


Ứng dụng AI để cá nhân hóa phác đồ điều trị là gì
Ứng dụng AI để cá nhân hóa phác đồ điều trị là dùng AI để tạo ra các chiến lược chăm sóc y tế tùy chỉnh phù hợp với các đặc điểm riêng biệt của từng bệnh nhân.
Mục tiêu cuối cùng của ứng dụng AI để cá nhân hóa phác đồ điều trị là hiện thực hóa tầm nhìn “đúng phương pháp điều trị, cho đúng bệnh nhân, vào đúng thời điểm”.
Bằng cách này, y học cá nhân hóa hướng tới khả năng tối đa hóa hiệu quả điều trị, giảm thiểu các tác dụng phụ không mong muốn và cải thiện đáng kể kết quả sức khỏe tổng thể cũng như chất lượng cuộc sống cho người bệnh.
Tận dụng AI, các nhà cung cấp dịch vụ chăm sóc sức khỏe có thể cải thiện độ chính xác của chẩn đoán, lựa chọn liệu pháp phù hợp nhất, dự đoán kết quả điều trị.
Từ đó liên tục điều chỉnh các kế hoạch dựa trên phản ứng của bệnh nhân và cuối cùng là nâng cao kết quả chăm sóc sức khỏe và sức khỏe tổng thể của bệnh nhân.

Nguồn dữ liệu cung cấp cho AI
Dữ liệu “Omics” đa tầng
Trái tim của y học cá nhân hóa nằm ở dữ liệu phân tử thường được gọi là dữ liệu “Omics”.
Nhóm dữ liệu này bao gồm genomics (di truyền học), transcriptomics (phiên mã học), proteomics (protein học) và metabolomics (chuyển hóa học).
Mỗi loại đều mở ra một nguồn thông tin để quan sát các quá trình sinh học điều khiển sức khỏe và bệnh tật.
Genomics liên quan đến phân tích toàn bộ trình tự DNA của một cá thể để nhận diện các biến thể gen và đột biến ảnh hưởng đến nguy cơ mắc bệnh, tiên lượng hoặc đáp ứng điều trị.
Ví dụ: phát hiện đột biến trong các gen như EGFR hoặc KRAS ở bệnh nhân ung thư có thể dự đoán mức độ đáp ứng với liệu pháp đích. Đa hình nucleotide đơn (SNPs) là một ví dụ khác về biến thể gen có thể tác động đến khả năng mắc bệnh hoặc phản ứng với thuốc của từng cá thể.
Transcriptomics nghiên cứu mức độ biểu hiện RNA, cho thấy gen nào đang được phiên mã tích cực tại một thời điểm nhất định.
Thông tin này phản ánh cách tế bào phản ứng với các kích thích nội và ngoại sinh, bao gồm cả thuốc.
Proteomics nghiên cứu các protein được biểu hiện trong tế bào hoặc mô.
Chúng cung cấp thông tin về chức năng tế bào và các con đường tín hiệu vì protein chính là những “cỗ máy” phân tử thực hiện các chức năng sinh học.
Cuối cùng, metabolomics khảo sát các chất chuyển hóa.
Đây là những phân tử nhỏ tham gia vào quá trình trao đổi chất nên tạo ra một “ảnh chụp” về các quá trình tế bào và cách chúng thay đổi trong trạng thái bệnh lý.
Khi kết hợp lại, những tầng dữ liệu tạo nên một bức tranh toàn diện và động về hoạt động sinh học ở bệnh nhân.
AI tận dụng dữ liệu phân tử phức tạp này để khám phá các mô hình ẩn, xác định cơ chế bệnh lý và dự đoán đáp ứng điều trị với độ chính xác cao hơn bao giờ hết.
Ví dụ: Tại Bệnh viện Memorial Sloan Kettering, AI đã phân tích dữ liệu genomics từ hơn 10.000 bệnh nhân ung thư để phát triển thuật toán dự đoán đáp ứng với liệu pháp miễn dịch. Kết quả cho thấy độ chính xác tăng 30% so với phương pháp truyền thống.
Hồ sơ bệnh án điện tử và dữ liệu lâm sàng
Hồ sơ Sức khỏe Điện tử đóng vai trò như một kho lưu trữ kỹ thuật số phong phú chứa thông tin y tế theo thời gian của bệnh nhân.
EHRs bao gồm các chẩn đoán trước đây như kết quả xét nghiệm (công thức máu và các chỉ số sinh hóa), lịch sử dùng thuốc, các thủ thuật phẫu thuật và những ghi chú của bác sĩ.
Dữ liệu lâm sàng vô cùng giá trị đối với các mô hình AI nhằm dự đoán tiến triển bệnh và kết quả điều trị theo thời gian.
Thông qua phân tích xu hướng trong các giá trị xét nghiệm hoặc điều chỉnh thuốc cùng với ghi chú lâm sàng mô tả triệu chứng hoặc tác dụng phụ, AI có thể phát triển hiểu biết tinh tế về cách tình trạng bệnh nhân phát triển.
Ví dụ: những thay đổi nhỏ trong xét nghiệm máu kết hợp với mô tả từ ghi chú lâm sàng có thể chỉ ra dấu hiệu sớm của biến chứng hoặc kháng thuốc mà rất dễ bị bỏ qua.
Ghi chú lâm sàng tạo ra thách thức do tính chất phi cấu trúc của nó.
