở rộng với Triton
TensorRT-LLM cho phép triển khai, chạy và mở rộng các mô hình được tối ưu hoá bằng Nvidia Triton – một phần mềm phục vụ phân giải mã nguồn mở bao gồm TensorRT làm backend.
Sử dụng Triton, bạn có thể tận dụng công nghệ dynamic batching và concurrent model execution để đạt được hiệu suất cao khi xử lý hàng loạt các yêu cầu.
Ngoài ra, Triton cung cấp nhiều tính năng khác như model ensembles (kết hợp nhiều mô hình), streaming audio/video inputs (đầu vào âm thanh/video theo luồng), và nhiều hơn nữa.
Triton cũng tích hợp với các SDK cụ thể cho từng ứng dụng như Nvidia DeepStream, Nvidia Riva, Nvidia Merlin, Nvidia Maxine, Nvidia Morpheus và Nvidia Broadcast Engine.
Điều này mang lại một con đường thống nhất để triển khai video analytics thông minh, AI xử lý tiếng nói, hệ thống gợi ý, video conference, AI dựa trên an ninh mạng và các ứng dụng streaming trong quá trình sản xuất.

Hỗ trợ cho các framework phổ biến
TensorRT-LLM tích hợp sẵn với PyTorch và TensorFlow, hai framework deep learning phổ biến nhất hiện nay.
Điều này cho phép bạn đạt được hiệu suất phân giải gấp 6 lần chỉ với một dòng code duy nhất.
Nếu bạn đang sử dụng một framework riêng hoặc tự thiết kế, bạn cũng có thể sử dụng TensorRT C++ API để nhập và tăng tốc mô hình của mình.
Với việc tích hợp sẵn với các framework phổ biến và khả năng sử dụng API C++, TensorRT-LLM rất linh hoạt và có thể được áp dụng vào nhiều loại ứng dụng deep learning.
Triển khai trên nhiều môi trường
Cuối cùng, TensorRT-LLM cho phép triển khai và chạy các ứng dụng LLM trên nhiều môi trường khác nhau, từ trung tâm dữ liệu cho đến các môi trường nhúng và ô tô.
Bạn có thể triển khai các ứng dụng LLM được tối ưu hoá bằng TensorRT-LLM trên các máy chủ GPU trong trung tâm dữ liệu để đạt được hiệu suất cao nhất.
Đồng thời, bạn cũng có thể triển khai chúng trên các máy tính cá nhân và máy tính xách tay sử dụng GPU Nvidia RTX System để có được quá trình làm việc liền mạch.
TensorRT-LLM cung cấp cho bạn một luồng công việc đơn giản trong Python để xác định, tối ưu hoá và chạy các mô hình LLM cho quá trình phân giải trong sản xuất.
Bạn không cần có kiến thức sâu về C++ hoặc Cuda để sử dụng TensorRT-LLM.
Gia tăng hiệu suất suy luận
Sử dụng INT8 và FP16 optimizations
TensorRT-LLM hỗ trợ số nguyên 8 bits (INT8) và số thực 16 bits (FP16) để gia tăng hiệu suất suy luận.
Bạn có thể tận dụng tính năng này bằng cách huấn luyện mô hình với định quy nhận thức hoặc định quy sau quá trình huấn luyện để chuyển đổi sang định dạng số nguyên 8 bits hoặc số thực 16 bits.
Tối ưu hoá kernel và tensor fusion
TensorRT-LLM sử dụng các kỹ thuật tối ưu hoá như quantization, layer and tensor fusion, kernel tuning… để gia tăng hiệu suất suy luận.
Bạn có thể tận dụng các tính năng này để tối ưu hoá mô hình của mình và giảm thiểu độ trễ trong quá trình suy luận.

