


Máy tính hiệu năng cao là gì
Máy tính hiệu năng cao là máy tính có khả năng xử lý các tập dữ liệu khổng lồ và vận hành các ứng dụng tính toán chuyên sâu mà không gặp bị gián đoạn hay quá tải.
Máy tính hiệu năng cao có khả năng phân tích dữ liệu và thực hiện các phép tính phức tạp ở tốc độ cực cao, vượt xa giới hạn của máy tính thông thường.
Nó đã trở thành một công cụ không thể thiếu để đẩy nhanh quá trình nghiên cứu khoa học, thúc đẩy đổi mới công nghệ và cải thiện hiệu suất làm việc trong hầu hết mọi ngành công nghiệp, từ y sinh, tài chính đến kỹ thuật và giải trí.

So sánh với các dạng máy tính khác
| Tiêu chí | Hệ thống HPC (Siêu máy tính) |
Máy chủ Doanh nghiệp (Server) |
Máy tính Cá nhân (PC/Workstation) |
|---|---|---|---|
| Đơn vị hiệu năng | PetaFLOPS, ExaFLOPS | Giao dịch/giây (TPS), Yêu cầu/giây | GigaFLOPS |
| Kiến trúc xử lý | Xử lý song song hàng loạt (MPP) | Client-Server, Xử lý giao dịch | Xử lý tuần tự, đa nhiệm cơ bản |
| Quy mô hệ thống | Hàng trăm đến hàng nghìn nút (máy chủ) | Một đến vài chục máy chủ | Một máy duy nhất |
| Mục đích sử dụng chính | Mô phỏng khoa học, huấn luyện AI, phân tích dữ liệu lớn | Lưu trữ web, cơ sở dữ liệu, ứng dụng doanh nghiệp | Công việc văn phòng, giải trí, thiết kế đồ họa |
| Chi phí điển hình | Hàng triệu đến hàng trăm triệu USD | Hàng nghìn đến hàng chục nghìn USD | Vài trăm đến vài nghìn USD |
| Độ tin cậy | Rất cao, có khả năng chịu lỗi node (fault tolerance) | Cao, thiết kế hoạt động 24/7, có RAM ECC | Phụ thuộc vào linh kiện, không thiết kế cho hoạt động 24/7 |
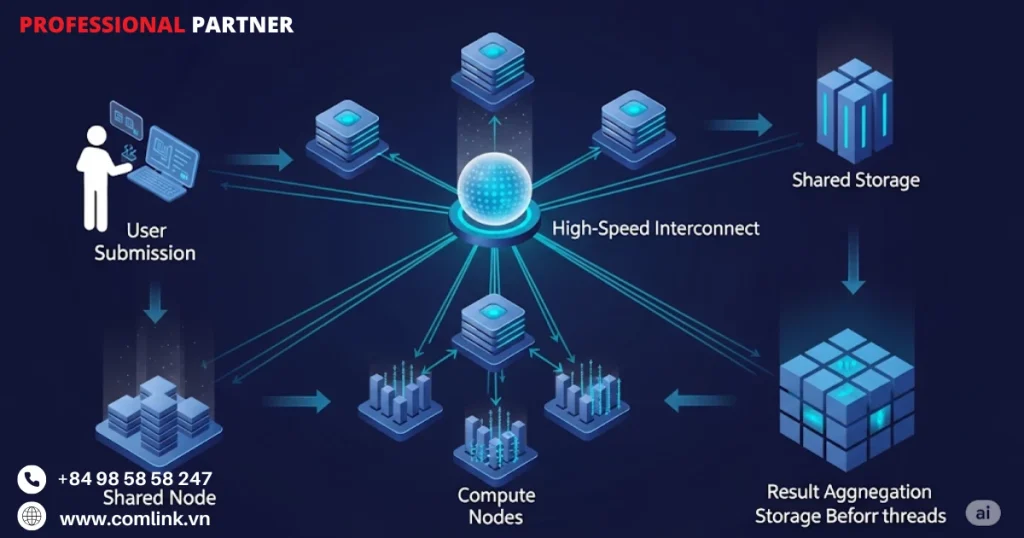
Nguyên lý vận hành
Hệ thống bộ nhớ chia sẻ
Hãy tưởng tượng bạn và các đồng nghiệp đang làm việc trên một bảng trắng khổng lồ, nơi mọi người có thể xem và viết đồng thời.
Hình ảnh này thể hiện chính xác bản chất của hệ thống bộ nhớ chia sẻ trong HPC.
Trong hệ thống bộ nhớ chia sẻ, tất cả các bộ xử lý thường là nhiều lõi trong một CPU duy nhất hoặc các CPU trên cùng một bo mạch chủ đều truy cập vào cùng một không gian bộ nhớ vật lý, thông thường là RAM.
Như vậy có nghĩa mỗi lõi hoặc bộ xử lý có thể đọc và ghi vào cùng các biến hoặc cấu trúc dữ liệu một cách trực tiếp mà không cần gửi thông điệp hay phối hợp thông qua các kênh truyền thông.
Khả năng truy cập chung này giúp đơn giản hóa giao tiếp giữa các luồng xử lý vì chúng có thể ngay lập tức nhìn thấy những thay đổi mà các luồng khác thực hiện trên dữ liệu chung.
Mô hình này cực kỳ hiệu quả cho những tác vụ cần trao đổi dữ liệu thường xuyên và nhanh chóng giữa các đơn vị xử lý.
Để khai thác sức mạnh của bộ nhớ chia sẻ trong HPC, các lập trình viên thường sử dụng OpenMP.
OpenMP là một giao diện lập trình ứng dụng (API) giúp các nhà phát triển song song hóa các phần của mã nguồn một cách dễ dàng trong các ngôn ngữ như C, C++ và Fortran.
Thay vì viết lại toàn bộ chương trình, lập trình viên chỉ cần thêm các chỉ thị đặc biệt, gọi là pragma trước các vòng lặp hoặc khối mã mà họ muốn chạy song song.
Khi những chỉ thị này được thêm vào, trình biên dịch sẽ đảm nhận tạo ra nhiều luồng và phân phối các tác vụ trên các lõi CPU có sẵn.
Cách tiếp cận này giúp chuyển đổi chương trình tuần tự thành chương trình song song trở nên đơn giản mà không cần tái cấu trúc mã nguồn phức tạp.
Điểm mạnh của OpenMP nằm ở tính đơn giản và hiệu quả trong phạm vi một máy tính hoặc nút duy nhất có bộ nhớ chia sẻ.
Tuy nhiên, hạn chế của nó là không thể mở rộng hiệu quả vượt ra ngoài một máy tính vật lý vì nó phụ thuộc vào các bộ xử lý chia sẻ một không gian bộ nhớ chung.
Ví dụ: Trong xử lý hình ảnh, khi cần áp dụng bộ lọc làm mờ cho một bức ảnh 4K, OpenMP có thể chia ảnh thành các dải ngang và giao mỗi lõi CPU xử lý một dải.
Vì tất cả các lõi đều truy cập cùng một mảng pixel trong RAM, chúng có thể đọc và ghi dữ liệu ngay lập tức mà không cần chờ đợi.