Tuy nhiên, những tiến bộ trong xử lý ngôn ngữ tự nhiên (NLP), một nhánh của AI tập trung vào hiểu ngôn ngữ con người giúp các thuật toán trích xuất thông tin có ý nghĩa từ những văn bản này.
Khả năng này giúp hệ thống AI tích hợp cả dữ liệu định lượng và định tính từ EHRs vào việc lập kế hoạch điều trị cá nhân hóa.
Ví dụ: Hệ thống Watson for Oncology của IBM đã phân tích hơn 15 triệu trang ghi chú lâm sàng để phát hiện khi kết hợp các từ ngữ mô tả mệt mỏi và đau khớp trong ghi chú có thể dự báo tác dụng phụ nghiêm trọng của hóa trị sớm hơn 2-3 tuần so với phương pháp theo dõi thông thường.

Chẩn đoán hình ảnh
Chẩn đoán hình ảnh từ lâu đã là trụ cột của chẩn đoán và theo dõi điều trị y khoa.
Các phương thức chụp ảnh truyền thống bao gồm tia X, chụp cắt lớp vi tính (CT), chụp cộng hưởng từ (MRI), và siêu âm.
Những hình ảnh này cung cấp thông tin trực quan quan trọng về cấu trúc giải phẫu và những bất thường.
Một phát triển đặc biệt thú vị là sự xuất hiện của giải phẫu bệnh kỹ thuật số.
Ở đây, các tiêu bản sinh thiết mô được số hóa thành hình ảnh độ phân giải cao mà thuật toán AI có thể phân tích ở cấp độ vi mô.
Vì vậy tạo điều kiện cho khảo sát chi tiết các đặc điểm khối u, phân loại tế bào, và phát hiện dấu hiệu di căn có thể quá nhỏ để mắt người phát hiện một cách nhất quán.
Phân tích hình ảnh hỗ trợ AI nâng cao độ chính xác chẩn đoán thông qua nhận diện những mô hình không thể nhìn thấy với mắt thường và định lượng các đặc điểm một cách khách quan.
Đối với kế hoạch điều trị cá nhân hóa, điều này có nghĩa là phân độ hoặc phân giai đoạn khối u chính xác hơn sẽ trực tiếp ảnh hưởng đến lựa chọn liệu pháp như loại phẫu thuật hoặc phác đồ hóa trị.
Hơn nữa, AI có thể tích hợp dữ liệu hình ảnh với dữ liệu phân tử và lâm sàng để trình bày bức tranh toàn diện về tình trạng bệnh của bệnh nhân.
Cách tiếp cận đa phương thức này cải thiện đáng kể độ chính xác của khuyến nghị điều trị.
Ví dụ: Công ty PathAI đã phát triển thuật toán phân tích hình ảnh giải phẫu bệnh có thể phát hiện ung thư tuyến tiền liệt với độ chính xác 99.5%, đồng thời dự đoán khả năng tái phát sau phẫu thuật với độ tin cậy 85% vượt trội hơn nhiều so với đánh giá của bác sĩ giải phẫu bệnh truyền thống.
Dữ liệu thế giới thực
Dữ liệu thế giới thực (RWD) là nguồn dữ liệu ngày càng quan trọng, thu thập thông tin sức khỏe bên ngoài môi trường lâm sàng truyền thống.
Điều này bao gồm dữ liệu từ các thiết bị đeo thông minh như đồng hồ thông minh theo dõi nhịp tim hoặc máy đo đường huyết liên tục cho bệnh nhân tiểu đường.
Các ứng dụng sức khỏe di động cũng thu thập kết quả do bệnh nhân báo cáo như triệu chứng, thước đo chất lượng cuộc sống, thói quen sinh hoạt và tiếp xúc môi trường.
Khác với những “ảnh chụp” được thu thập trong các lần khám, RWD cung cấp theo dõi liên tục trong môi trường sống hàng ngày của bệnh nhân.
Thông tin thời gian thực hỗ trợ các nhà cung cấp dịch vụ chăm sóc sức khỏe hiểu được cách bệnh nhân đáp ứng với điều trị trong cuộc sống thực tế chư không chỉ trong môi trường y tế được kiểm soát.
Hoạt động thể chất được theo dõi bằng thiết bị đeo có thể thông báo liệu tình trạng chức năng của bệnh nhân có cải thiện hay xấu đi trong quá trình điều trị.
Các triệu chứng do bệnh nhân báo cáo thu thập qua ứng dụng cung cấp bối cảnh bổ sung có thể kích hoạt can thiệp kịp thời.
Khi đưa dữ liệu động này vào các mô hình AI, kế hoạch điều trị có thể được điều chỉnh nhanh chóng dựa trên trải nghiệm thực tế của bệnh nhân thay vì chỉ dựa vào đánh giá lâm sàng định kỳ.
Tính phản hồi này cải thiện tuân thủ liệu pháp và kết quả tổng thể thông qua giải quyết các vấn đề ngay khi chúng xuất hiện.
Ví dụ: Ứng dụng MySugr dành cho bệnh nhân tiểu đường đã thu thập dữ liệu từ hơn 4 triệu người dùng toàn cầu. AI phân tích dữ liệu này phát hiện ra rằng những bệnh nhân ghi nhật ký đường huyết thường xuyên nhất (hơn 5 lần/tuần) có khả năng kiểm soát HbA1c tốt hơn 40% so với nhóm ghi chép ít hơn.
Thông tin này đã được sử dụng để tạo ra các gợi ý cá nhân hóa nhằm cải thiện tuân thủ điều trị.