Sử dụng Triton để triển khai và mở rộng
Triton, phần mềm phục vụ suy luận mã nguồn mở do Nvidia phát triển, cung cấp công suất xử lý cao với dynamic batching và concurrent model execution.
Bằng cách triển khai và mở rộng mô hình của bạn với Triton, bạn có thể tận dụng được công suất xử lý cao này và đạt được hiệu suất suy luận tối ưu.
Thực hiện quá trình suy luận
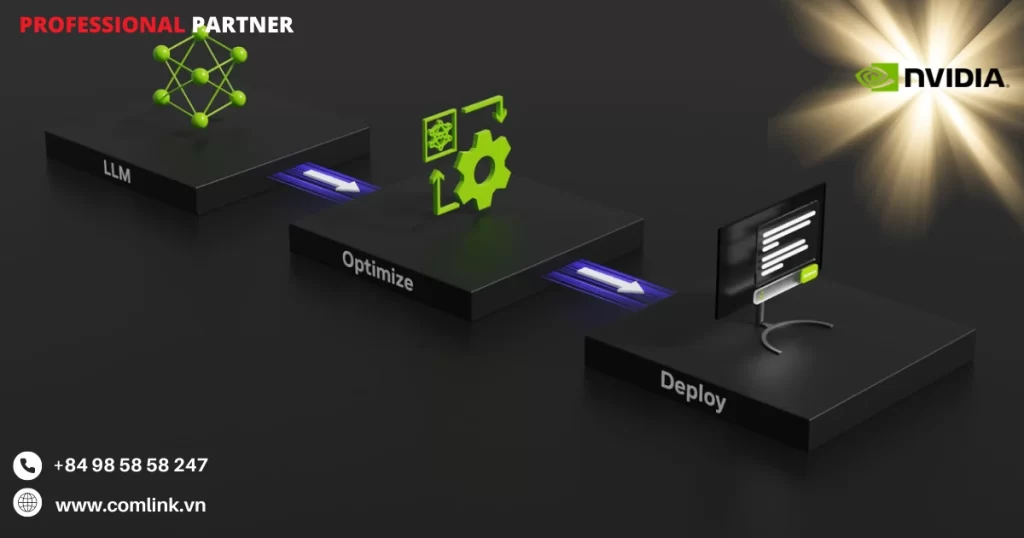
Định nghĩa mô hình LLM
Sử dụng API Python của TensorRT-LLM để định nghĩa mô hình LLM cho quá trình suy luận.
Bạn có thể sử dụng các tính năng và công cụ tối ưu hoá có sẵn trong thư viện này để tối ưu hoá mô hình của mình.
Tối ưu hoá mô hình
Sau khi định nghĩa mô hình, bạn có thể tối ưu hoá mô hình sử dụng các tính năng như quantization, layer and tensor fusion, kernel tuning… để gia tăng hiệu suất suy luận.
Triển khai và chạy mô hình với Triton
Cuối cùng, bạn có thể triển khai và chạy mô hình của mình với Triton để tận dụng công suất xử lý cao và đạt được hiệu suất suy luận tối ưu.
Tối ưu hóa suy luận
Quantization
Sử dụng quantization-aware training và post-training quantization để chuyển đổi mô hình sang số nguyên 8 bits (INT8) hoặc số thực 16 bits (FP16) để gia tăng hiệu suất suy luận.
Layer and tensor fusion
Tối ưu hoá mô hình bằng cách tổ hợp các lớp và tensor có liên quan để giảm thiểu độ trễ trong quá trình suy luận.
Kernel tuning
Tối ưu hoá các kernel sử dụng trong quá trình suy luận để đạt được hiệu suất cao nhất trên GPU Nvidia.
Sử dụng Triton để triển khai và mở rộng
Triton cung cấp công suất xử lý cao với dynamic batching và concurrent model execution.
Bằng cách triển khai và mở rộng mô hình của bạn với Triton, bạn có thể tận dụng được công suất xử lý cao này và đạt được hiệu suất suy luận tối ưu.

Triển khai và mở rộng với Triton
Triển khai mô hình với Triton
Sau khi đã định nghĩa và tối ưu hoá mô hình của mình, bạn có thể triển khai mô hình với Triton.
Điều này để tận dụng công suất xử lý cao và đạt được hiệu suất suy luận tối ưu.
Mở rộng mô hình với Triton
Triton cung cấp công suất xử lý cao với dynamic batching và concurrent model execution.
Bằng cách mở rộng mô hình của bạn với Triton, bạn có thể tận dụng được công suất xử lý cao này và đạt được hiệu suất suy luận tối ưu.
Có thể bạn quan tâm










Liên hệ

Địa chỉ
Tầng 6 184 Phương Liệt
Phường Phương Liệt
Thành phố. Hà Nội


info@comlink.com.vn

Phone
+84 98 58 58 247