Hệ thống bộ nhớ phân tán
Bây giờ hãy tưởng tượng một nhóm mà mỗi thành viên có sổ tay riêng thay vì một bảng trắng chung.
Khi họ muốn chia sẻ thông tin, họ phải gửi thư hoặc gọi điện thoại.
Tình huống này phản ánh bản chất của hệ thống bộ nhớ phân tán trong HPC.
Trong kiến trúc bộ nhớ phân tán, mỗi bộ xử lý (thường nằm trên các máy tính vật lý riêng biệt hoặc các nút trong một cụm máy tính) có không gian bộ nhớ riêng tư của mình.
Các bộ xử lý không thể truy cập trực tiếp vào bộ nhớ của nhau.
Thay vào đó, chúng phải giao tiếp một cách rõ ràng thông qua gửi và nhận thông điệp qua mạng.
Kiến trúc này giúp các hệ thống HPC có thể phát triển lớn hơn nhiều so với hệ thống bộ nhớ chia sẻ vì mỗi nút hoạt động độc lập với tài nguyên riêng của mình.
Tuy nhiên, vấn đề lập trình trở nên phức tạp hơn vì các nhà phát triển phải quản lý trao đổi dữ liệu một cách thủ công.
Tiêu chuẩn được chấp nhận rộng rãi nhất để lập trình các hệ thống HPC bộ nhớ phân tán là MPI.
MPI không phải là một ngôn ngữ lập trình mà là một tập hợp các hàm thư viện được chuẩn hóa để gửi và nhận dữ liệu giữa các tiến trình độc lập chạy trên các nút khác nhau.
Mỗi tiến trình MPI thường chạy trên nút riêng với bộ nhớ chuyên dụng.
Lập trình viên phải xử lý một cách rõ ràng đóng gói dữ liệu, truyền tải, mở gói và đồng bộ hóa để đảm bảo tất cả các nút giao tiếp chính xác và hiệu quả.
Mặc dù điều này tăng thêm độ phức tạp so với lập trình bộ nhớ chia sẻ, MPI lại mạnh hơn về khả năng mở rộng.
Nó giúp các chương trình HPC chạy trên hàng nghìn hoặc thậm chí hàng trăm nghìn nút.
Khả năng này chính là động lực của một số siêu máy tính lớn nhất thế giới, khiến MPI trở thành công cụ không thể thiếu cho các mô phỏng khoa học và xử lý dữ liệu quy mô lớn.
Ví dụ: Trong dự báo thời tiết toàn cầu, các mô hình khí hậu được chia thành các vùng địa lý. Mỗi nút trong cụm máy tính tính toán điều kiện thời tiết cho một vùng cụ thể.
Định kỳ, các nút phải trao đổi thông tin về biên giới (như nhiệt độ, áp suất) với các nút láng giềng thông qua MPI.

Mô hình lai để đạt hiệu quả tối đa
Các hệ thống HPC hiện đại thường áp dụng kiến trúc lai kết hợp cả hai mô hình bộ nhớ chia sẻ và phân tán thành một hệ thống gắn kết.
Hãy tưởng tượng một đội ngũ lớn gồm nhiều nhóm nhỏ.
Mỗi nhóm làm việc quanh bảng trắng riêng của mình (bộ nhớ chia sẻ trong một nút), nhưng các nhóm giao tiếp với nhau thông qua thông điệp (bộ nhớ phân tán giữa các nút).
Trong cấu hình này, một hệ thống HPC bao gồm nhiều nút kết nối qua mạng (tạo thành hệ thống bộ nhớ phân tán).
Bên trong mỗi nút là nhiều lõi CPU chia sẻ bộ nhớ cục bộ (tạo thành các hệ thống con bộ nhớ chia sẻ).
Để khai thác tối đa kiến trúc lai này, lập trình viên sử dụng sự kết hợp của MPI và OpenMP, một kỹ thuật được gọi là lập trình lai.
Ở mức cao hơn, MPI xử lý giao tiếp giữa các nút (giao tiếp liên-nút).
Nó quản lý cách các tác vụ được chia sẻ giữa các máy tính khác nhau trong cụm và đảm bảo tính nhất quán của dữ liệu trên các nút này.
Ở mức thấp hơn trong mỗi nút, OpenMP đảm nhận song song hóa các phép tính trên các lõi có sẵn trong nút đó (song song hóa nội-nút).
Vì thế giúp lập trình viên tối đa hóa sử dụng CPU cục bộ mà không phải chịu chi phí phát sinh của việc truyền thông điệp bên trong nút.
Cách tiếp cận lai này tận dụng điểm mạnh của cả hai mô hình: khả năng mở rộng của MPI đến số lượng nút khổng lồ và hiệu quả của OpenMP cho giao tiếp nhanh trong một nút duy nhất.
Nó giảm thiểu chi phí giao tiếp đồng thời tăng thông lượng tính toán.
Do đó nó trở thành phương pháp ưa thích để lập trình các siêu máy tính hàng đầu ngày nay.
Ví dụ: Trong mô phỏng động lực học chất lỏng (CFD) cho thiết kế máy bay, toàn bộ mô hình 3D được chia thành các khối lớn, mỗi khối được giao cho một nút. MPI xử lý việc trao đổi thông tin giữa các khối này.
Trong mỗi nút, OpenMP chia nhỏ khối thành các phần tử nhỏ hơn và phân phối tính toán cho từng lõi CPU để tối ưu hóa sử dụng tài nguyên tại chỗ.
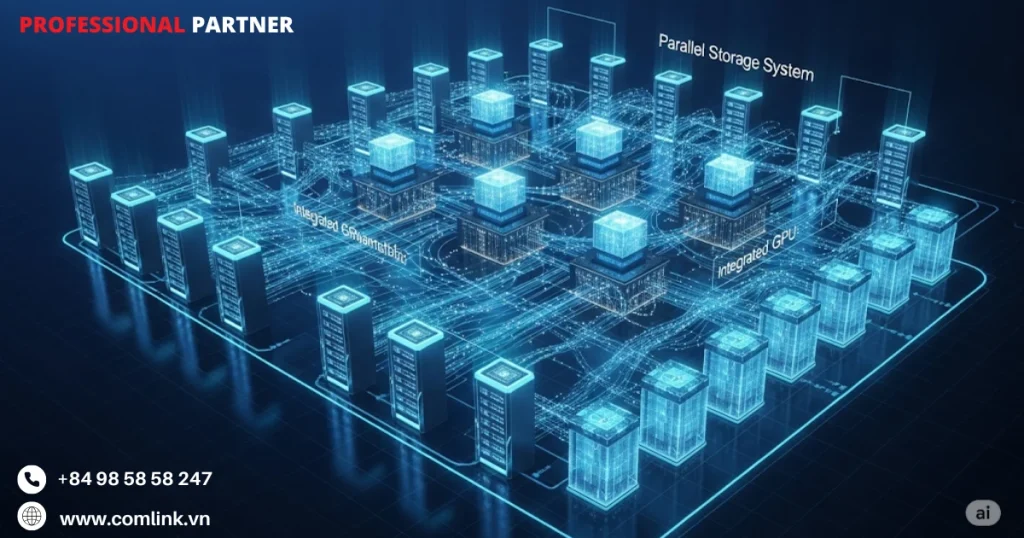
Kiến trúc hệ thống phần cứng
Kiến trúc Cụm máy tính
Cụm máy tính về bản chất là một nhóm các máy tính độc lập thường là các máy chủ được lắp trong tủ rack gọi là các nút.