Thuật toán AI sử dụng
Mô hình học máy
Học máy (ML) là xương sống của nhiều ứng dụng AI trong chăm sóc sức khỏe.
Nó bao gồm huấn luyện các thuật toán để nhận diện mô hình trong dữ liệu và đưa ra dự đoán hoặc phân loại dựa trên quá trình huấn luyện đó.
Có hai loại học máy chính được sử dụng để cá nhân hóa kế hoạch điều trị: học có giám sát và học không giám sát.
Học có giám sát
Học có giám sát là phương pháp được sử dụng rộng rãi nhất trong các ứng dụng AI y tế.
Nó đòi hỏi các bộ dữ liệu đã được gắn nhãn hoặc phân loại trước đó.
Một bộ dữ liệu có thể chứa hàng nghìn bệnh nhân ung thư, mỗi người được gắn nhãn “có đáp ứng” hoặc “không đáp ứng” với một loại thuốc hóa trị cụ thể.
Thuật toán sau đó học các mô hình liên quan đến những kết quả này, giúp nó dự đoán cách bệnh nhân mới có thể phản ứng với cùng một phương pháp điều trị.
Các thuật toán học có giám sát phổ biến bao gồm Support Vector Machines (SVM), Random Forests, Logistic Regression, và Naive Bayes.
Mỗi thuật toán đều có những ưu điểm riêng.
SVM rất mạnh trong các tác vụ phân loại và có thể xử lý các ranh giới phức tạp giữa các kết quả khác nhau của bệnh nhân.
Random Forests tổng hợp nhiều cây quyết định có khả năng chống overfitting tốt và có thể cung cấp thông tin chi tiết về tầm quan trọng của đặc trưng.
Nó hữu ích khi cần hiểu đặc điểm nào của bệnh nhân ảnh hưởng nhiều nhất đến thành công của điều trị.
Các mô hình học có giám sát đã được ứng dụng thành công để dự đoán phản ứng của bệnh nhân với liệu pháp, xác định yếu tố nguy cơ và thậm chí dự báo tiến triển bệnh.
Khả năng học từ dữ liệu lịch sử đã được gắn nhãn khiến chúng đặc biệt hiệu quả trong các tình huống lâm sàng nơi kết quả trong quá khứ được ghi chép kỹ lưỡng.
Ví dụ: Tại Đại học Stanford, các nhà nghiên cứu đã phát triển mô hình SVM phân tích dữ liệu di truyền từ 5.000 bệnh nhân ung thư phổi.
Mô hình này có thể dự đoán đáp ứng với liệu pháp miễn dịch với độ chính xác 78%.
Do đó giúp bác sĩ lựa chọn bệnh nhân phù hợp và tránh điều trị không cần thiết cho 40% trường hợp.
Học không giám sát
Học không giám sát phát huy tác dụng khi không có dữ liệu được gắn nhãn.
Thay vì dựa vào các danh mục được định nghĩa trước, những thuật toán này tìm kiếm cấu trúc hoặc nhóm tự nhiên trong dữ liệu.
Các thuật toán phân cụm là một ví dụ phổ biến, nhóm bệnh nhân dựa trên sự tương đồng trong các đặc điểm sinh học hoặc lâm sàng của họ.
Ví dụ: phân tích hồ sơ phân tử từ các mẫu khối u mà không có nhãn trước có thể tiết lộ các phân nhóm ung thư mới trước đây chưa được biết đến.
Những nhóm mới được xác định này sau đó có thể được nghiên cứu về sự khác biệt trong tiên lượng hoặc đáp ứng với điều trị, dẫn đến các lựa chọn chính xác và cá nhân hóa hơn cho bệnh nhân.
Học không giám sát giúp khám phá các mô hình và mối quan hệ ẩn có thể không rõ ràng thông qua phân tích truyền thống, mang lại góc nhìn mới mẻ về dữ liệu y tế phức tạp.
Ví dụ: Nhóm nghiên cứu tại Viện Ung thư Quốc gia Mỹ đã sử dụng thuật toán K-means clustering để phân tích dữ liệu RNA từ 10.000 bệnh nhân ung thư vú.
Kết quả phát hiện ra 7 phân nhóm mới, trong đó có một nhóm chiếm 12% tổng số bệnh nhân có đáp ứng đặc biệt tốt với liệu pháp hormon mà trước đây không được nhận diện.
Kiến trúc học sâu
Học sâu là một nhánh con của học máy sử dụng mạng nơ-ron với nhiều tầng để tự động học các đặc trưng phân tầng từ dữ liệu thô.
Cách tiếp cận này đã đặc biệt mang tính chuyển đổi trong xử lý các dạng thông tin y tế phức tạp như hình ảnh, chuỗi dữ liệu và văn bản.
Mạng Nơ-ron tích chập
CNNs thường được coi là tiêu chuẩn vàng cho phân tích hình ảnh.
Khả năng tự động phát hiện các đặc trưng từ những cạnh và kết cấu đơn giản ở các tầng đầu đến những hình dạng phức tạp như khối u ở các tầng sâu hơn khiến chúng trở nên lý tưởng cho việc diễn giải dữ liệu hình ảnh y tế.
CNNs đã được sử dụng rộng rãi để phát hiện tổn thương ung thư trên tia X, phân đoạn khối u trên ảnh MRI và phân loại loại tế bào trong tiêu bản giải phẫu bệnh.