Những nút này được kết nối thông qua một mạng chuyên dụng có tốc độ siêu cao.
Vì thế giúp chúng hoạt động cùng nhau như một hệ thống thống nhất và mạnh mẽ.
Ý tưởng chính đằng sau tạo cụm là kết hợp sức mạnh tính toán của hàng trăm, thậm chí hàng nghìn máy tính riêng biệt để tạo ra một siêu máy tính ảo có thể xử lý những tác vụ vượt xa khả năng của từng máy tính đơn lẻ.
Ví dụ: Giống như một dàn nhạc giao hưởng, mỗi nghệ sĩ (nút máy tính) đều có vai trò riêng, nhưng khi kết hợp lại dưới sự chỉ huy của nhạc trưởng (hệ thống quản lý cụm), họ tạo ra một tác phẩm hoàn chỉnh vượt xa khả năng của bất kỳ cá nhân nào.
Kiến trúc cụm HPC cổ điển có thể được chia thành ba thành phần chính hoạt động đồng thời và phối hợp với nhau.
Hiệu suất và hiệu quả tổng thể của cụm phụ thuộc rất nhiều vào mức độ cân bằng và tích hợp của các thành phần này.
Thành phần Tính toán
Thành phần này bao gồm các nút tính toán, những “công nhân” thực hiện các phép tính và xử lý dữ liệu thực tế.
Mỗi nút tính toán được trang bị CPU mạnh mẽ, GPU hoặc kết hợp cả hai, được tối ưu hóa đặc biệt cho xử lý tốc độ cao.
Các nút tính toán thực hiện phần lớn các tác vụ tính toán thông qua chạy các tiến trình song song.
Chúng chia nhỏ các bài toán phức tạp thành những phần nhỏ hơn để giải quyết đồng thời.
Ví dụ: Trong mô phỏng thời tiết toàn cầu, một nút có thể xử lý dữ liệu khí hậu của châu Á, nút khác xử lý châu Âu và tất cả làm việc song song để tạo ra dự báo hoàn chỉnh.
Thành phần Mạng
Mạng tạo thành xương sống truyền thông tốc độ cao kết nối tất cả các nút tính toán và hệ thống lưu trữ trong cụm.
Mạng chuyên biệt đảm bảo trao đổi dữ liệu với độ trễ thấp và băng thông cao, điều quan trọng để duy trì sự đồng bộ và hiệu quả trên hàng nghìn nút hoạt động song song.
Các công nghệ như InfiniBand hoặc Ethernet hiệu năng cao thường được sử dụng để xây dựng những mạng này.
Thành phần Lưu trữ
Các nút lưu trữ cung cấp kho dữ liệu tập trung mà tất cả các nút tính toán đều có thể truy cập.
Hệ thống lưu trữ chia sẻ được thiết kế để truy cập nhanh chóng và đồng thời từ nhiều nút.
Đây là điều thiết yếu cho các ứng dụng sử dụng nhiều dữ liệu.
Thông thường, các hệ thống tệp song song được triển khai ở đây để xử lý các thao tác đọc, ghi đồng thời mà không gây nghẽn cổ chai hoặc xung đột.
Do đó đảm bảo tính toàn vẹn và tốc độ dữ liệu.
Tích hợp liền mạch của ba thành phần này tạo thành nền tảng của một cụm HPC hiệu quả.
Nếu bất kỳ thành phần nào hoạt động kém, nó có thể tạo ra nghẽn cổ chai hạn chế hiệu suất tổng thể của hệ thống.
Vai trò của các Nút chức năng
Trong một cụm HPC, không phải tất cả các nút đều thực hiện cùng một chức năng.
Kiến trúc chia các nút thành các danh mục chuyên biệt dựa trên mục đích của chúng.
Vì vậy giúp mỗi nút được tối ưu hóa cho vai trò cụ thể của mình để góp phần vào hiệu quả và khả năng mở rộng tổng thể của hệ thống.
Nút Quản lý
Thường được gọi là nút đầu hoặc nút đăng nhập.
Nút quản lý đóng vai trò trung tâm chỉ huy cho toàn bộ cụm.
Chúng hoạt động như giao diện giữa người dùng hoặc quản trị viên hệ thống với cơ sở hạ tầng cụm.
Người dùng đăng nhập vào các nút này để biên dịch mã, quản lý tệp, và quan trọng nhất là gửi các công việc tính toán.
Nút quản lý chịu trách nhiệm phân phối tác vụ đến các nút tính toán phù hợp theo tính khả dụng của tài nguyên và yêu cầu công việc.
Chúng cũng theo dõi tiến trình công việc và thu thập kết quả khi quá trình tính toán hoàn tất.
Để thực hiện những nhiệm vụ này một cách hiệu quả, nút quản lý chạy phần mềm quản lý cụm chuyên biệt tự động hóa lập lịch công việc, phân bổ tài nguyên và giám sát hệ thống.
Ví dụ: Giống như một sân bay có tháp điều khiển không lưu, nút quản lý điều phối tất cả “chuyến bay” (công việc tính toán) và đảm bảo chúng được phân bổ đến đúng “đường băng” (nút tính toán) phù hợp.
Nút Tính toán
Nút tính toán là xương sống của bất kỳ cụm HPC nào vì chúng là nơi diễn ra tất cả các phép tính phức tạp.
Một cụm HPC điển hình có thể có từ vài chục đến hàng nghìn nút tính toán hoạt động đồng thời.
Những nút này được thiết kế để có khả năng xử lý tối đa, được trang bị CPU hoặc GPU hiệu năng cao.
Để tập trung hoàn toàn vào tính toán, nút tính toán thường hoạt động với hệ điều hành tối giản được rút gọn chỉ còn những chức năng thiết yếu.
Chúng không tương tác trực tiếp với người dùng mà thay vào đó nhận hướng dẫn và dữ liệu từ các nút quản lý, thực hiện tính toán rồi trả về kết quả.
Phân tách rõ ràng đảm bảo tài nguyên tính toán được dành hoàn toàn để xử lý khối lượng công việc mà không bị chi phí phát sinh từ tương tác người dùng hoặc các tác vụ quản lý hệ thống.
Nút Lưu trữ
Nút lưu trữ tạo thành trung tâm dữ liệu tập trung của cụm.
Chúng quản lý các hệ thống tệp song song hiệu năng cao có thể xử lý hàng nghìn nút tính toán.
Nút lưu trữ đọc và ghi vào bộ nhớ chia sẻ đồng thời mà không gây ra va chạm dữ liệu hoặc độ trễ.
Khả năng này rất quan trọng đối với các khối lượng công việc sử dụng nhiều dữ liệu như mô phỏng, phân tích dữ liệu lớn hoặc huấn luyện máy học.