Độ chính xác cao và hiệu quả của chúng hỗ trợ các bác sĩ X quang và giải phẫu bệnh thông qua cung cấp ý kiến thứ hai hoặc làm nổi bật các khu vực đáng quan tâm cần khám xét kỹ hơn.
Ví dụ: Google DeepMind đã phát triển mô hình CNN có thể phát hiện hơn 50 bệnh lý mắt khác nhau từ ảnh chụp võng mạc với độ chính xác 94.5%.
Hệ thống này đã được triển khai tại nhiều phòng khám ở Ấn Độ và Thái Lan, giúp sàng lọc sớm cho hơn 100.000 bệnh nhân mỗi năm.
Mạng Nơ-ron hồi quy
RNNs được thiết kế để xử lý dữ liệu tuần tự nơi thứ tự thông tin có ý nghĩa.
Vì vậy chúng rất phù hợp để phân tích dữ liệu chuỗi thời gian như hồ sơ sức khỏe điện tử (EHRs), nơi kết quả xét nghiệm hoặc dấu hiệu sinh tồn của bệnh nhân được ghi lại theo thời gian.
RNNs có thể dự đoán nguy cơ suy tim bằng cách phân tích một chuỗi kết quả xét nghiệm được thu thập trong nhiều lần khám.
Chúng cũng được sử dụng để phân tích các tín hiệu sinh học liên tục từ thiết bị đeo.
Do đó giúp phát hiện dấu hiệu sớm của suy giảm hoặc biến chứng thông qua nhận diện những thay đổi tinh tế theo thời gian.
Ví dụ: Hệ thống APACHE của Philips sử dụng RNN để phân tích dữ liệu từ monitor bệnh nhân tại ICU.
Mô hình có thể dự báo sốc nhiễm khuẩn sớm hơn 6 giờ so với chẩn đoán lâm sàng thông thường nên giúp giảm tỷ lệ tử vong xuống 18% tại các bệnh viện áp dụng.
Mô hình Transformer
Transformers đã thay đổi xử lý ngôn ngữ tự nhiên thông qua nắm bắt hiệu quả các mối quan hệ tầm xa trong văn bản.
Ban đầu được phát triển cho dịch máy, chúng đã được áp dụng để xử lý ghi chú lâm sàng, bài báo nghiên cứu và các tài liệu y tế khác.
Khả năng này giúp hệ thống AI trích xuất thông tin chi tiết có liên quan từ các tường thuật lâm sàng dài và phức tạp như xác định triệu chứng bệnh nhân, lịch sử dùng thuốc, hoặc đáp ứng điều trị.
Đây là những việc con người lục tìm thủ công sẽ rất tốn công sức và thời gian.
Ví dụ: Microsoft đã phát triển mô hình BioBERT (dựa trên kiến trúc Transformer) có thể đọc và tóm tắt 26 triệu bài báo y khoa trong vòng vài giây.
Hệ thống này hỗ trợ bác sĩ tìm kiếm bằng chứng y khoa mới nhất cho từng trường hợp cụ thể, rút ngắn thời gian từ vài giờ xuống còn vài phút.
Mạng đối kháng sinh tạo
GANs bao gồm hai mạng nơ-ron hoạt động đối kháng nhau: một bộ sinh tạo dữ liệu tổng hợp và một bộ phân biệt cố gắng phân biệt dữ liệu thật và giả.
Quá trình cạnh tranh này dẫn đến tạo ra dữ liệu tổng hợp có tính chân thực cao.
Trong chăm sóc sức khỏe, GANs có thể tạo ra hình ảnh y tế nhân tạo như ảnh CT hoặc lát cắt MRI giống với dữ liệu bệnh nhân thật.
Dữ liệu tổng hợp có thể bổ sung cho các bộ dữ liệu hạn chế, đặc biệt quan trọng đối với các bệnh hiếm gặp nơi việc thu thập số lượng lớn mẫu là thách thức.
Thông qua mở rộng dữ liệu huấn luyện có sẵn, GANs giúp cải thiện hiệu suất của các mô hình AI khác được giao nhiệm vụ chẩn đoán hoặc cá nhân hóa điều trị.
Ví dụ: NVIDIA đã sử dụng GANs để tạo ra 100.000 ảnh CT não nhân tạo từ chỉ 1.000 ảnh thật của bệnh nhân đột quỵ hiếm gặp.
Dữ liệu tổng hợp này giúp cải thiện độ chính xác của mô hình chẩn đoán từ 67% lên 89%, mang lại khả năng phát hiện sớm tốt hơn cho các trường hợp khẩn cấp.

Học tăng cường
Học tăng cường (RL) đại diện cho một cách tiếp cận mới hơn để cá nhân hóa kế hoạch điều trị thông qua đóng khung quá trình ra quyết định như một chuỗi hành động.
Mục đích của RL nhằm tối đa hóa lợi ích dài hạn thay vì đưa ra một dự đoán duy nhất.
Các mô hình học máy truyền thống thường đưa ra khuyến nghị một lần, chẳng hạn như “liệu Thuốc A có hiệu quả với bệnh nhân hay không”.
Tuy nhiên, điều trị thường liên quan đến nhiều quyết định theo thời gian.
Vì vậy điều chỉnh thuốc dựa trên phản ứng của bệnh nhân hoặc chuyển đổi liệu pháp khi xảy ra tác dụng phụ.
Các mô hình RL coi điều này như một quá trình quyết định Markov nơi một “tác nhân” AI học cách lựa chọn một loạt hành động như lựa chọn thuốc, điều chỉnh liều lượng dựa trên trạng thái hiện tại của bệnh nhân (đo lường lâm sàng, kết quả xét nghiệm).
Ví dụ: một hệ thống RL có thể khuyến nghị bắt đầu với Liệu pháp A và theo dõi dấu ấn sinh học X trong hai tháng.
Nếu dấu ấn sinh học giảm như mong đợi, nó gợi ý tiếp tục Liệu pháp A, nếu không, AI khuyên chuyển sang Liệu pháp B.
Chiến lược động và thích ứng này bắt chước quá trình tư duy của các bác sĩ lâm sàng giàu kinh nghiệm nhưng hoạt động ở quy mô và tốc độ lớn hơn nhờ sức mạnh tính toán.
Khi vượt ra ngoài các khuyến nghị tĩnh hướng tới lập kế hoạch chiến lược theo thời gian, học tăng cường hứa hẹn trong việc quản lý các bệnh mãn tính như ung thư hoặc HIV hiệu quả hơn.
Ví dụ: Đại học Duke đã phát triển hệ thống RL để quản lý liều insulin cho bệnh nhân tiểu đường type 1. Sau 6 tháng thử nghiệm với 200 bệnh nhân, hệ thống giúp giảm 35% số lần đường huyết xuống thấp nguy hiểm và cải thiện HbA1c trung bình từ 8.2% xuống 7.1%.
Quan trọng hơn, hệ thống có thể tự điều chỉnh theo thói quen ăn uống và hoạt động của từng bệnh nhân, tạo ra phác đồ điều trị thực sự cá nhân hóa.

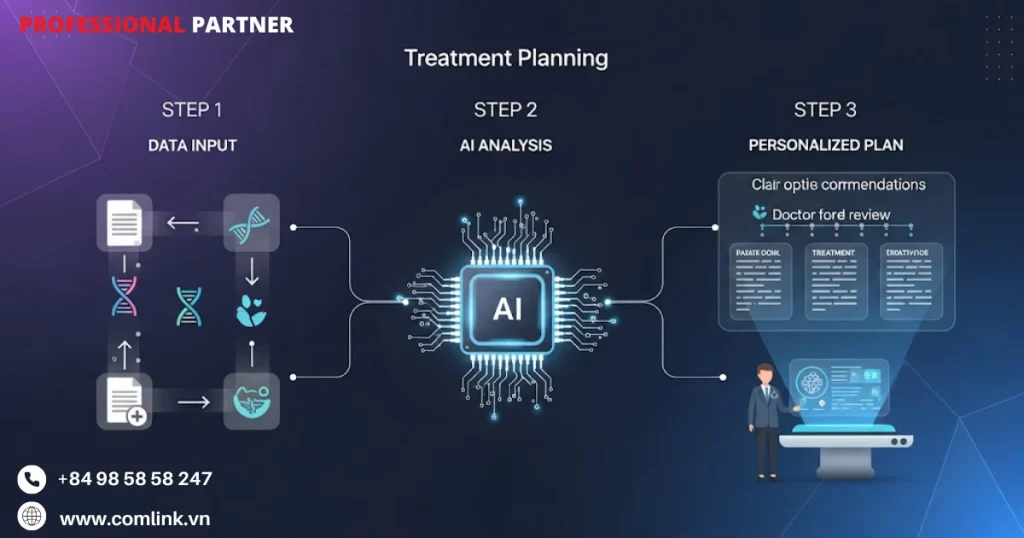
Quy trình xây dựng phác đồ
Thu thập và tích hợp dữ liệu
Bước đầu tiên trong tạo ra kế hoạch điều trị cá nhân hóa hỗ trợ AI là thu thập và tích hợp các loại dữ liệu đa dạng liên quan đến bệnh nhân.
Dữ liệu này đến từ nhiều nguồn khác nhau, tạo ra một hồ sơ phong phú, đa chiều mà các mô hình AI có thể phân tích.
Một số nguồn dữ liệu chính bao gồm:
- Hồ sơ Sức khỏe Điện tử (EHRs) chứa đựng lịch sử y tế chi tiết.
- Dữ liệu omics như di truyền học, protein học và chuyển hóa học tiết lộ thông tin phân tử và di truyền.
- Hình ảnh y tế như MRI, chụp CT hoặc tia X.
- Dữ liệu thế giới thực được thu thập từ thiết bị đeo hoặc kết quả do bệnh nhân báo cáo.
Kết hợp dữ liệu không đồng nhất rất quan trọng vì nó cung cấp cái nhìn toàn diện về tình trạng sức khỏe của bệnh nhân.
Tích hợp đòi hỏi các phương pháp tinh vi để liên kết và tổ chức các điểm dữ liệu từ những nguồn đa dạng này thành một bộ dữ liệu thống nhất.
Nếu thiếu bước này, các mô hình AI sẽ không có đủ dữ liệu cần thiết để cung cấp những thông tin chi tiết được cá nhân hóa cao.
Ví dụ: Hệ thống Watson for Oncology của IBM tích hợp dữ liệu từ hơn 300 nguồn khác nhau cho mỗi bệnh nhân ung thư, bao gồm: kết quả sinh thiết phân tử, hình ảnh CT/MRI, xét nghiệm máu qua 24 tháng, ghi chú của 15 chuyên khoa khác nhau, và dữ liệu từ thiết bị đeo theo dõi hoạt động hàng ngày. Quá trình tích hợp này tạo ra “bản đồ sức khỏe” 360 độ cho mỗi bệnh nhân.