Đây là nơi các tập dữ liệu lớn phải được truy cập nhanh chóng từ nhiều bộ xử lý cùng lúc.
Nút lưu trữ đảm bảo các thao tác đầu vào, đầu ra mượt mà và không cản trở thông lượng tính toán.
Ví dụ: Trong nghiên cứu genomics, khi hàng trăm nút tính toán cần truy cập đồng thời vào cơ sở dữ liệu gen có kích thước terabyte, các nút lưu trữ đảm bảo không có nút nào phải “chờ đợi” để lấy dữ liệu cần thiết.
Kiến trúc Bộ xử lý
Sức mạnh tính toán của mỗi nút trong cụm HPC đến từ các bộ xử lý của nó.
Các hệ thống HPC hiện đại chủ yếu sử dụng hai loại bộ xử lý bổ trợ cho nhau thay vì cạnh tranh: CPU (Bộ xử lý Trung tâm) và GPU (Bộ xử lý Đồ họa).
Bộ xử lý trung tâm CPU
Trong môi trường HPC, CPU được sử dụng không phải là bộ xử lý máy tính để bàn thông thường mà là những chip cấp máy chủ đa lõi mạnh mẽ.
Ví dụ: dòng Intel Xeon Scalable và AMD EPYC, có thể tích hợp hàng chục lõi trong một chip duy nhất.
Những CPU này có kiến trúc phức tạp được thiết kế để xử lý hiệu quả các tác vụ tuần tự, luồng lệnh phức tạp và các thao tác độ trễ thấp.
Hãy nghĩ về CPU như bộ não quản lý toàn bộ hoạt động của nút và điều khiển logic tính toán phức tạp.
Nó xuất sắc trong các tác vụ đòi hỏi ra quyết định, phối hợp và thực thi các thao tác với yêu cầu thời gian nghiêm ngặt.
CPU cũng quản lý tài nguyên hệ thống và điều phối công việc được thực hiện bởi các bộ xử lý khác trong nút.
Ví dụ: Trong mô phỏng động lực học chất lỏng, CPU sẽ điều khiển thuật toán tổng thể, quyết định khi nào cần tăng độ chính xác tính toán và phối hợp với GPU để xử lý các phần song song được.
Bộ xử lý đồ họa GPU
Ban đầu được tạo ra để tăng tốc kết xuất đồ họa cho trò chơi và ứng dụng hình ảnh nhưng GPU đã cách mạng hóa HPC nhờ mang lại khả năng xử lý song song khổng lồ.
Khác với CPU có số lượng lõi mạnh mẽ hạn chế, GPU chứa hàng nghìn lõi đơn giản hơn được thiết kế để thực hiện nhiều thao tác đồng thời.
Mỗi lõi GPU có thể không mạnh bằng lõi CPU riêng lẻ, nhưng khi kết hợp lại, chúng có thể thực thi khối lượng khổng lồ các phép tính lặp đi lặp lại và đơn giản như các phép toán ma trận với tốc độ chóng mặt.
Điều này khiến GPU trở thành bộ tăng tốc hoàn hảo cho các khối lượng công việc có độ song song cao như trí tuệ nhân tạo (AI), học máy và mô phỏng khoa học quy mô lớn.
Ví dụ: Trong huấn luyện mô hình AI nhận dạng hình ảnh, GPU có thể xử lý đồng thời hàng nghìn pixel từ hàng trăm ảnh, trong khi CPU sẽ mất rất nhiều thời gian để làm công việc tương tự một cách tuần tự.
CPU và GPU làm việc cùng nhau
Thay vì cạnh tranh, CPU và GPU đóng vai trò bổ trợ trong một nút HPC.
Một phép so sánh hữu ích là nghĩ về CPU như một đầu bếp trưởng tài năng trong một nhà bếp lớn, người quản lý các công thức phức tạp và phối hợp các hoạt động.
GPU giống như một đội phụ bếp, mỗi người chuyên về các tác vụ lặp đi lặp lại nhưng thiết yếu (như thái rau hoặc lật bánh), cùng làm việc đồng thời để đạt được thông lượng cao.
Các siêu máy tính hàng đầu ngày nay chủ yếu là hệ thống lai kết hợp điểm mạnh của cả CPU và GPU.
Sự hợp tác này tạo điều kiện xử lý linh hoạt các khối lượng công việc đa dạng.
CPU giải quyết các phần tuần tự và chuyên sâu về điều khiển, trong khi GPU tăng tốc các phép tính có tính song song cao.
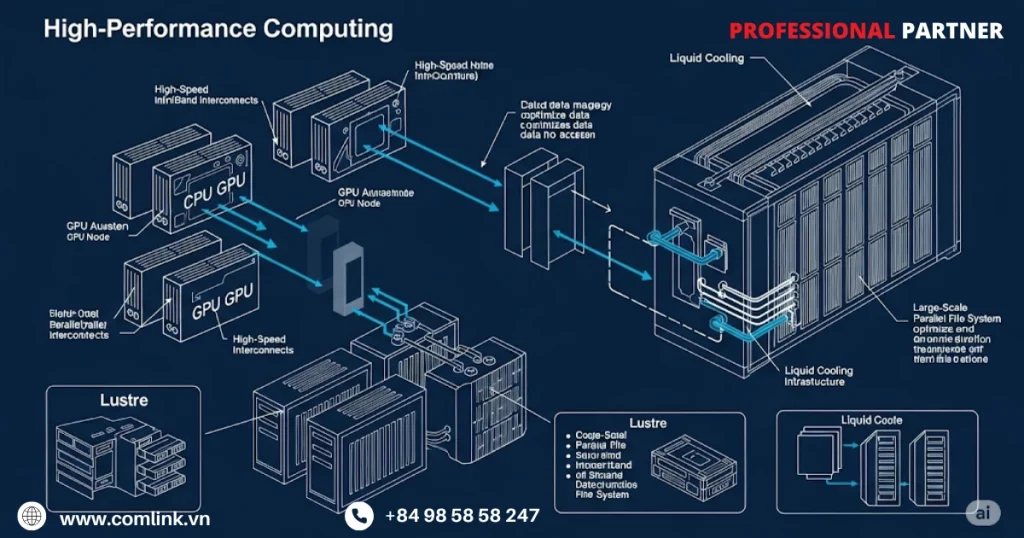
Kiến trúc mạng tốc độ cao
Nếu các nút tính toán là những thành phố sản xuất tri thức thì mạng kết nối chúng chính là siêu đường cao tốc vận chuyển thông tin giữa các thành phố đó.
Trong môi trường HPC nơi hàng nghìn nút hợp tác chặt chẽ trên các bài toán chia sẻ, hiệu suất mạng là yếu tố tuyệt đối quan trọng.
Mạng chậm có nghĩa là các bộ xử lý mạnh mẽ phải dành thời gian chờ đợi dữ liệu thay vì tính toán.
Từ đó dẫn đến nghẽn cổ chai và lãng phí tài nguyên.
Do đó, các mạng HPC phải ưu tiên hai yếu tố chính: băng thông cực cao để di chuyển khối lượng lớn dữ liệu một cách nhanh chóng, độ trễ siêu thấp để giảm thiểu chậm trễ trong giao tiếp.