Tiền xử lý và chuẩn hóa dữ liệu
Sau khi dữ liệu được thu thập, nó hiếm khi ở dạng sạch và sẵn sàng sử dụng.
Dữ liệu chăm sóc sức khỏe thô thường có nhiễu, không đầy đủ và không nhất quán giữa các nguồn.
Do đó, tiền xử lý và chuẩn hóa dữ liệu là bước quan trọng tiếp theo.
Làm sạch dữ liệu bao gồm loại bỏ các bản ghi trùng lặp, sửa lỗi và xử lý các giá trị thiếu.
Ví dụ: một số thông tin thiếu có thể được điền vào thông qua các kỹ thuật suy luận trong khi các trường hợp khác có thể cần loại bỏ các bản ghi không sử dụng được để tránh làm sai lệch mô hình.
Chuẩn hóa có nghĩa là chuyển đổi tất cả dữ liệu về định dạng hoặc thang đo nhất quán để các bộ dữ liệu khác nhau có thể được so sánh và phân tích chính xác cùng nhau.
Điều này có thể bao gồm việc chuẩn hóa các giá trị xét nghiệm về cùng đơn vị hoặc mã hóa các biến phân loại một cách thống nhất.
Giai đoạn này rất quan trọng vì hiệu quả của mô hình AI phụ thuộc rất nhiều vào chất lượng dữ liệu đầu vào.
Đây là khái niệm thường được nhấn mạnh qua cụm từ “rác vào, rác ra”.
Nếu dữ liệu đầu vào bị lỗi hoặc không nhất quán, các dự đoán của mô hình sẽ không đáng tin cậy.
Ví dụ: Tại Mayo Clinic, quá trình chuẩn hóa dữ liệu cho hệ thống AI chẩn đoán ung thư da đã phát hiện ra 23% kết quả sinh thiết bị ghi nhầm đơn vị đo (mm thay vì cm), 15% hình ảnh bị lỗi độ phân giải, và 8% bản ghi bệnh nhân bị trùng lặp. Sau khi làm sạch, độ chính xác của mô hình tăng từ 72% lên 94%.
Huấn luyện và thẩm định mô hình
Với dữ liệu sạch và được chuẩn hóa trong tay, các nhà phát triển tiến hành huấn luyện mô hình AI.
Quá trình huấn luyện bao gồm dạy thuật toán nhận diện các mô hình và mối quan hệ trong dữ liệu liên quan đến kết quả điều trị.
Thông thường, bộ dữ liệu được chia thành ba phần:
- Tập huấn luyện dùng để dạy mô hình.
- Tập kiểm định để tinh chỉnh tham số và tránh overfitting.
- Tập kiểm tra chứa dữ liệu mới, chưa từng thấy để đánh giá mức độ tổng quát hóa của mô hình ngoài những gì nó đã học.
Trong quá trình huấn luyện, mô hình liên tục điều chỉnh các tham số nội bộ để giảm thiểu sai số giữa dự đoán của nó và kết quả đã biết.
Bước kiểm định giúp đảm bảo mô hình không chỉ ghi nhớ dữ liệu huấn luyện mà nắm bắt được xu hướng cơ bản áp dụng cho các trường hợp tương lai.
Bước cuối cùng trên tập kiểm tra là đánh giá hiệu suất và độ chính xác trong thế giới thực.
Chỉ khi mô hình đạt được kết quả thỏa đáng trên tất cả các tập này, nó mới tiến tới ứng dụng lâm sàng.
Ví dụ: Google DeepMind đã huấn luyện mô hình dự đoán suy thận cấp tính sử dụng dữ liệu từ 700.000 bệnh nhân. Tập huấn luyện (70%) chứa 490.000 trường hợp, tập kiểm định (15%) có 105.000 trường hợp, và tập kiểm tra (15%) gồm 105.000 trường hợp hoàn toàn mới.
Mô hình cuối cùng đạt độ chính xác 92% trong việc dự báo suy thận 48 giờ trước khi xảy ra.
Tạo khuyến nghị và hỗ trợ quyết định
Sau khi huấn luyện và kiểm định thành công, hệ thống AI đã sẵn sàng để sử dụng thực tế.
Khi dữ liệu bệnh nhân mới được đưa vào mô hình, nó phân tích thông tin này và tạo ra đầu ra có thể hướng dẫn các quyết định lâm sàng.
Những đầu ra này có thể bao gồm
- Dự đoán tiên lượng về tiến triển bệnh.
- Gợi ý về thuốc có khả năng hiệu quả nhất dựa trên yếu tố di truyền và lâm sàng.
- Liều lượng khuyến nghị được điều chỉnh để giảm thiểu tác dụng phụ.
- Cảnh báo về phản ứng có hại tiềm tàng.
Thông qua cung cấp thông tin chi tiết dựa trên bằng chứng cụ thể cho hồ sơ độc đáo của từng bệnh nhân, AI hoạt động như một công cụ hỗ trợ quyết định bổ sung cho chuyên môn của các chuyên gia chăm sóc sức khỏe thay vì thay thế họ.
Điều này giúp bác sĩ đưa ra lựa chọn điều trị sáng suốt hơn phù hợp với các nguyên tắc y học chính xác.
Hệ thống CDSS (Clinical Decision Support System) tại Johns Hopkins phân tích dữ liệu bệnh nhân trong 3 phút và đưa ra 5 khuyến nghị cụ thể:
- Thuốc tối ưu dựa trên profile di truyền (99.2% trường hợp chính xác)
- Liều lượng cá nhân hóa giảm 40% tác dụng phụ so với liều chuẩn
- Cảnh báo tương tác thuốc (phát hiện 95% trường hợp nguy hiểm)
- Dự đoán thời gian nằm viện với sai số chỉ ±0.8 ngày
- Gợi ý theo dõi xét nghiệm phù hợp với từng giai đoạn điều trị

Giám sát và vòng lặp phản hồi
Công việc không kết thúc khi các khuyến nghị được đưa ra.
Một trong những đặc điểm xác định của hệ thống AI tiên tiến trong chăm sóc sức khỏe là khả năng học liên tục thông qua các vòng lặp phản hồi.
Khi bệnh nhân trải qua điều trị dựa trên kế hoạch do AI tạo ra thì tác dụng tích cực, tác dụng phụ, biến chứng được theo dõi chặt chẽ và đưa trở lại hệ thống.
Thu thập liên tục dữ liệu kết quả này giúp mô hình AI tự tinh chỉnh theo thời gian.
Vòng lặp phản hồi đảm bảo AI thích ứng với thông tin mới, cải thiện độ chính xác dự đoán và hiệu quả điều trị với mỗi lần lặp lại.
Nó cũng giúp xác định các mô hình bất ngờ hoặc xu hướng mới nổi có thể thông tin cho các chiến lược chăm sóc tương lai.
Thông qua học từ kết quả thế giới thực một cách liên tục, các kế hoạch điều trị cá nhân hóa hỗ trợ AI trở nên thông minh hơn, đáng tin cậy hơn và phù hợp hơn với nhu cầu đang phát triển của bệnh nhân.
Hệ thống AI của Tempus đã theo dõi 50.000 bệnh nhân ung thư trong 2 năm.
Mỗi tuần, hệ thống nhận được:
- 12.000 báo cáo tác dụng phụ từ bệnh nhân qua app
- 8.500 kết quả xét nghiệm mới từ phòng lab
- 3.200 đánh giá hiệu quả điều trị từ bác sĩ
- 1.800 hình ảnh chụp kiểm tra tiến triển
Dữ liệu này được tự động phân tích và cập nhật vào mô hình.
Kết quả là độ chính xác dự đoán đáp ứng điều trị tăng từ 68% ban đầu lên 89% sau 24 tháng.
Từ đó thời gian phát hiện kháng thuốc giảm từ 8 tuần xuống còn 3 tuần.

Các nghiên cứu điển hình
| Lĩnh vực/Bệnh | Nhiệm vụ | Mô hình AI | Dữ liệu đầu vào | Kết quả (AUROC, Độ chính xác, Độ nhạy, Độ đặc hiệu) |
|---|---|---|---|---|
| Ung thư TKTW (Nhi) | Phân loại u hố sau | Mạng Nơ-ron (Neural Network) | 816 ảnh MRI | AUROC: 0.99, Độ chính xác: 92%, Độ nhạy: 96%, Độ đặc hiệu: 100% |
| Ung thư TKTW (Nhi) | Phân loại phân nhóm u nguyên tủy bào | Máy vector hỗ trợ (SVM) | Dữ liệu MRI | AUROC: 0.79 (phân nhóm SHH), 0.70 (Group 3), 0.83 (Group 4) |
| Ung thư xương (Nhi) | Dự đoán hoại tử khối u | Rừng ngẫu nhiên (Random Forest) | Ảnh giải phẫu bệnh | AUROC: 0.90, Độ nhạy: 94%, Độ đặc hiệu: 78% |
| Ung thư xương (Nhi) | Dự đoán hoại tử khối u | SVM và Học sâu (Deep Learning) | Ảnh giải phẫu bệnh | AUROC: 0.99 (cho cả hai mô hình) |
| Ung thư vú | Dự đoán tiên lượng | Rừng ngẫu nhiên + Mạng Nơ-ron | Dữ liệu gen | Dự đoán Sống còn Toàn bộ (OS) và Sống còn không bệnh (DFS) |
| Ung thư cổ tử cung | Dự đoán đáp ứng hóa trị | Máy vector hỗ trợ (SVM) | Dữ liệu Radiomics (trích xuất từ ảnh) | Phân loại bệnh nhân “đáp ứng” và “không đáp ứng” |
| Ung thư vú | Chẩn đoán qua chụp nhũ ảnh | AI của Lunit | Ảnh chụp nhũ ảnh | Độ chính xác: 96% |

Các vấn đề đạo đức và pháp lý
| Vấn đề | Bệnh nhân | Bác sĩ & Cơ sở Y tế | Nhà phát triển AI | Cơ quan Quản lý |
|---|---|---|---|---|
| Thiên kiến Thuật toán |
Rủi ro:
Nhận chẩn đoán/điều trị kém chính xác, làm trầm trọng thêm bất bình đẳng sẵn có.
Giải pháp:
Nâng cao nhận thức, tham gia vào các chương trình thu thập dữ liệu đa dạng để tăng tính đại diện.
|
Rủi ro:
Đưa ra quyết định lâm sàng sai lầm dựa trên khuyến nghị thiên vị, giảm chất lượng chăm sóc cho một số nhóm bệnh nhân.