InfiniBand
InfiniBandlà lựa chọn hàng đầu cho các hệ thống HPC tầm cỡ thế giới.
Được xây dựng đặc biệt cho các cụm máy tính, InfiniBand cung cấp băng thông cực cao đạt hàng trăm gigabit mỗi giây và độ trễ rất thấp thường dưới một micro giây.
Một tính năng nổi bật là Truy cập Bộ nhớ Trực tiếp Từ xa (RDMA).
Do đó giúp một nút có thể truy cập trực tiếp vào bộ nhớ của nút khác mà không cần sự tham gia của CPU ở cả hai phía.
Do đó giảm đáng kể chi phí xử lý và tăng tốc truyền dữ liệu, khiến giao tiếp hiệu quả hơn nhiều.
Ví dụ: Trong mô phỏng khí hậu toàn cầu, khi một nút xử lý dữ liệu Thái Bình Dương cần thông tin từ nút xử lý Đại Tây Dương, RDMA có thể truyền dữ liệu này gần như tức thời mà không làm gián đoạn các phép tính đang diễn ra.
Ethernet tốc độ cao
Mặc dù ban đầu được phát triển cho mạng tổng quát thay vì HPC, các tiêu chuẩn Ethernet hiện đại như 100GbE, 200GbE và thậm chí 400GbE đã trở thành các lựa chọn khả thi.
Đây là điều đặc biệt cho các cụm nhỏ hơn hoặc các ứng dụng ít nhạy cảm với độ trễ.
Các công nghệ như RDMA qua Ethernet Hội tụ (RoCE) nhằm mang lợi ích của RDMA vào môi trường Ethernet, cải thiện hiệu suất hơn nữa.
Mặc dù Ethernet không thể sánh được với hiệu suất độ trễ của InfiniBand nhưng tính phổ biến và hiệu quả chi phí của nó khiến nó được ưa chuộng trong nhiều môi trường HPC.
NVIDIA NVLink và NVSwitch
NVIDIA đã phát triển các công nghệ độc quyền như NVLink và NVSwitch để tạo điều kiện giao tiếp nội bộ nhanh chóng giữa các GPU trong một nút duy nhất hoặc qua nhiều nút.
NVLink cung cấp băng thông cao hơn đáng kể so với kết nối PCIe tiêu chuẩn, giúp các GPU trao đổi dữ liệu trực tiếp và nhanh chóng.
Khả năng này rất quan trọng cho huấn luyện AI phân tán trên nhiều GPU.
Đây là nơi chia sẻ và đồng bộ hóa dữ liệu liên tục là cần thiết để xử lý hiệu quả.
Ví dụ: Khi huấn luyện một mô hình ngôn ngữ lớn như GPT, hàng chục GPU cần liên tục cập nhật trọng số với nhau. NVLink giúp quá trình này diễn ra mượt mà, giống như một nhóm nhạc sĩ điều chỉnh nhịp điệu theo thời gian thực để tạo ra bản hòa tấu hoàn hảo.

Hệ thống lưu trữ song song
Trong bối cảnh HPC, lưu trữ không chỉ đơn thuần là nơi chứa dữ liệu.
Nó phải xử lý hiệu quả các yêu cầu truy cập đồng thời từ hàng nghìn nút tính toán mà không trở thành nút thắt cổ chai về hiệu suất.
Các hệ thống tệp truyền thống như NFS (Network File System) không đáp ứng được những yêu cầu này do khả năng xử lý đồng thời và thông lượng hạn chế.
Nhu cầu về hệ thống tệp song song
Để giải quyết những thách thức này, môi trường HPC sử dụng các hệ thống tệp song song chuyên biệt được thiết kế để phân phối cả dữ liệu và siêu dữ liệu trên nhiều máy chủ lưu trữ vật lý.
Kiến trúc này giúp nhiều nút có thể đọc và ghi dữ liệu đồng thời vào cùng những tệp lớn nhưng rất ít khi can thiệp lẫn nhau.
Khi một nút tính toán muốn truy cập tệp, trước tiên nó liên hệ với máy chủ siêu dữ liệu để nhận “bản đồ” cho biết các khối dữ liệu khác nhau nằm ở đâu trên các máy chủ lưu trữ.
Sau đó, nút tính toán trực tiếp truy cập những máy chủ dữ liệu đó một cách song song.
Vì thế tạo ra thông lượng đầu vào, đầu ra (I/O) cực cao và khả năng mở rộng tuyệt vời.
Ví dụ: Giống như một thư viện khổng lồ có nhiều quầy phục vụ, thay vì xếp hàng ở một quầy duy nhất, độc giả có thể đồng thời lấy sách từ nhiều quầy khác nhau, mỗi quầy chuyên về một chủ đề cụ thể.
Các hệ thống tệp song song phổ biến
Một số hệ thống tệp song song đã được áp dụng rộng rãi trong HPC nhờ hiệu suất, độ tin cậy và khả năng mở rộng:
Hệ thống Lustre
Lustre là một trong những hệ thống tệp song song mã nguồn mở phổ biến nhất được sử dụng trong nhiều siêu máy tính hàng đầu thế giới.
Nó nổi tiếng với khả năng mở rộng gần như tuyến tính nên thêm máy chủ lưu trữ hầu như tăng hiệu suất I/O theo tỷ lệ thuận.
Lustre xử lý hiệu quả các khối lượng công việc với kích thước tệp khổng lồ và tính đồng thời cao.
IBM Spectrum Scale (trước đây là GPFS)
Giải pháp thương mại của IBM được đánh giá cao về độ tin cậy, dễ quản lý và hiệu suất ổn định trên các khối lượng công việc hỗn hợp bao gồm cả tệp lớn và nhỏ.
Nó xuất sắc trong các triển khai HPC doanh nghiệp đòi hỏi hiệu suất ổn định trên các loại dữ liệu đa dạng.
Hệ thống BeeGFS
BeeGFS là hệ thống tệp song song mã nguồn mở khác nổi tiếng về tính đơn giản trong cài đặt và cấu hình.
BeeGFS được ưa chuộng cho các cụm HPC quy mô vừa và nhỏ.
Đây là nơi yêu cầu dễ sử dụng kết hợp với hiệu suất vững chắc được đánh giá cao.
Vai trò của lưu trữ song song
Kiến trúc của các hệ thống tệp song song loại bỏ điểm nghẽn đơn lẻ mà các hệ thống lưu trữ truyền thống gặp phải nhờ phân phối khối lượng công việc đều đặn trên nhiều máy chủ.
Khả năng này rất quan trọng đối với các ứng dụng HPC sử dụng nhiều dữ liệu như mô phỏng khoa học, phân tích dữ liệu lớn và huấn luyện học máy.
Đó là nơi hàng nghìn nút cần truy cập nhanh và đồng thời vào các tập dữ liệu chia sẻ.
Ví dụ: Trong nghiên cứu về biến đổi khí hậu, khi 10.000 nút cần truy cập đồng thời vào dữ liệu nhiệt độ toàn cầu trong 100 năm qua, hệ thống lưu trữ song song đảm bảo không có nút nào phải chờ đợi dữ liệu cần thiết.
Giải pháp tản nhiệt làm mát
Tích hợp sức mạnh tính toán khổng lồ vào không gian nhỏ gọn đi kèm với thách thức đáng kể khi tạo ra nhiệt năg lớn.
Một rack HPC duy nhất có thể tiêu thụ hàng chục kilowatt điện năng và toàn bộ siêu máy tính có thể đòi hỏi năng lượng tương đương với một thành phố nhỏ.
Quản lý nhiệt hiệu quả là điều thiết yếu để duy trì sự ổn định của hệ thống, ngăn chặn hư hỏng phần cứng và kéo dài tuổi thọ linh kiện.
Làm mát bằng không khí truyền thống
Làm mát bằng không khí vẫn là phương pháp phổ biến nhất để quản lý nhiệt trong nhiều trung tâm dữ liệu HPC.
Cách tiếp cận này sử dụng các đơn vị Điều hòa Không khí Phòng máy tính (CRAC) để thổi không khí lạnh vào trung tâm dữ liệu.
Máy chủ được sắp xếp theo cấu hình lối nóng, lối lạnh.
Khi đó không khí lạnh được dẫn vào phía trước của các rack (lối lạnh), hút qua thiết bị để hấp thụ nhiệt, sau đó thải ra lối nóng phía sau các rack.
Mô hình luồng không khí này nhằm tối đa hóa hiệu quả làm mát nhờ ngăn chặn sự pha trộn của các dòng không khí nóng và lạnh.
Mặc dù hiệu quả với các thiết lập mật độ thấp hơn, làm mát bằng không khí có giới hạn khi mật độ công suất trên mỗi rack vượt quá khoảng 20 kW vì khả năng dẫn nhiệt và dung lượng nhiệt của không khí tương đối thấp.
Ví dụ: Giống như làm mát một căn phòng đông người bằng quạt, khi có quá nhiều người, quạt không còn đủ mạnh để giữ nhiệt độ mát mẻ.
Làm mát bằng chất lỏng
Khi rack HPC trở nên dày đặc hơn với CPU và GPU mạnh mẽ, làm mát bằng chất lỏng trở nên cần thiết do tính chất truyền nhiệt vượt trội.
Chất lỏng có thể đưa nhiệt ra ngoài hiệu quả hơn không khí hàng nghìn lần.
Một số phương pháp làm mát bằng chất lỏng đã được phát triển:
Bộ trao đổi nhiệt cửa sau
Đây là những bộ trao đổi nhiệt làm mát bằng chất lỏng được lắp ở cửa sau của tủ rack.
Chúng bắt giữ không khí thải nóng trực tiếp khi rời khỏi máy chủ, loại bỏ nhiệt trước khi nó có thể làm ấm môi trường xung quanh.
Phương pháp này cải thiện hiệu quả năng lượng mà không cần thay đổi các thành phần máy chủ bên trong.
Làm mát chất lỏng trực tiếp đến Chip
Các tấm lạnh chứa chất làm mát được gắn trực tiếp vào các thành phần nóng như CPU và GPU bên trong máy chủ.
Nhiệt được hấp thụ ngay tại nguồn và vận chuyển ra ngoài thông qua các ống dẫn đến máy làm lạnh bên ngoài.
Phương pháp này giảm đáng kể nhiệt độ thành phần so với chỉ làm mát bằng không khí.
Làm mát Ngâm
Kỹ thuật tiên tiến và hiệu quả nhất bao gồm việc ngâm toàn bộ máy chủ hoặc thành phần trong các chất lỏng điện môi được pha chế đặc biệt không dẫn điện.
Những chất lỏng này hấp thụ nhiệt trực tiếp từ tất cả các bề mặt và lưu thông ra các đơn vị làm mát.
Làm mát ngâm loại bỏ hoàn toàn quạt và có thể giảm tiêu thụ năng lượng làm mát trung tâm dữ liệu lên đến 99%.
Nó cũng tạo điều kiện triển khai mật độ cao hơn nhờ loại bỏ hoàn toàn các ràng buộc về luồng không khí.
Ví dụ: Tưởng tượng làm mát một động cơ ô tô trong khi làm mát bằng không khí giống như thổi quạt vào động cơ, làm mát ngâm giống như ngâm toàn bộ động cơ trong một bể dầu làm mát nên hiệu quả hơn rất nhiều lần.

Hệ sinh thái phần mềm
Hệ điều hành Linux
Khi nhắc đến hệ điều hành trong lĩnh vực máy tính hiệu năng cao, Linux chiếm vị thế gần như độc tôn.
Theo danh sách TOP500, bảng xếp hạng các siêu máy tính mạnh nhất thế giới, gần 100% các hệ thống HPC hàng đầu đều vận hành trên các biến thể của Linux.
Sự thống trị này không phải là điều ngẫu nhiên mà xuất phát từ những đặc tính vốn có giúp Linux trở thành lựa chọn lý tưởng cho môi trường tính toán quy mô lớn.
Linux là mã nguồn mở và miễn phí
Tính chất mã nguồn mở trao quyền truy cập đầy đủ vào kernel cho các quản trị viên hệ thống và nhà nghiên cứu.
Vì vậy giúp họ tùy chỉnh và tối ưu hóa chính xác theo phần cứng chuyên biệt của mình.
Mức độ tùy chỉnh này là điều không thể thực hiện với các hệ điều hành độc quyền như Windows, nơi kernel được đóng kín và không thể sửa đổi.
Đối với các trung tâm HPC triển khai cấu hình phần cứng tùy chỉnh hoặc cần khai thác tối đa hiệu suất từ cơ sở hạ tầng, Linux mang lại sự linh hoạt tối đa.
Ví dụ: Tại Trung tâm Khoa học Máy tính Quốc gia Mỹ (NCSA), các kỹ sư đã tùy chỉnh kernel Linux để tối ưu hóa giao tiếp giữa các node trong siêu máy tính Blue Waters, giúp giảm độ trễ mạng xuống dưới 1 microsecond.
Linux có độ ổn định và tin cậy cao
Khối lượng công việc HPC thường liên quan đến chạy các phép tính và mô phỏng phức tạp liên tục trong nhiều ngày, thậm chí nhiều tuần.
Khả năng vận hành không gián đoạn trong thời gian dài mà không cần khởi động lại của Linux là yếu tố thiết yếu để đảm bảo các công việc này hoàn thành thành công.
Linux cung cấp hiệu suất cao và tính linh hoạt
Quản trị viên có thể tối giản hệ thống Linux thông qua việc tắt các dịch vụ không cần thiết và giao diện đồ họa.
Do đó dành toàn bộ tài nguyên hệ thống cho các tác vụ tính toán.
Thiết lập này tối đa hóa hiệu suất và giảm thiểu chi phí hoạt động.
Khả năng tùy chỉnh sâu như vậy giúp các cụm HPC được tinh chỉnh một cách tỉ mỉ để đạt thông lượng tối ưu.
Bảo mật mạnh mẽ
Với cộng đồng phát triển toàn cầu rộng lớn liên tục kiểm tra mã nguồn, các lỗ hổng bảo mật thường được phát hiện và vá lỗi nhanh chóng.