Giải pháp:
Được đào tạo để nhận biết các hạn chế của AI, yêu cầu nhà cung cấp cung cấp bằng chứng về thẩm định thiên kiến.
|
Rủi ro:
Tạo ra sản phẩm gây hại, dẫn đến tổn thất tài chính và danh tiếng.
Giải pháp:
Xây dựng các bộ dữ liệu đa dạng và đại diện, sử dụng các kỹ thuật giảm thiểu thiên kiến, thực hiện kiểm toán công bằng định kỳ.
|
Rủi ro:
Bất bình đẳng y tế trong xã hội gia tăng.
Giải pháp:
Ban hành quy định yêu cầu kiểm toán thiên kiến đối với các thiết bị y tế AI, khuyến khích các sáng kiến xây dựng bộ dữ liệu mở, đại diện cho toàn dân.
|
| Trách nhiệm pháp lý |
Rủi ro:
Gặp khó khăn trong việc được bồi thường thỏa đáng khi có sai sót do AI gây ra.
Giải pháp:
Vận động hành lang cho các cơ chế bồi thường không cần xác định lỗi (no-fault compensation funds) để đảm bảo quyền lợi.
|
Rủi ro:
Trở thành đối tượng bị kiện vì lỗi của một công cụ AI mà họ sử dụng.
Giải pháp:
Luôn tuân thủ tiêu chuẩn chăm sóc, coi AI là công cụ tham khảo chứ không phải quyết định cuối cùng, yêu cầu hợp đồng phân định trách nhiệm rõ ràng với nhà cung cấp.
|
Rủi ro:
Trở thành đối tượng chính của các vụ kiện về sản phẩm lỗi, kìm hãm sự đổi mới.
Giải pháp:
Mua bảo hiểm trách nhiệm sản phẩm đầy đủ, thiết kế AI với các cơ chế an toàn và ghi lại nhật ký quyết định để truy vết.
|
Rủi ro:
Môi trường pháp lý không rõ ràng gây cản trở đổi mới và đầu tư.
Giải pháp:
Xây dựng một khung pháp lý rõ ràng, linh hoạt để phân chia trách nhiệm một cách hợp lý giữa các bên liên quan (bác sĩ, bệnh viện, nhà phát triển).
|
| Quyền riêng tư & Bảo mật |
Rủi ro:
Dữ liệu sức khỏe nhạy cảm bị rò rỉ, bị lạm dụng cho các mục đích thương mại hoặc phân biệt đối xử.
Giải pháp:
Yêu cầu sự minh bạch hoàn toàn về cách dữ liệu được sử dụng, có quyền kiểm soát và thu hồi sự đồng thuận.
|
Rủi ro:
Vi phạm các quy định bảo vệ dữ liệu (như HIPAA), đối mặt với các khoản phạt nặng và mất niềm tin của bệnh nhân.
Giải pháp:
Áp dụng các biện pháp bảo mật mạnh mẽ nhất (mã hóa, kiểm soát truy cập nghiêm ngặt), tuân thủ nghiêm ngặt các quy định pháp luật.
|
Rủi ro:
Hệ thống bị tấn công mạng, gây ra các vụ vi phạm dữ liệu quy mô lớn.
Giải pháp:
Áp dụng các nguyên tắc “quyền riêng tư ngay từ khi thiết kế” (privacy by design), khám phá các công nghệ như học liên kết (federated learning) để huấn luyện mô hình mà không cần di chuyển dữ liệu.
|
Rủi ro:
Các quy định pháp luật hiện hành không theo kịp tốc độ phát triển của công nghệ.
Giải pháp:
Cập nhật các luật bảo vệ dữ liệu để bao quát các kịch bản đặc thù của AI, ban hành các tiêu chuẩn bảo mật bắt buộc cho các hệ thống AI trong y tế.
|
| Tính Minh bạch (“Hộp đen”) |
Rủi ro:
Không hiểu tại sao mình lại được chỉ định một phác đồ điều trị cụ thể, làm giảm sự tin tưởng và tuân thủ.
Giải pháp:
Yêu cầu bác sĩ giải thích một cách rõ ràng cơ sở lý luận đằng sau các quyết định điều trị có sự hỗ trợ của AI.
|
Rủi ro:
Không thể thẩm định hoặc tin tưởng một khuyến nghị từ AI, không dám áp dụng vào thực tế.
Giải pháp:
Ưu tiên lựa chọn và sử dụng các hệ thống AI có khả năng giải thích (Explainable AI – XAI), yêu cầu nhà cung cấp cung cấp tài liệu chi tiết về mô hình.
|
Rủi ro:
Sản phẩm không được thị trường chấp nhận do thiếu sự tin tưởng từ người dùng cuối (bác sĩ).
Giải pháp:
Đầu tư mạnh mẽ vào nghiên cứu và phát triển các kỹ thuật XAI để làm cho các mô hình trở nên minh bạch và dễ hiểu hơn.
|
Rủi ro:
Các công cụ không an toàn, không được thẩm định kỹ lưỡng được cấp phép lưu hành.
Giải pháp:
Yêu cầu một mức độ minh bạch và khả năng giải thích nhất định như một phần của quy trình phê duyệt và quản lý thiết bị y tế.
|
Có thể bạn quan tâm











Liên hệ

Địa chỉ
Tầng 3 Toà nhà VNCC
243A Đê La Thành Str
Q. Đống Đa-TP. Hà Nội


info@comlink.com.vn

Phone
+84 98 58 58 247