Khía cạnh này rất quan trọng trong môi trường HPC nơi có thể liên quan đến dữ liệu nghiên cứu nhạy cảm hoặc cơ sở hạ tầng trọng yếu.
Hệ sinh thái phần mềm đa dạng
Hầu hết các công cụ khoa học, thư viện và ứng dụng được sử dụng trong máy tính hiệu năng cao đều được phát triển đầu tiên hoặc dành riêng cho môi trường Linux.
Tính tương thích này đảm bảo người dùng HPC có quyền truy cập vào những đổi mới và tối ưu hóa mới nhất.
Các bản phân phối Linux phổ biến trong môi trường HPC thường là các phiên bản tập trung vào doanh nghiệp như Red Hat Enterprise Linux (RHEL), SUSE Linux Enterprise Server (SLES), hoặc các bản rebuild do cộng đồng phát triển như CentOS và Rocky Linux.
Những bản phân phối này cung cấp tính ổn định, cập nhật bảo mật và hỗ trợ được thiết kế riêng cho khối lượng công việc HPC đòi hỏi cao.
Quản lý tài nguyên và lập lịch
Một cụm HPC đại diện cho tài nguyên chia sẻ có giá trị cao được nhiều người dùng và dự án truy cập đồng thời.
Để đảm bảo sử dụng công bằng, hiệu quả và có trật tự các tài nguyên này, người dùng không thể đơn giản đăng nhập vào các node tính toán và chạy chương trình tùy ý.
Thay vào đó, mọi hoạt động đều được điều phối thông qua hệ thống lập lịch công việc hoặc trình quản lý tài nguyên.
Quy trình làm việc điển hình
Người dùng chuẩn bị script công việc.
Đây là một tệp văn bản đơn giản chỉ định các yêu cầu tài nguyên như số lượng node tính toán, lõi CPU trên mỗi node, kích thước bộ nhớ, số lượng GPU và thời gian chạy tối đa.
Script này cũng chứa các lệnh cần thiết để thực thi tác vụ tính toán.
Tiếp theo, người dùng gửi script công việc này đến bộ lập lịch.
Bộ lập lịch đặt công việc vào hàng đợi và quản lý nó cùng với các công việc khác đang chờ tài nguyên.
Nó liên tục giám sát tình trạng tài nguyên có sẵn của cụm.
Khi có đủ tài nguyên trống khớp với yêu cầu của công việc, bộ lập lịch sẽ phân bổ những tài nguyên đó cho công việc và khởi chạy thực thi trên các node tính toán được chỉ định.
Sau khi công việc kết thúc, các tài nguyên được phân bổ sẽ được giải phóng trở lại cho các công việc tiếp theo.
Quản lý có cấu trúc đảm bảo việc sử dụng tối ưu tài nguyên HPC và ngăn chặn xung đột hoặc thiếu hụt tài nguyên giữa các người dùng.
Hệ thống lập lịch phổ biến
Hệ thống Slurm
Slurm là bộ lập lịch mã nguồn mở nổi tiếng với khả năng mở rộng và được sử dụng rộng rãi trên một số siêu máy tính lớn nhất toàn cầu bao gồm Frontier, hiện là một trong những máy mạnh nhất thế giới.
Tính linh hoạt của Slurm hỗ trợ hiệu quả các khối lượng công việc HPC đa dạng đồng thời cung cấp khả năng kiểm soát chi tiết việc phân bổ tài nguyên.
Ví dụ minh họa: Tại Phòng thí nghiệm Quốc gia Oak Ridge, Slurm quản lý hơn 9,400 node của siêu máy tính Summit với hơn 2.2 triệu lõi CPU và 27,600 GPU, xử lý hàng nghìn công việc đồng thời từ các nhà nghiên cứu trên toàn thế giới.
Hệ thống PBS
PBS là một trong những bộ lập lịch lâu đời nhất và phổ biến nhất được sử dụng trong HPC.
Nó có cả phiên bản thương mại (PBS Pro) và mã nguồn mở (OpenPBS).
PBS có lịch sử lâu dài về độ tin cậy và tích hợp tốt với các cơ sở hạ tầng HPC khác nhau.
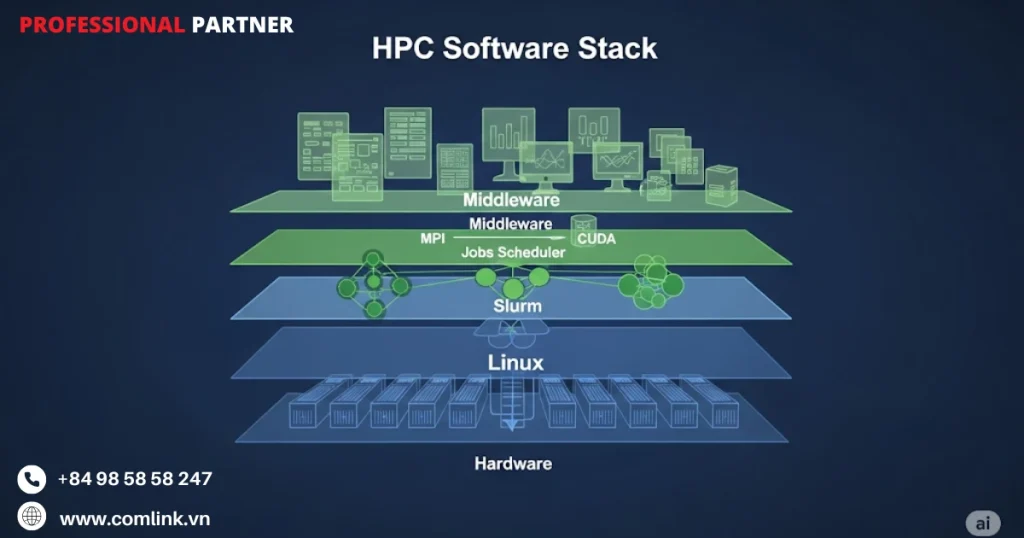
Thư viện và tiêu chuẩn lập trình song song
Để thực sự khai thác sức mạnh của kiến trúc phần cứng song song, lập trình viên cần những công cụ và framework chuyên dụng giúp ứng dụng có thể chạy đồng thời trên nhiều bộ xử lý.
Trong HPC, hai trụ cột nền tảng của lập trình song song chiếm ưu thế: MPI (Message Passing Interface) và OpenMP (Open Multi-Processing).
MPI (Message Passing Interface)
MPI là tiêu chuẩn được công nhận rộng rãi cho lập trình các hệ thống bộ nhớ phân tán, nơi các tiến trình chạy trên các node tính toán riêng biệt được kết nối qua mạng.
Nó cung cấp thư viện phong phú giúp các tiến trình này giao tiếp thông qua gửi và nhận thông điệp.
Ngoài ra còn đồng bộ hóa hoạt động và thực hiện các thao tác tập thể như phát sóng hoặc thu thập dữ liệu.
Khả năng này rất cần thiết để điều phối các phép tính quy mô lớn trải rộng trên nhiều máy vật lý.
Các triển khai MPI phổ biến bao gồm OpenMPI, MPICH và Intel MPI.
Mặc dù được phát triển độc lập, tất cả đều tuân thủ tiêu chuẩn MPI, đảm bảo mã MPI vẫn có thể di chuyển trên các nền tảng HPC khác nhau.
Tính di động này rất quan trọng vì nó giúp các nhà nghiên cứu và phát triển viết mã một lần và triển khai trên các siêu máy tính khác nhau với những thay đổi tối thiểu.
Mô hình truyền thông điệp rõ ràng của MPI đòi hỏi lập trình viên phải thiết kế cẩn thận cách dữ liệu được trao đổi giữa các tiến trình.
Như vayqaj tuy tăng độ phức tạp nhưng cũng cung cấp khả năng kiểm soát chi tiết các kiểu giao tiếp.
Đâylaf yếu tố quan trọng để tối ưu hiệu suất trong các mô phỏng quy mô lớn.
Ví dụ: Tại Trung tâm Nghiên cứu Khí hậu Quốc gia Mỹ, các nhà khoa học sử dụng MPI để chạy mô hình dự báo thời tiết toàn cầu trên hàng nghìn node, với mỗi node xử lý một vùng địa lý khác nhau và trao đổi thông tin biên giới thông qua MPI.
OpenMP (Open Multi-Processing)
OpenMP mang đến cách tiếp cận bổ sung được thiết kế riêng cho hệ thống bộ nhớ chia sẻ.
Chúng thường trong một node tính toán đơn chứa nhiều lõi CPU.
Nó cung cấp API tiêu chuẩn sử dụng các chỉ thị compiler đơn giản được nhúng trong mã nguồn để song song hóa các vòng lặp và đoạn mã.
Compiler sau đó tự động tạo và quản lý các thread chạy đồng thời trên các lõi khác nhau.
Thông qua trừu tượng hóa quản lý thread, OpenMP giảm đáng kể nỗ lực phát triển để song song hóa các ứng dụng hoạt động trong môi trường bộ nhớ chia sẻ.
Nhà phát triển có thể dần dần giới thiệu tính song song thông qua chú thích mã tuần tự hiện có.
Do đó làm cho nó trở nên dễ tiếp cận ngay cả với những người mới bắt đầu với lập trình song song.
Ví dụ: Một thuật toán xử lý hình ảnh có thể sử dụng OpenMP để chia một bức ảnh thành nhiều vùng và xử lý mỗi vùng trên một lõi CPU khác nhau, giảm thời gian xử lý từ vài phút xuống chỉ còn vài giây.
Kết hợp MPI và OpenMP
Sự khác biệt cơ bản giữa mô hình bộ nhớ phân tán của MPI và mô hình bộ nhớ chia sẻ của OpenMP thường có nghĩa là chúng được sử dụng cùng nhau trong các mô hình lập trình hybrid.
Ví dụ: một ứng dụng HPC có thể sử dụng MPI để phân phối công việc trên các node trong cụm trong khi sử dụng OpenMP để song song hóa các tác vụ trong mỗi node.
Cách tiếp cận hybrid này cân bằng khả năng mở rộng với sự dễ dàng phát triển và sử dụng tài nguyên hiệu quả.
Phần mềm ứng dụng và công cụ tối ưu
Ngoài hệ điều hành nền tảng và thư viện lập trình song song, hệ sinh thái phần mềm HPC bao gồm một loạt rộng lớn các ứng dụng khoa học và kỹ thuật.
Nó bao gồm cả thương mại và mã nguồn mở đã được tối ưu hóa cẩn thận để chạy hiệu quả trên các cụm HPC.
Mô phỏng kỹ thuật
Trong các lĩnh vực như động lực học chất lỏng và phân tích cấu trúc, các ứng dụng như ANSYS Fluent, Abaqus và Simcenter STAR-CCM+ được sử dụng rộng rãi.
Những công cụ này giải quyết các vấn đề động lực học chất lỏng tính toán (CFD) và phân tích phần tử hữu hạn (FEA).
Vì thế giúp các kỹ sư mô phỏng luồng khí qua cánh máy bay hoặc phân bố ứng suất trong các bộ phận cơ khí với độ chính xác cao.
Ví dụ: Boeing sử dụng ANSYS Fluent trên các cụm HPC để mô phỏng luồng khí xung quanh máy bay 787 Dreamliner, giúp giảm 20% thời gian thiết kế và tối ưu hóa hiệu suất nhiên liệu.
Hóa học tính toán và sinh học
Các gói phần mềm như GROMACS, NAMD và LAMMPS rất quan trọng cho mô phỏng động lực học phân tử.
Những công cụ này mô hình hóa chuyển động vật lý của nguyên tử và phân tử theo thời gian.
Từ đó cung cấp cái nhìn sâu sắc về các quá trình sinh học, tương tác thuốc và khoa học vật liệu.
Ví dụ: Các nhà nghiên cứu tại Đại học Stanford sử dụng GROMACS để mô phỏng protein SARS-CoV-2, giúp hiểu cơ chế hoạt động của virus và phát triển thuốc điều trị COVID-19.
Toán học và phân tích dữ liệu
MATLAB vẫn phổ biến cho tính toán số, trong khi Python với các thư viện như NumPy, SciPy.
Pandas cũng đã có sự tăng trưởng nhanh chóng trong phân tích dữ liệu.
Những công cụ này đã được nâng cấp với backend song song để tận dụng hiệu quả CPU đa lõi và tài nguyên HPC.
Bộ công cụ phát triển khác
Các nhà cung cấp phần cứng lớn cũng đóng góp đáng kể vào hệ sinh thái phần mềm HPC thông qua cung cấp các bộ công cụ phát triển phần mềm (SDK) toàn diện.
Bộ công cụ oneAPI của Intel cung cấp compiler, thư viện tối ưu như Intel MPI và Math Kernel Library (MKL) cũng như các công cụ phân tích hiệu suất như VTune Profiler và Inspector.
Những công cụ này được thiết kế để khai thác hiệu suất tối đa từ CPU và GPU của Intel.
Tương tự, HPC SDK và CUDA Toolkit của NVIDIA cung cấp mọi thứ cần thiết để phát triển và tối ưu ứng dụng cho GPU NVIDIA , động cơ đằng sau phần lớn cuộc cách mạng AI ngày nay.
CUDA tạo điều kiện lập trình trực tiếp các lõi GPU cho khối lượng công việc song song cao, trong khi SDK của NVIDIA cung cấp thư viện và công cụ debug được thiết kế riêng cho nhu cầu HPC.
Ví dụ: Trung tâm Nghiên cứu AI của Facebook (Meta) sử dụng CUDA Toolkit để tăng tốc quá trình huấn luyện mô hình ngôn ngữ lớn, giảm thời gian từ vài tháng xuống chỉ còn vài tuần.
Có thể bạn quan tâm











Liên hệ

Địa chỉ
Tầng 3 Toà nhà VNCC
243A Đê La Thành Str
Q. Đống Đa-TP. Hà Nội


info@comlink.com.vn

Phone
+84 98 58 58 247